Lab_06: 데이터 시각화하기
개요
여기서는 R로 데이터사이언스를 하는 과정 중 데이터 시각화하기(visualizing)를 다룬다. 그림 1 에 나타나 있는 것처럼, 시각화하기는 데이터사이언스 프로세스 중 핵심적인 분석 부분의 구성요소이다. 데이터 변형과 데이터 시각화를 합쳐 데이터 탐색이라 부르기도 한다.
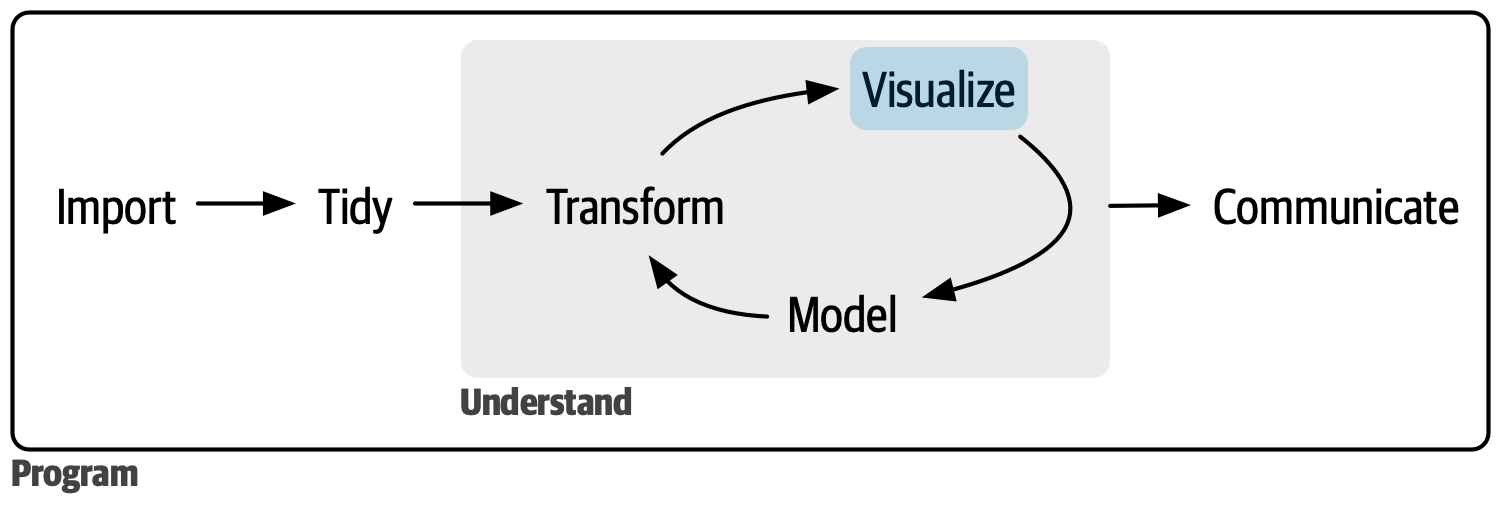
데이터 시각화하기는 tidyverse의 핵심 패키지 중의 하나인 ggplot2 에서 제공된다. ggplot2의 gg가 ’그래프의 문법(grammar of graphic)’을 의미하는 것에서 알 수 있는 것처럼, ggplot2는 그래프 제작의 일반 원리를 정교하게 구현하기 위해 만들어졌다. 그림 2 에서 보는 것처럼, 모든 그래프는 8개의 주요 구성 요소로 이루어져 있고, ggplot2는 각각의 구성 요소를 마치 레이어(layer)를 쌓는 것과 같은 방식으로 구현한다(+ 연산자, 즉 레이어 추가 연산자 사용).

우선 tidyverse 패키지를 불러온다.
실습을 위해 ggplot2 패키지 속에 포함되어 있는 mpg 데이터와 diamonds 데이터를 사용한다. mpg 데이터의 11개 변수 중 다음의 세 가지 변수가 특히 중요한데, displ는 자동차의 엔진 크기이고, hwy는 고속도로 연비, class는 자동차의 유형이다. diamond 데이터는 총 54,000개의 다이아몬드에 대한 정보를 담고 있는데, 특히 가격(price) 캐럿(carat), 컬러(color), 투명도(clarity), 컷(cut)이 중요한 변수들이다.
1 핵심 구성 요소: 시각속성과 기하객체
이 8개 구성 요소 중 가장 중요한 것은 ’시각속성(aesthetics)’과 ’기하객체(geometric objects)’이다. 기하객체가 그래프의 전체 구조 혹은 형식을 규정하는 것이라면, 시각속성은 기하객체의 외견을 규정한다. 기하객체는 그래프의 유형(예: 막대 그래프, 산포도 등)과 관련되고, 시각속성은 플롯의 그래픽 속성(예: 컬러, 크기, 모양 등) 혹은 시각 변수(visual variable)과 관련된다. 이 두 가지는 독립적인 요소이지만, 어느 정도는 관련되어 있기도 하다. 특정한 기하객체는 오로지 특정한 시각속성과만 결합한다. 예를 들어 포인트 기하 객체(geom_point())는 크기(size) 시각속성과 관련되지만, 라인 기하객체(geom_line())는 크기 시각속성과는 관련되지 않고 라인폭(linewidth) 시각속성과만 관련되는 식이다.
1.1 시각속성
시각속성 매핑(aesthetic mapping)이란 특정한 시각속성 혹은 시각변수를 특정한 변수에 부여하는 과정을 의미한다. 이것을 통해 해당 변수의 변동(값의 다양성)을 효과적으로 나타낼 수 있다. 변수는 다양한 값으로 구성되어 있고, 그 값들이 보여주는 다양성을 시각적으로 드러내야 한다. 정성적 변수인 경우는 범주적 차이를 표현해야 하고, 정량적 변수인 경우는 수치적 차이를 표현해야 한다. 여기서 중요한 것은 어떤 시각속성은 정성적 변수와 관련되고, 다른 시각속성은 정량적 변수와 관련된다는 점이다. 시각속성은 aes() 함수를 통해 나타내며, ’시각속성 = 변수’의 형태로 지정된다. 당연히 여러 개의 시각속성이 동시에 사용될 수 있고, aes() 함수 내에서 콤마로 구분된다.
aes()는 두 곳에 지정할 수 있는데, 최상위 함수인 ggplot() 속에 지정하면 ‘글로벌’ 지정이, 특정한 geom_*() 속에 지정하면 ‘로컬’ 지정이 된다. 둘의 차이는 뒤에서 살펴본다. ggplot2 패키지가 제공하는 시각속성이 표 1 에 정리되어 있다.
| 분류 | 시각속성 | 설명 | 성격 |
|---|---|---|---|
| 컬러 관련 | aes(color = ) |
점/선의 컬러 지정 | 정성 > 정량 |
aes(fill = ) |
역/면의 필(컬러) 지정 | 정성 > 정량 | |
aes(alpha = ) |
점/선/역/면의 투명도 지정 | 정성 < 정량 | |
| 차이 표현 관련 | aes(size = ) |
점의 크기 지정 | 정량 |
aes(shape = ) |
점의 모양 지정 | 정성 | |
aes(linetype = ) |
선의 유형 지정 | 정성 | |
aes(linewidth = ) |
선의 크기 지정 | 정량 | |
| 위치 관련 | aes(x = ) |
x축 지정 | 정성/정량 |
aes(y = ) |
y축 지정 | 정성/정량 | |
| 그룹화 관련 | aes(group = ) |
데이터를 묶는 기준(그룹화 기준) 지정 | 정성 |
위치 관련 시각속성에 xmin, ymin, xmax, ymax, xend, yend 등도 있다. 그러나 이것은 변수와 관련되지 않고 도형의 위치나 크기를 정의하는 좌표 매핑용으로만 사용된다. aes() 속에서 정의되기 때문에 시각속성이라 할 수는 있으나, 엄밀한 의미에서는 일종의 매개변수에 해당한다.
동일한 기하객체의 시각화에서 시각속성의 선택이 어떤 영향을 미치는지를 살펴본다. 산점도 기하객체(geom_point())를 통해 displ과 hwy의 관계가 class에 따라 어떻게 달라지는지를 시각화한다. 다음의 두 그래프를 비교해 본다.
ggplot(mpg, aes(x = displ, y = hwy, color = class)) +
geom_point()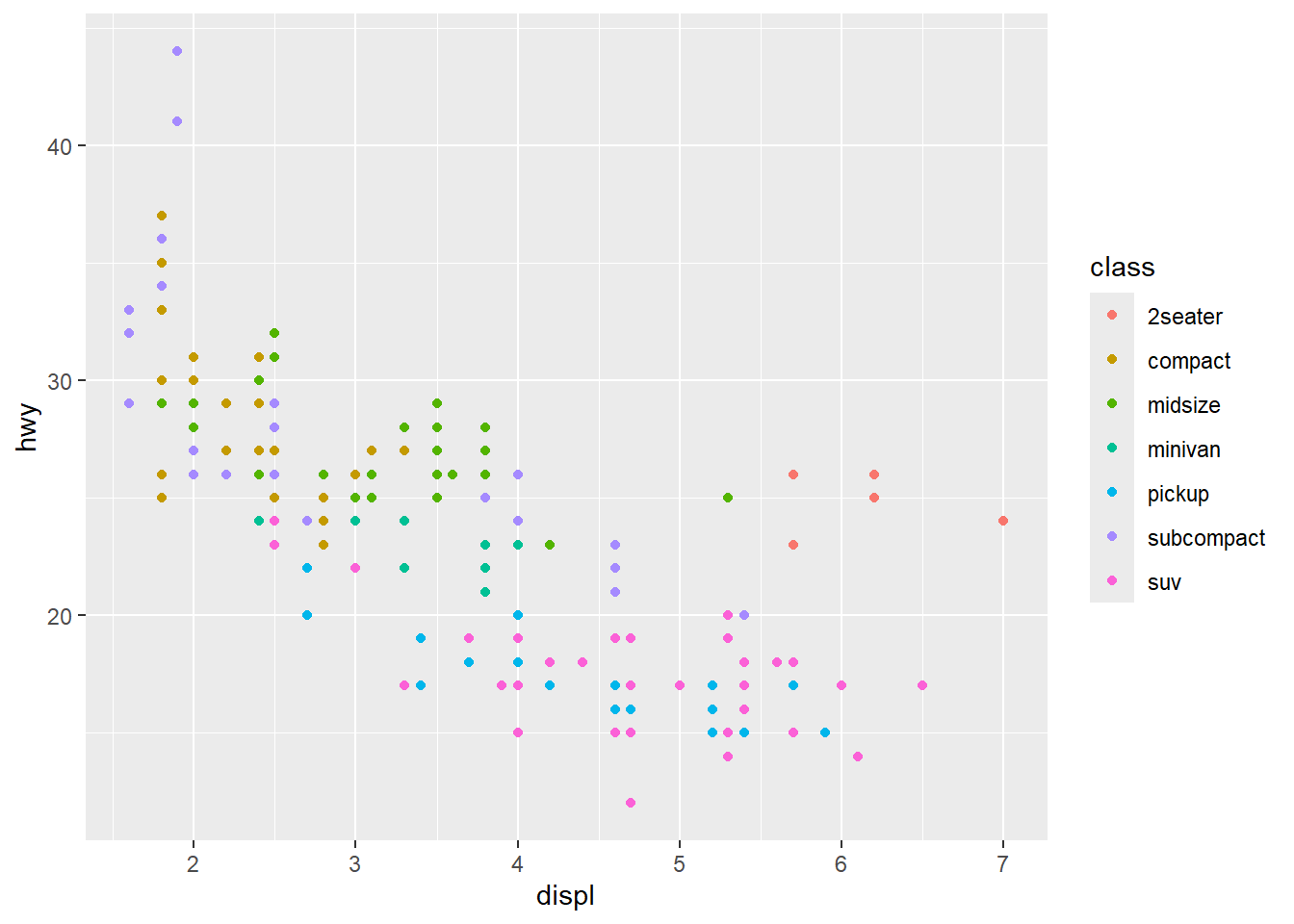
ggplot(mpg, aes(x = displ, y = hwy, shape = class)) +
geom_point()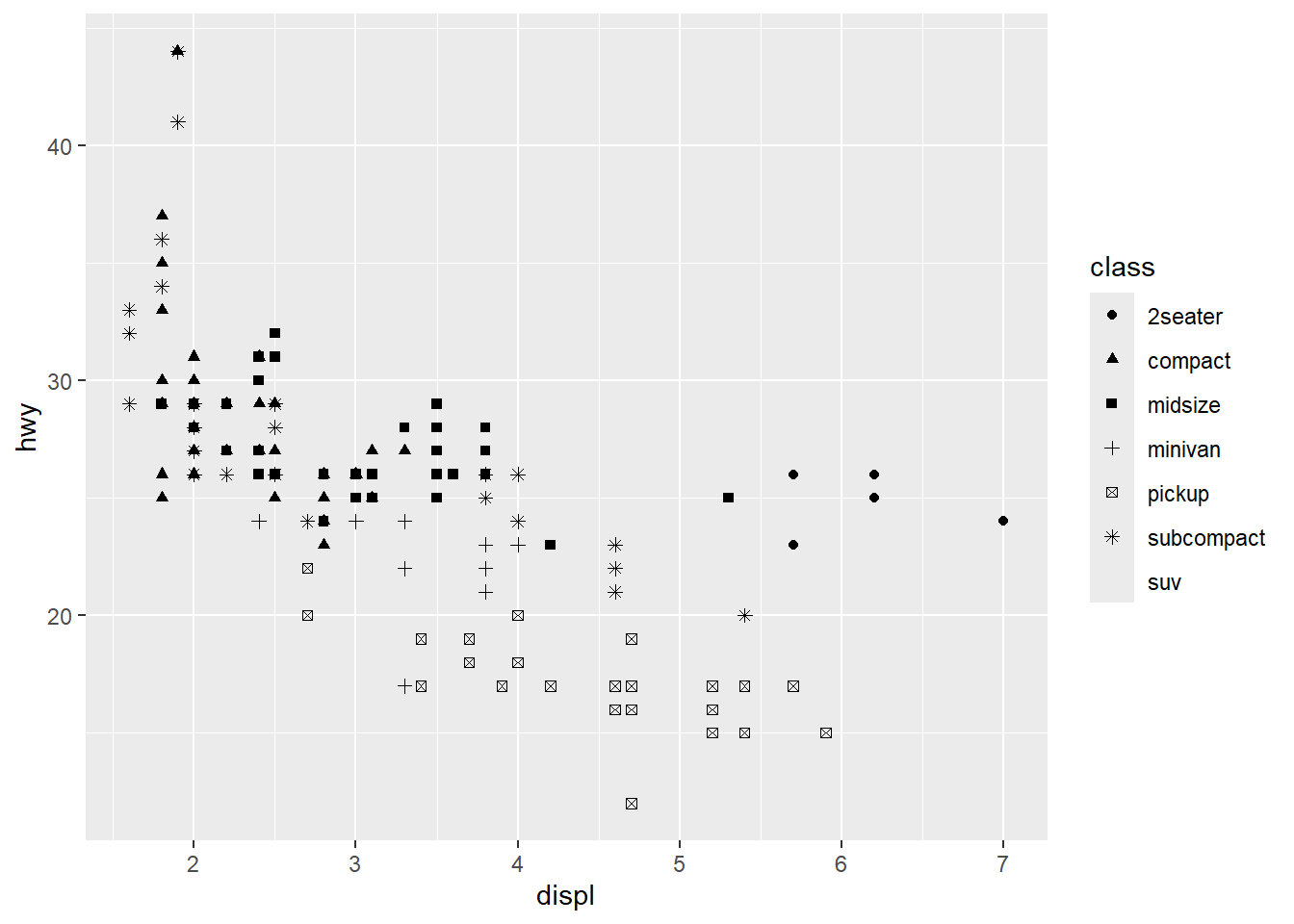
그림 3 과 그림 4 중 어느 것이 더 효과적이라고 판단하는가? 컬러(color)와 형태(shape)라는 시각속성 외에 크기(size)와 투명도(alpha) 속성을 동일한 데이터에 적용해 본다.
ggplot(mpg, aes(x = displ, y = hwy, size = class)) +
geom_point()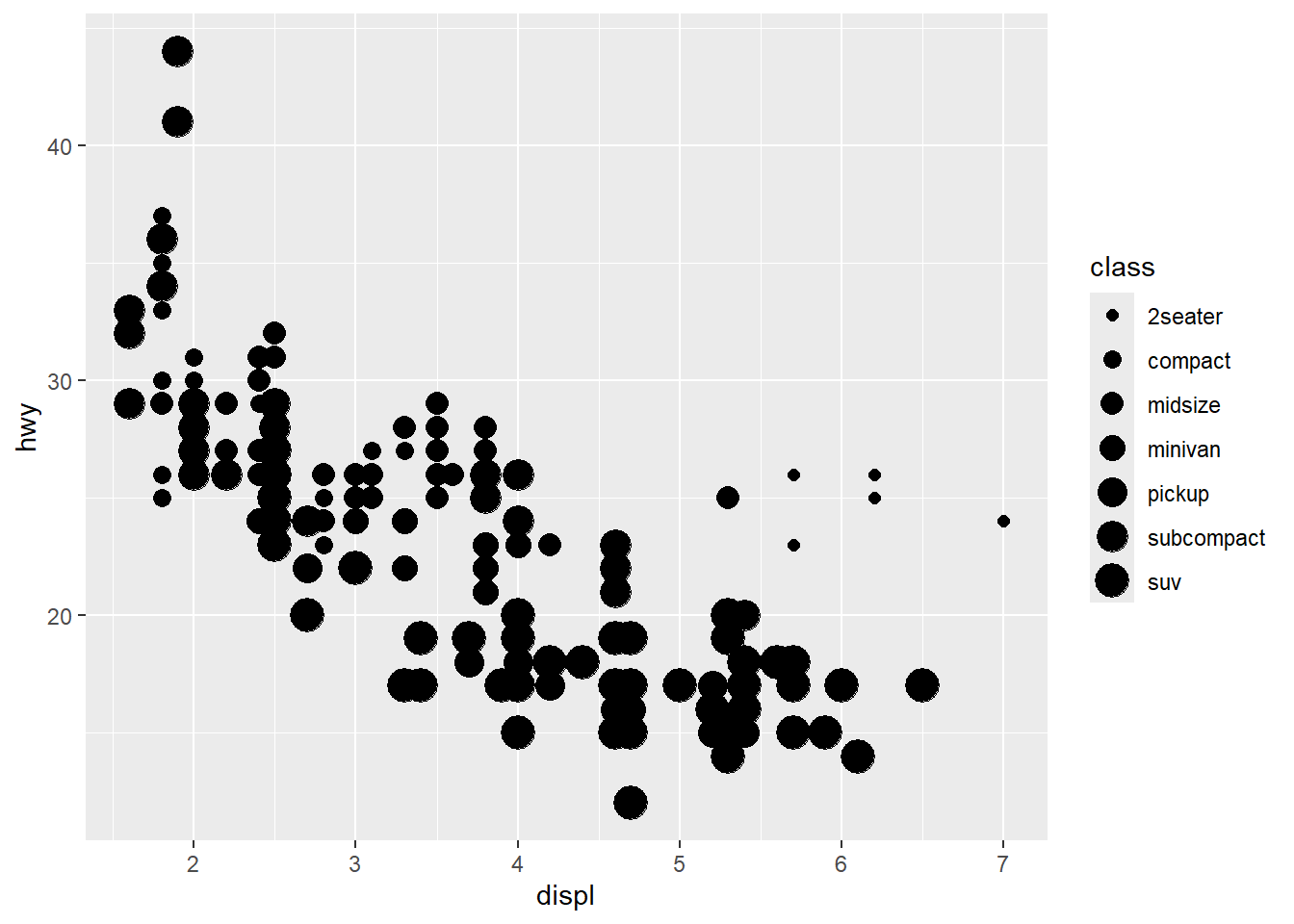
ggplot(mpg, aes(x = displ, y = hwy, alpha = class)) +
geom_point()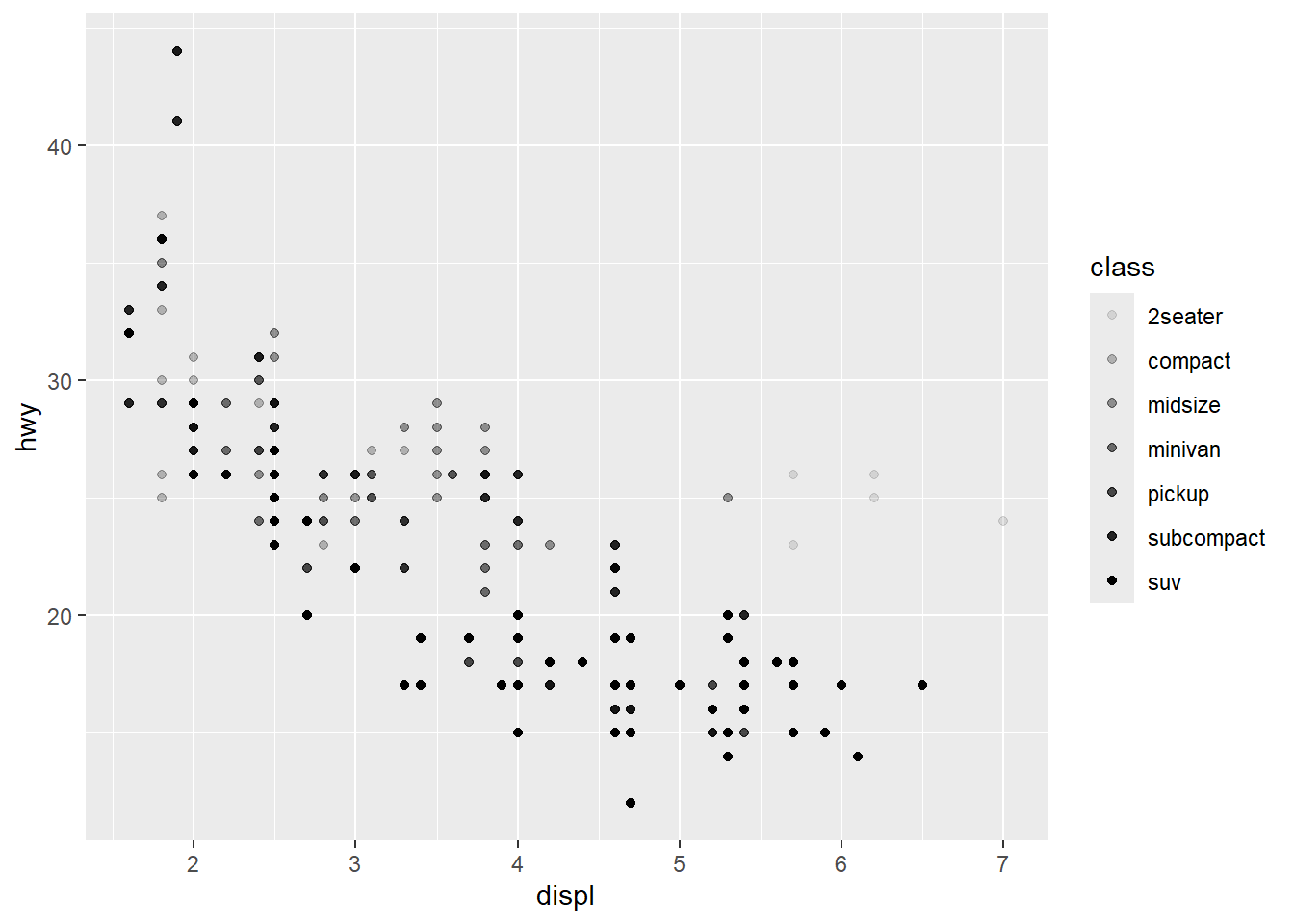
크기와 투명도는 정량적 차이를 나타내는데 적합한 시각속성이기 때문에 class라는 정성적 범주의 차이를 보여주는데는 적합하지 않다. 시각속성 부여에서 가장 중요한 것은 결국 해당 시각속성이 주어진 데이터에 얼마나 부합하느냐에 달려있다.
1.2 기하객체
기하객체는 그래프의 전체 구조 혹은 형식을 규정하며, 일반적으로 그래프의 유형으로 이해할 수 있다. ggplot2 패키지는 매우 다양한 형태의 기하객체를 제공하며, geom_*() 함수의 형태를 띤다. geom_*() 함수 속에 aes()를 지정할 수 있다(로컬 지정). ggplot2 패키지가 제공하는 기하객체가 표 2 에 정리되어 있다. 가장 빈번하게 사용되는 기하객체에 geom_point(), geom_line(), geom_bar(), geom_boxplot(), geom_histogram(), geom_smooth(), geom_text(), geom_abline() 등이 있다.
| 구분 | 내용 | 기하객체 | 이름 |
|---|---|---|---|
| 기본 플롯 | 점 |
점플롯(산점도) 지터플롯 카운트플롯 |
|
| 선 |
선플롯(선그래프) 경로플롯 계단플롯 |
||
| 역 |
면적플롯 리본플롯 |
||
| 막대 | 막대플롯 | ||
| 통계 플롯 | 분포 |
박스플롯 밀도플롯 도트플롯 히스토그램 빈도다각선플롯 바이올린플롯 러그플롯 Q-Q선플롯 Q-Q선플롯 |
|
| 불확실성 |
십자막대플롯 세로오차막대플롯 가로오차막대플롯 선구간플롯 점선구간플롯 |
||
| 추세선 |
분위수회귀플롯 평활곡선플롯 |
||
| 도형 표현 | 폴리곤 | geom_polygon() |
다각형플롯 |
| 선 |
선분플롯 곡선플롯 스포크플롯 |
||
| 2D 플롯 | 빈도 | geom_bin_2d() |
2차원빈플롯 |
| 밀도 |
2차원밀도등고선플롯 채워진2차원밀도등고선플롯 |
||
| 등고선 |
등고선플롯 채워진등고선플롯 |
||
| 직사각형 |
래스터플롯 직사각형플롯 타일플롯 |
||
| 육각형 | geom_hex() |
헥스빈플롯 | |
| 기타 | 라벨링 |
라벨플롯 텍스트플롯 |
|
| 참조선 |
직선플롯 수평선플롯 수직선플롯 |
||
| 지도 제작 |
지도플롯 sf플롯 sf라벨플롯 sf텍스트플롯 |
그림 7 와 그림 8 이 다르게 보이는 것은 기하객체가 하나는 포인트(point)이고 다른 하나는 완만한 선(smooth)이기 때문이다.
ggplot(mpg, aes(x = displ, y = hwy)) +
geom_point()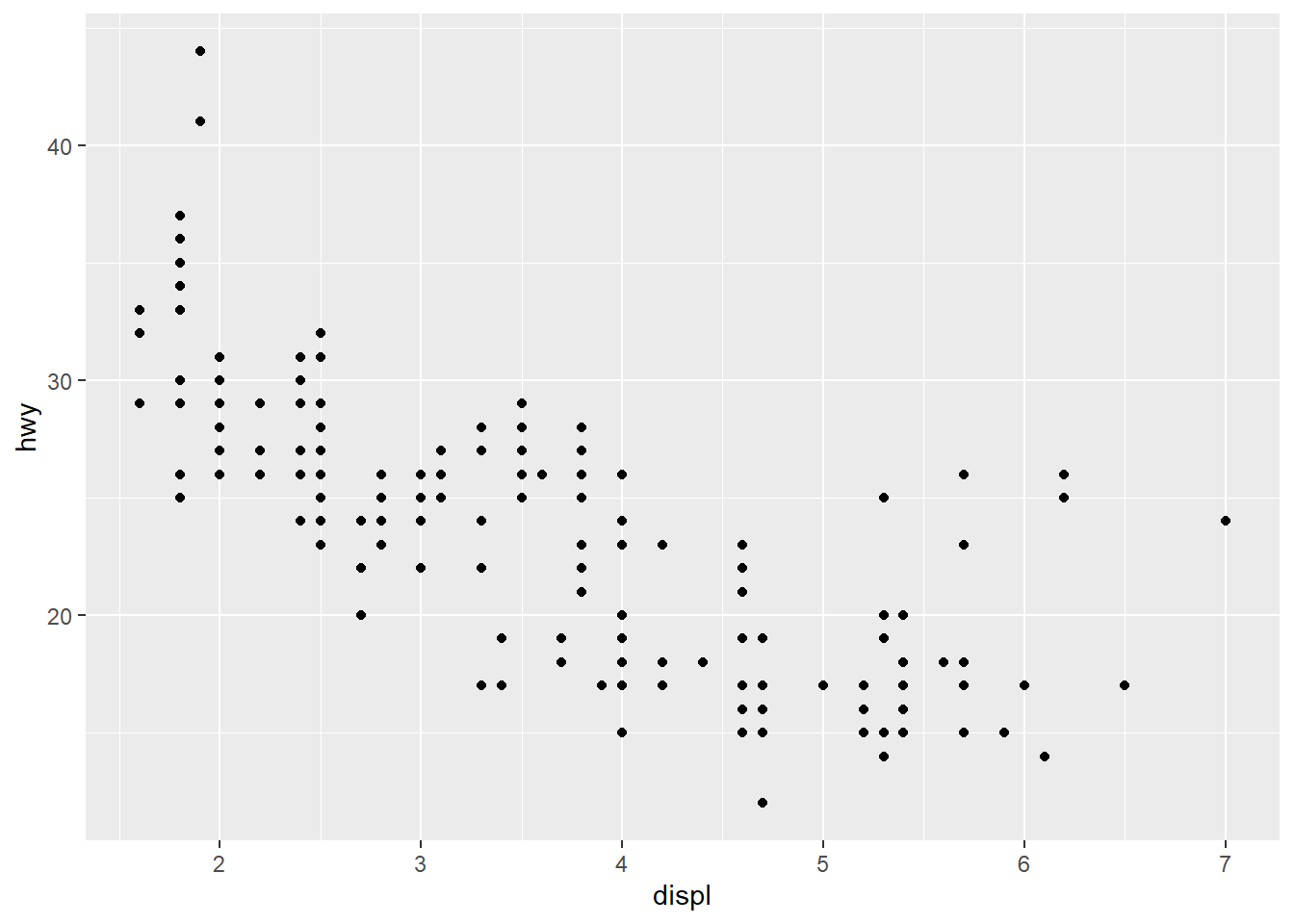
ggplot(mpg, aes(x = displ, y = hwy)) +
geom_smooth()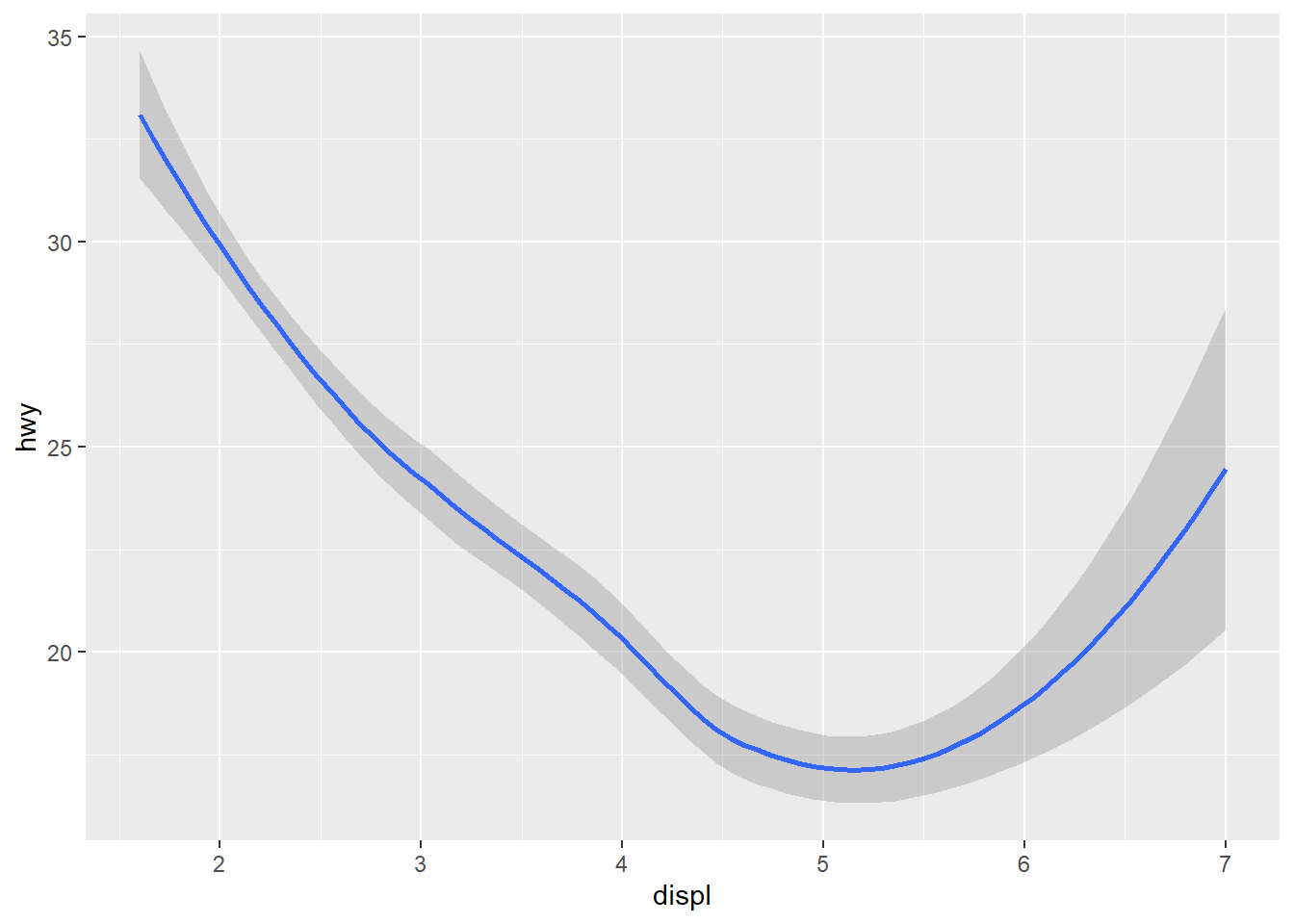
ggplot(mpg, aes(x = displ, y = hwy, color = class)) +
geom_point() +
geom_smooth()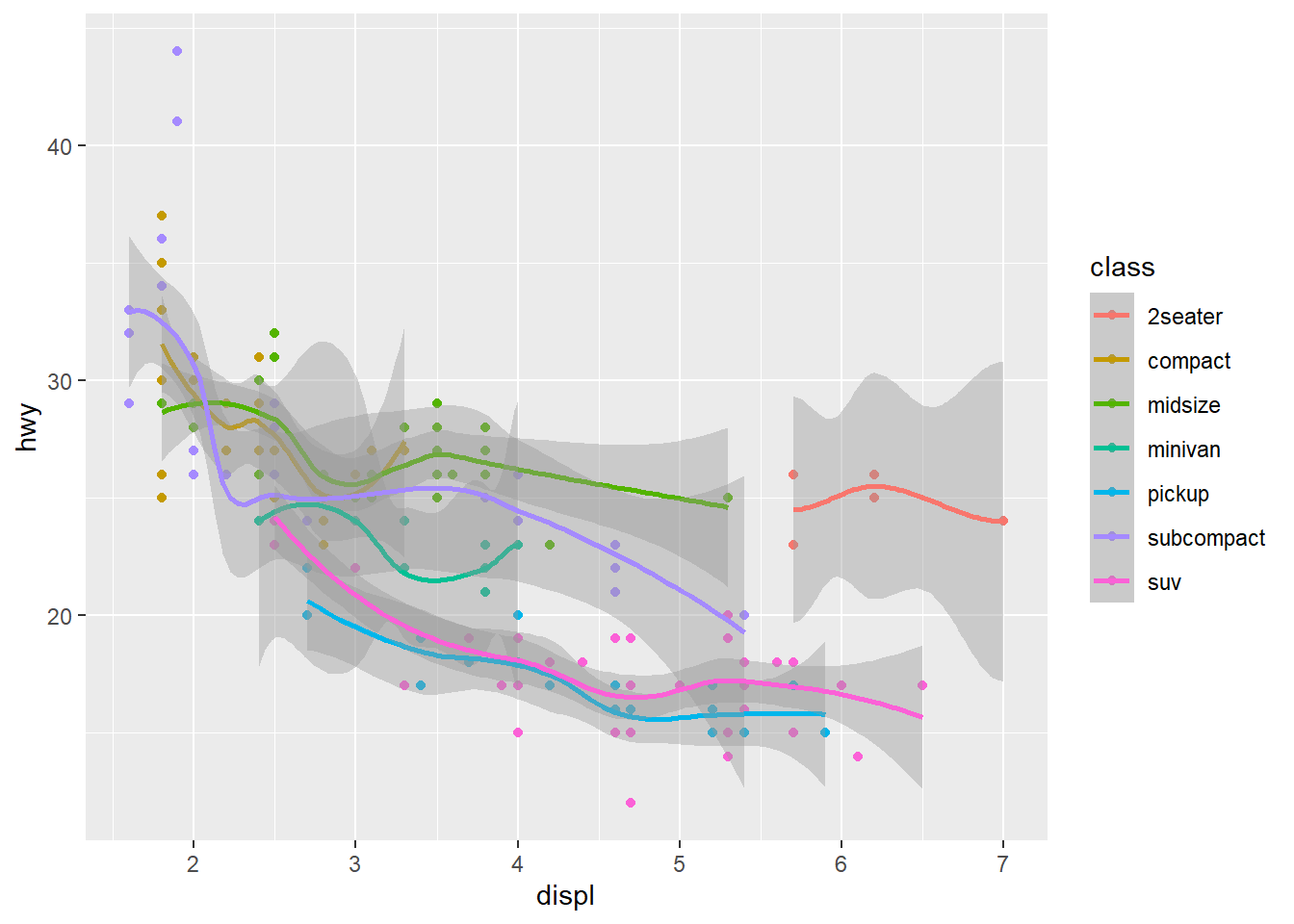
원하는 것이 아니다. 왜 이런 결과가 나왔으며, 어떻게 하면 원하는 것을 얻을 수 있을지 생각해 본다.
ggplot(mpg, aes(x = displ, y = hwy)) +
geom_point(aes(color = class)) +
geom_smooth()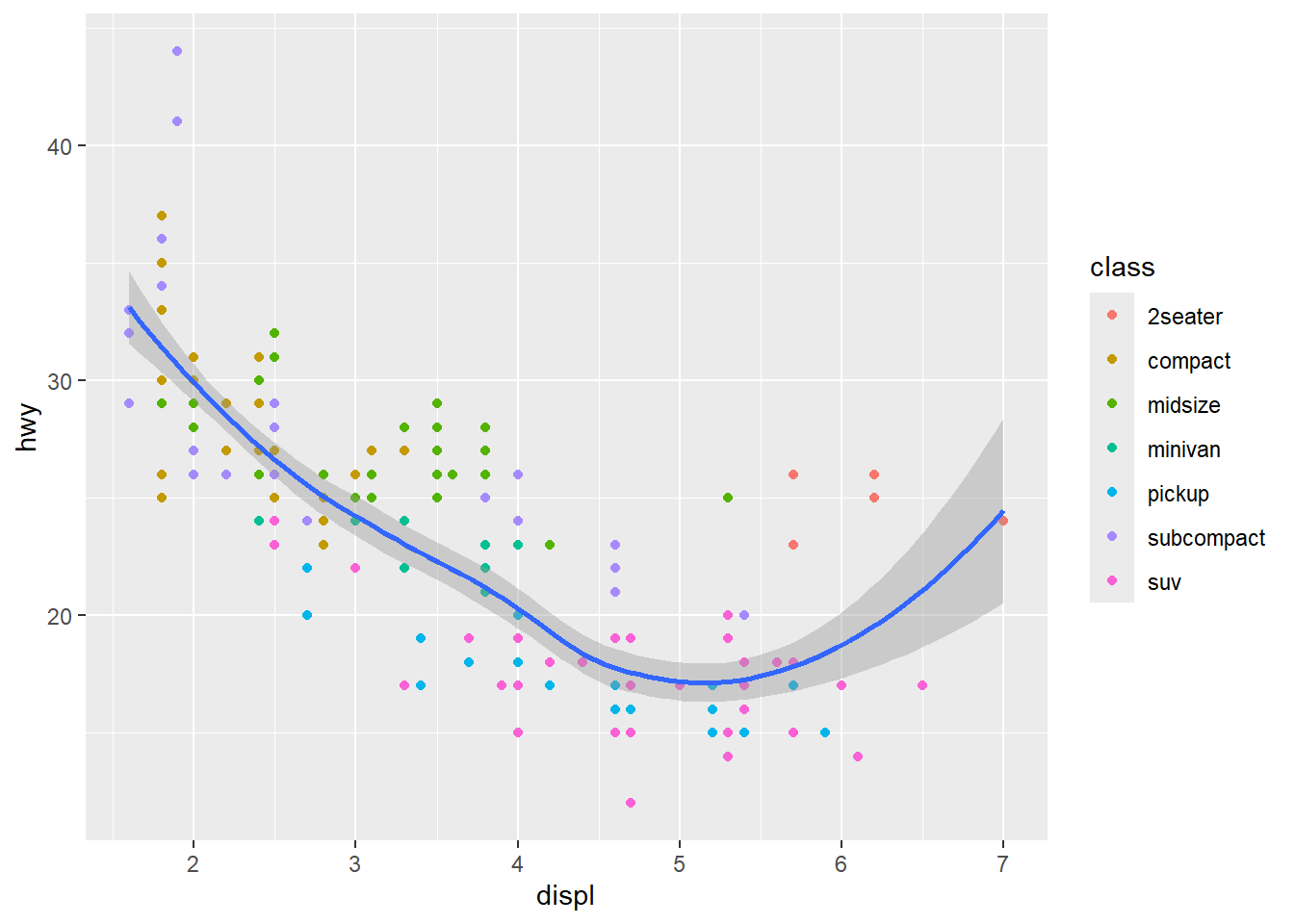
두 결과의 차이는 color 시각속성을 글로벌하게 적용하느냐 로컬하게 적용하느냐(포인트 기하객체에만 적용)에 달린 것이다. 글로벌 시각속성은 ggplot()속에서 지정하고, 로컬 시각속성은 개별 기하객체(geom_point()) 속에서 지정한다.
다양한 기하객체는 동일한 데이터를 다양한 방식으로 탐색할 수 있게 해준다. 다음의 세가지 기하객체는 탐색적 데이터 분석에서 널리 사용되는 것이다.
ggplot(mpg, aes(x = hwy)) +
geom_histogram(binwidth = 2)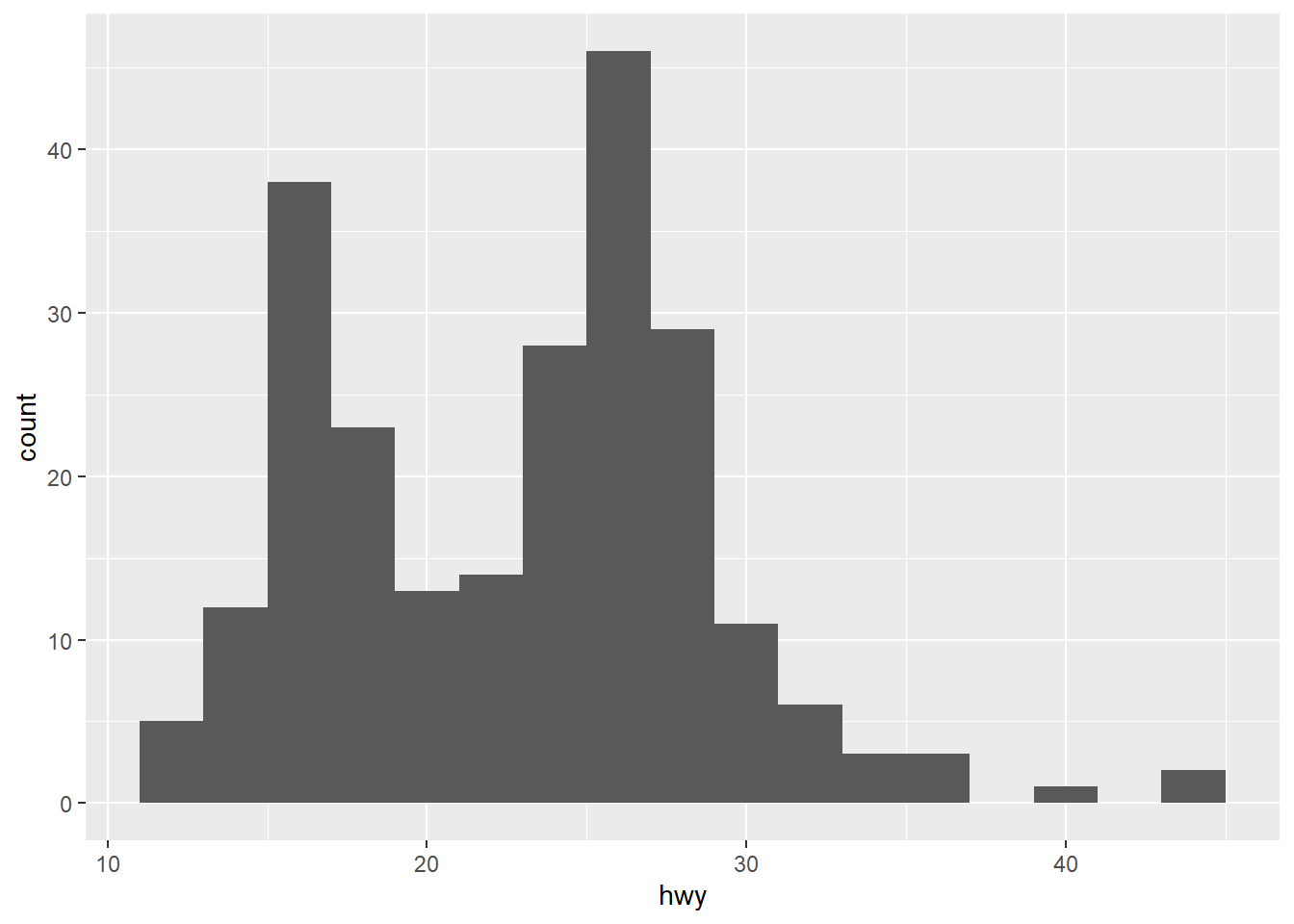
ggplot(mpg, aes(x = hwy)) +
geom_density()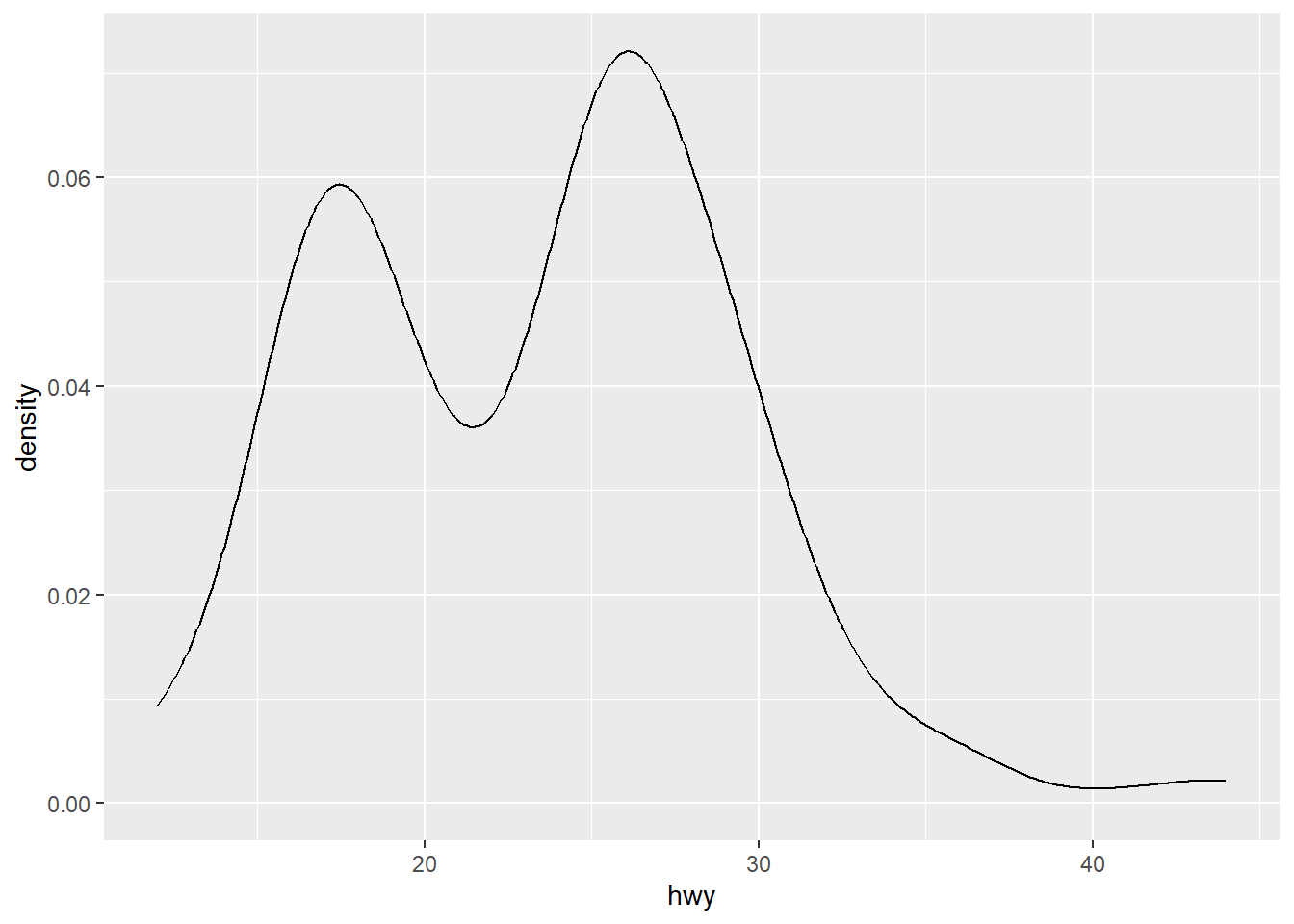
ggplot(mpg, aes(x = hwy)) +
geom_boxplot()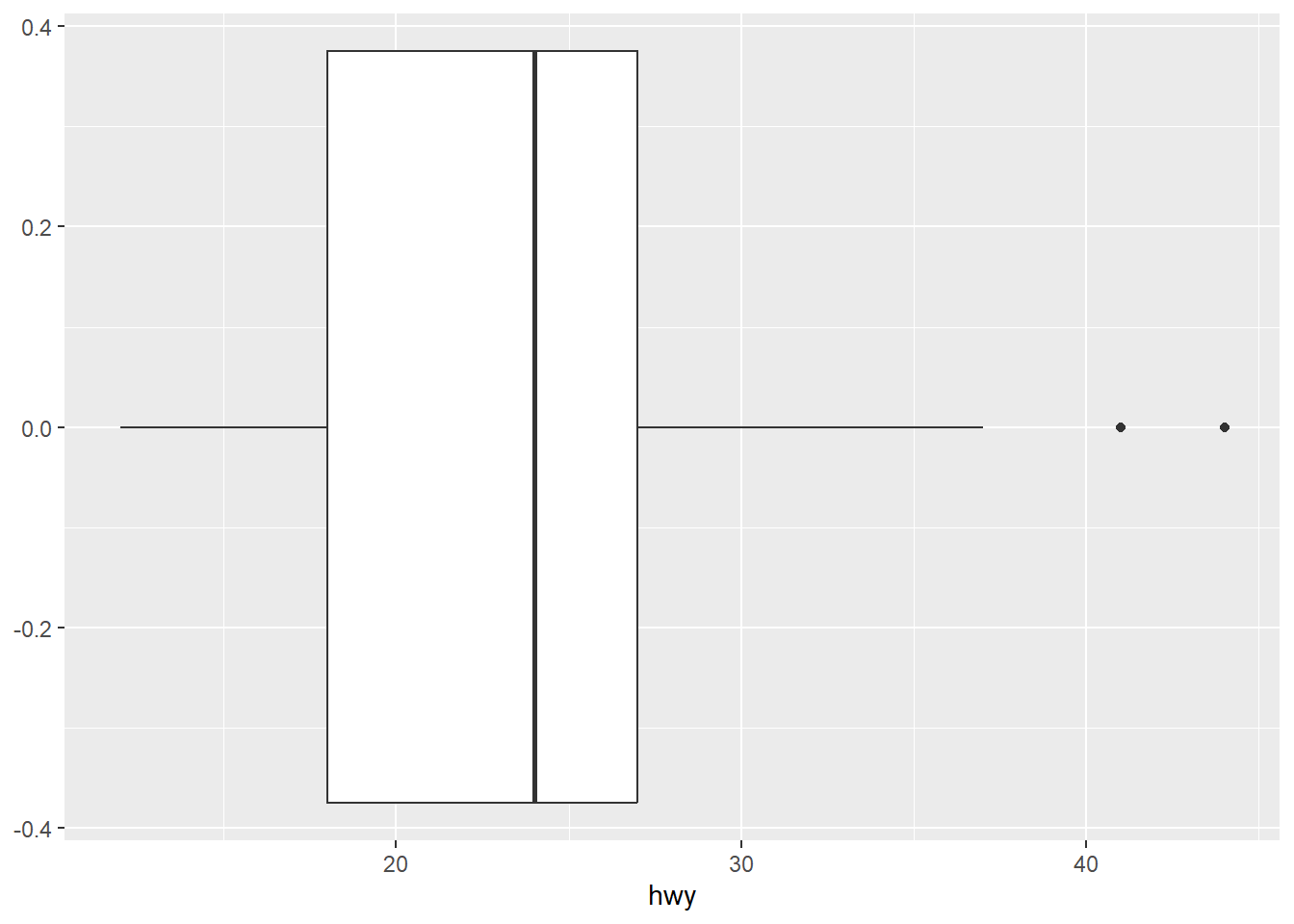
위와 같이 똑같은 데이터를 가지고 여러 시각화 자료를 만드는 경우, 공통되는 객체를 변수에 할당한 뒤 작업하면 작성해야 하는 코드의 양을 줄일 수 있다.
p + geom_density()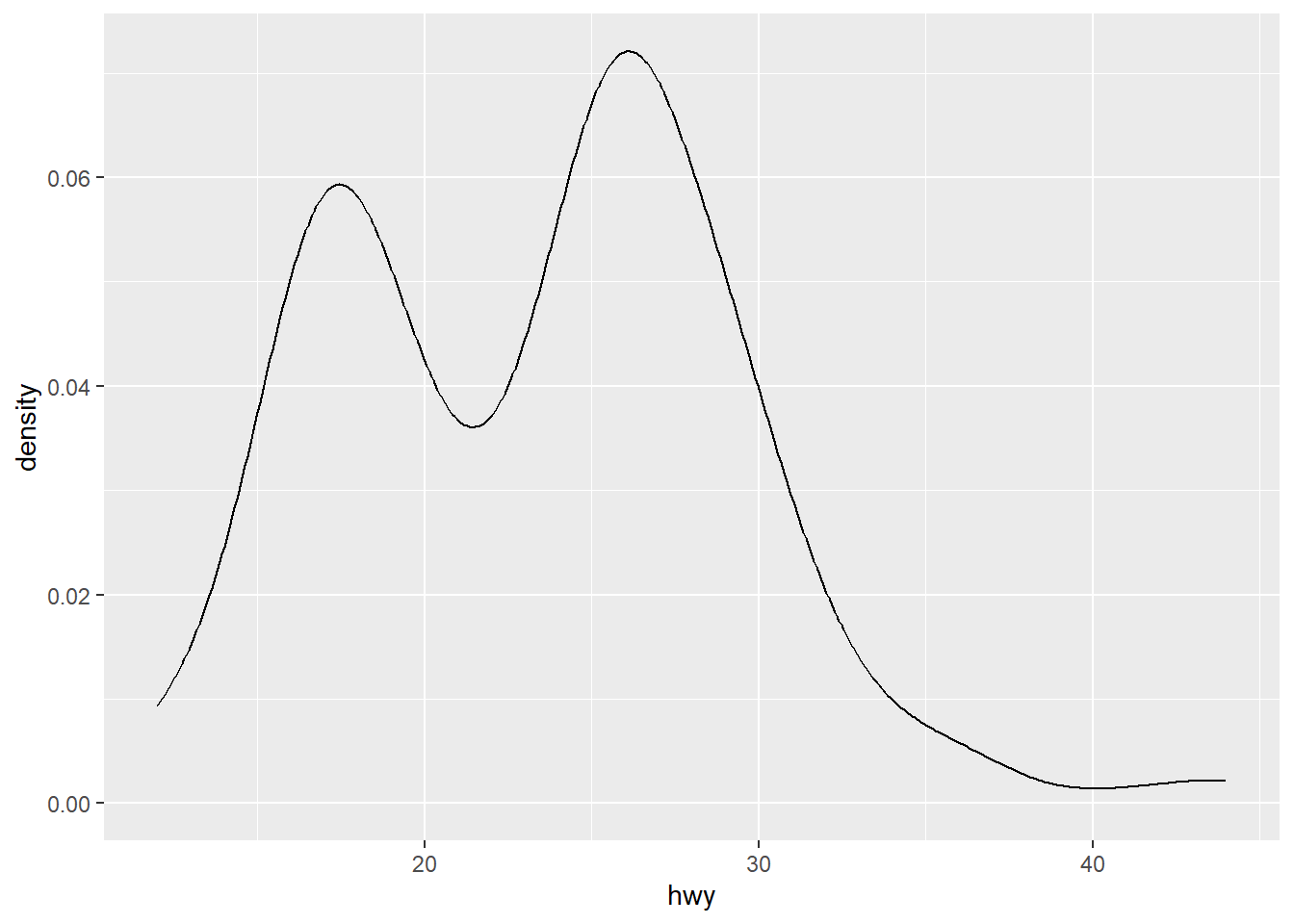
p + geom_boxplot()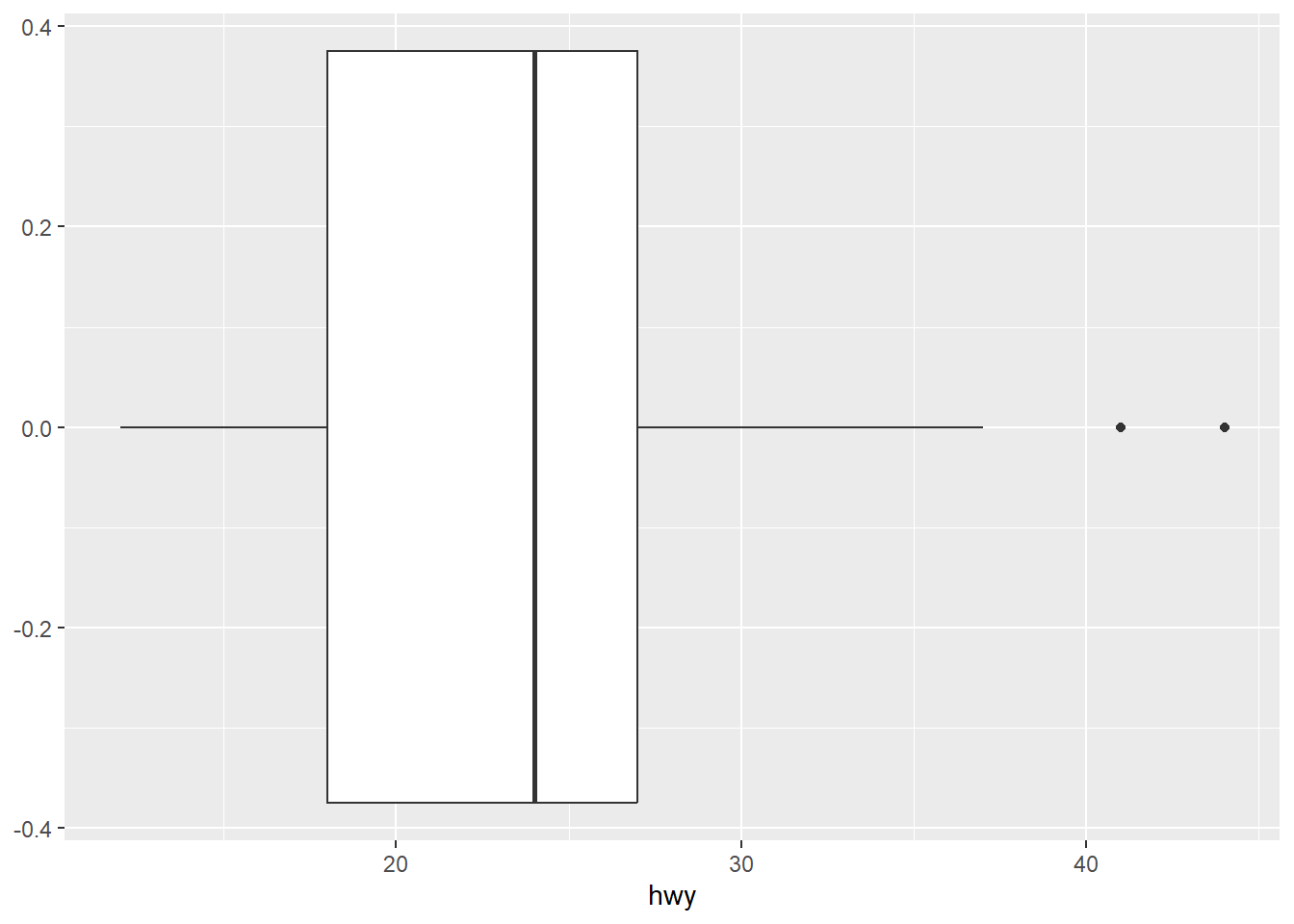
2 여타 구성 요소
2.1 데이터
데이터는 시각화의 가장 기본적인 요소로, 주로 최상위 함수인 ggplot() 속에서 data 인수로 지정된다. 그러나 개별 기하객체 속에서도 data 인수로 지정될 수 있다. 보통의 경우라면, ggplot() 함수나 특정한 geom_*() 함수 속에서 단일한 데이터 프레임이 한 번 지정되지만, 두 함수에 서로 다른 데이터 프레임이 지정될 수 있고, 또 다른 기하객체 속에 또 다른 데이터 프레임이 지정될 수도 있다.
예를 들어, 전체 데이터로 산점도를 그렸지만, 추세선은 class가 suv에 속하는 데이터에 대해서만 그리고 싶을 수도 있다. 이러한 경우, geom_*()에 ggplot()에 넣었던 데이터와 다른 데이터를 넣는 경우, 해당 geom_*() 레이어는 ggplot() 함수에 지정된 데이터를 따르지 않는다.
ggplot(mpg, aes(x = displ, y = hwy)) +
geom_point() +
geom_smooth(data = subset(mpg, class == "suv"),
color = "red")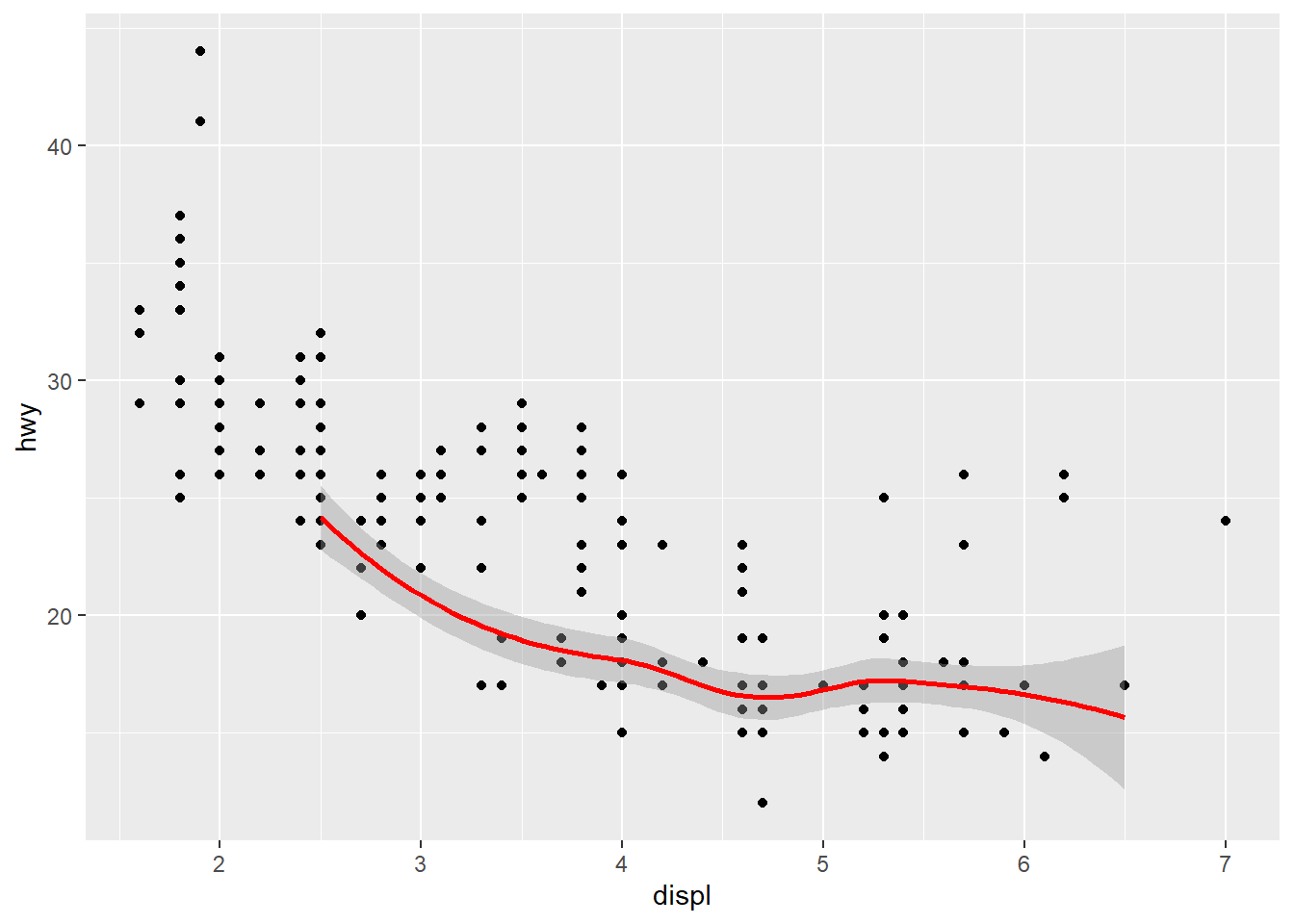
2.2 스케일
스케일(scales)은 시각속성 매핑이 구체적으로 어떻게 구현될지를 결정한다. 예를 들어 컬러 시각속성이 적용되었다 하더라도 어떤 컬러가 선정되어 어떻게 배열되는지에 따라 최종 그래프의 모습은 매우 달라질 수 있다. 그러므로 스케일은 시각속성과 불가분의 관계에 있다. ggplot2 패키지가 제공하는 스케일이 표 3 에 정리되어 있다. 많이 사용되는 스케일에 scale_color_brewer(), scale_color_viridis_c(), scale_x_continous(), scale_x_discrete(), scale_y_continous(), scale_y_discrete() 등이 있다.
그래프를 다시 살펴본다. 스케일이 어느 부분에 어떻게 적용되었는지 생각해 본다.
ggplot(mpg, aes(x = displ, y = hwy, color = drv)) +
geom_point() 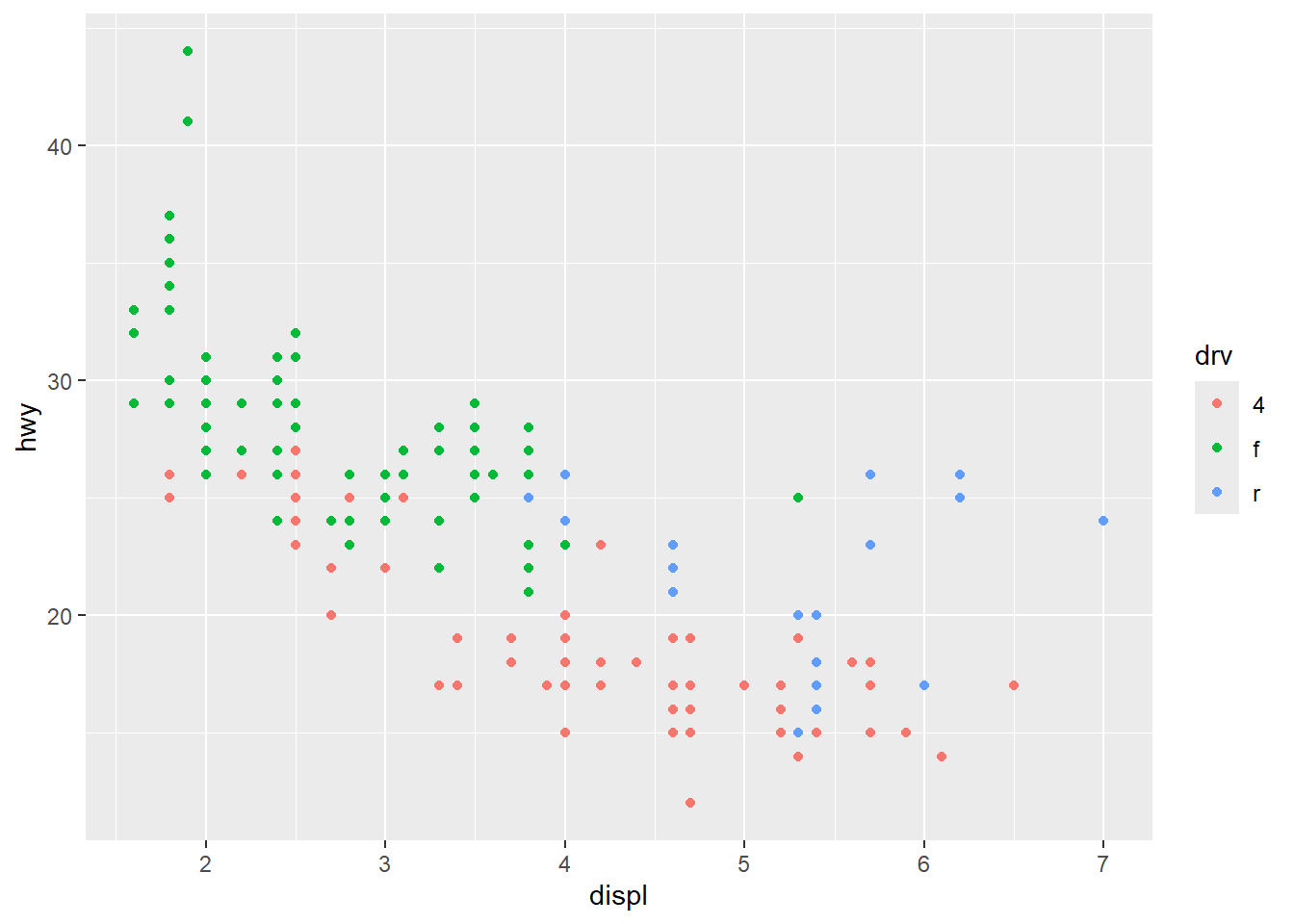
그림 17 은 아래에서 보는 것처럼, ggplot2가 자동적으로 적용한 세 가지의 스케일 설정에 의거해 만들어진 것이다.
ggplot(mpg, aes(x = displ, y = hwy, color = drv)) +
geom_point() +
scale_x_continuous() +
scale_y_continuous() +
scale_color_discrete()수정하여 다음과 같이 적용할 수 있다. scale 함수의 각 인수가 어떤 역할을 하는지 생각해 본다.
ggplot(mpg, aes(x = displ, y = hwy, color = drv)) +
geom_point() +
scale_x_continuous(labels = NULL) +
scale_y_continuous(breaks = seq(15, 40, by = 5)) +
scale_color_brewer(palette = "Set1", labels = c("4" = "4-wheel", "f" = "front", "r" = "rear"))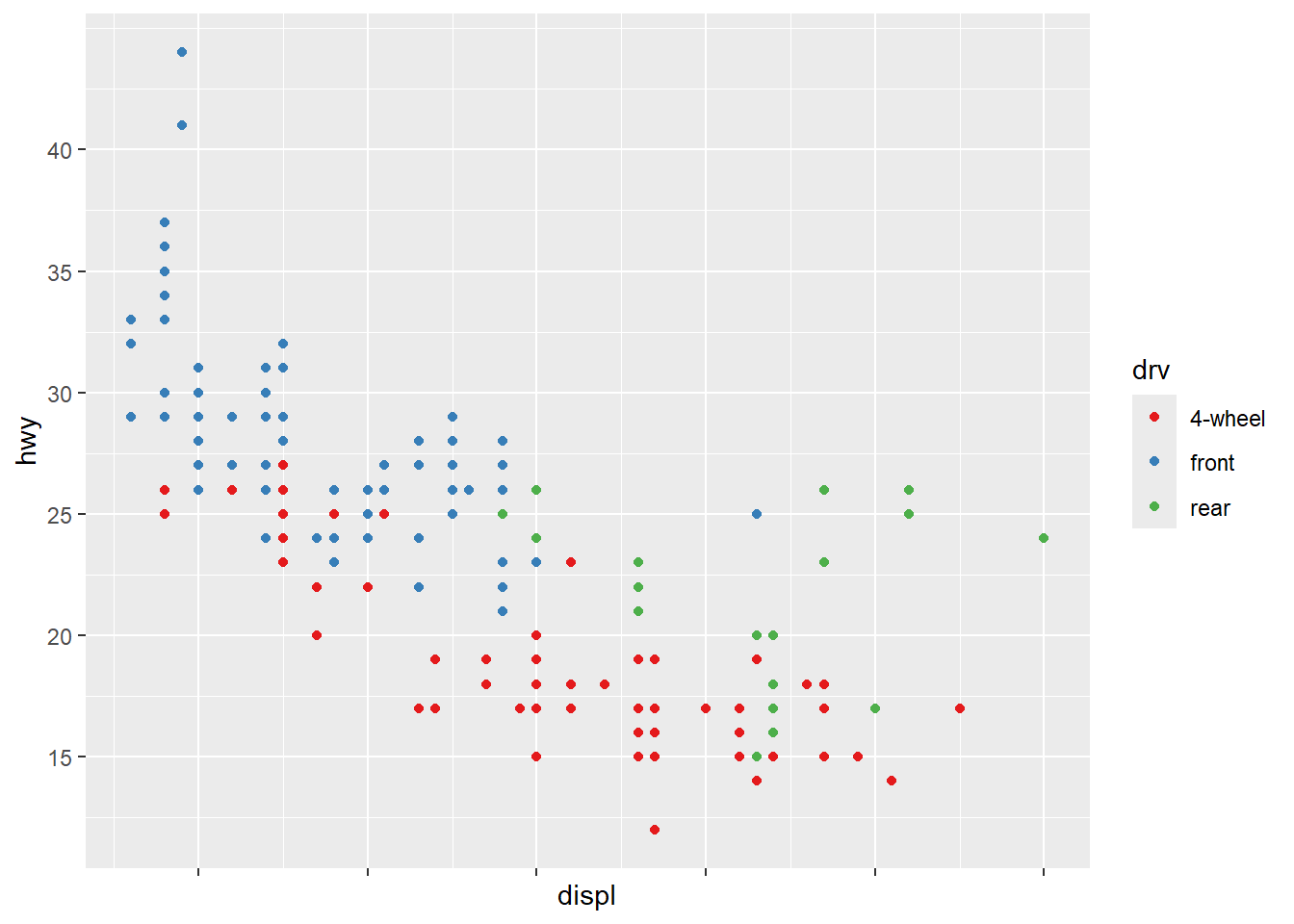
scale_color_brewer() 함수는 ColorBrewer 컬러 스케일을 사용한 것인데 익히고 있으면 많은 도움이 된다. 여기에는 다양한 색배열(color schemes)이 제시되어 있는데, 이것을 ggplot2 패키지에서는 팔레트(palette)라고 부른다. 그림 19 에는 다양한 브루어 컬러 팔레트가 제시되어 있는 데 왼편의 문자가 팔레트의 이름이고(예: YlOrRd), scale_color_brewer() 함수 속에 막바로 사용가능하다. 첫번째 군은 정량적 팔레트 중 순차형(sequential) 팔레트들이고, 두번째 군은 정성적 혹은 범주형(categorical) 팔레트들이고, 세번째 군은 정량적 팔레트 중 분기형(diverging) 팔레트들이다. 변수의 성격에 가장 적절한 팔레트를 선택하는 것이 관건이다.
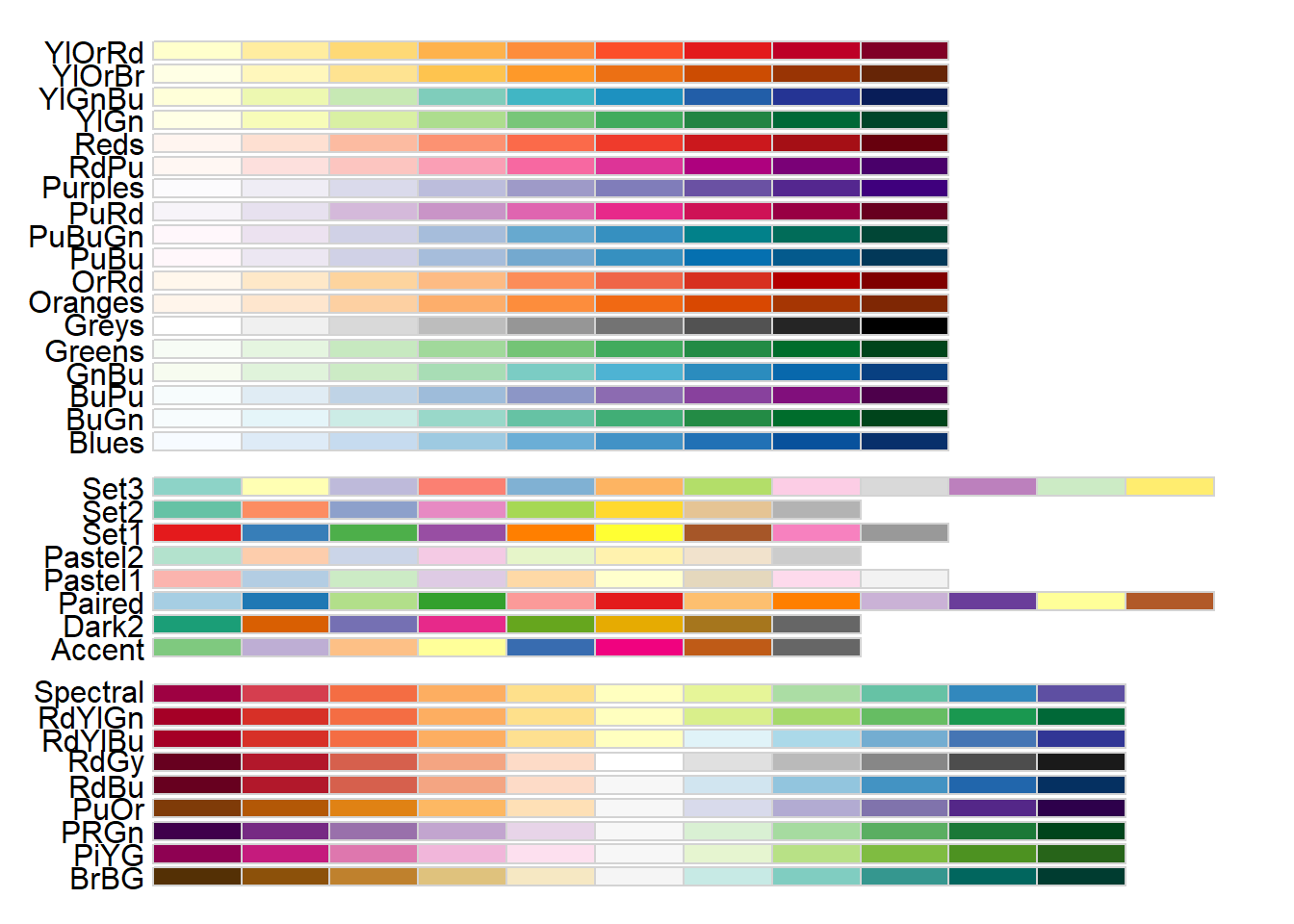
자신만의 팔레트를 적용할 수도 있다. scale_color_brewer() 대신 scale_color_manual() 함수를 사용하면 된다. 또한 RGB 색상에 대한 HTML 헥스 코드( html hex code)를 사용해도 되고, R에서 부여한 657개의 이름 중에서 골라 사용해도 된다. 색상 이름 및 헥스 코드는 다음 사이트를 참고하라.
ggplot(mpg, aes(x = displ, y = hwy, color = drv)) +
geom_point() +
scale_x_continuous(labels = NULL) +
scale_y_continuous(breaks = seq(15, 40, by = 5)) +
scale_color_manual(values = c("sienna1", "slateblue4", "#698B22"))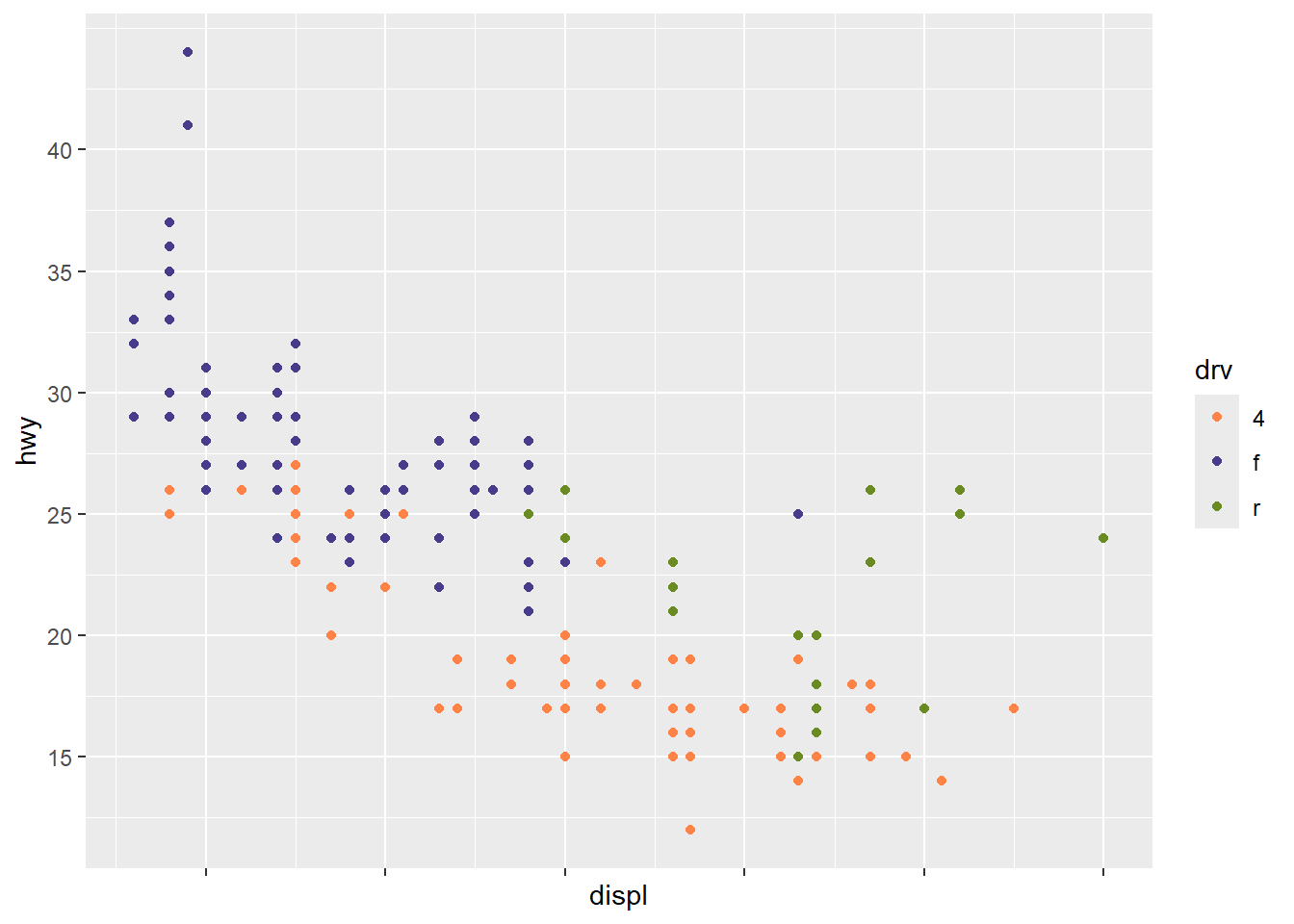
2.3 패싯
패싯(facets) 레이어는 다면생성(faceting) 과정을 통해 하나의 플롯을 여러개의 하위 플롯으로 쪼갬으로서 생성된다. facet_wrap() 함수가 핵심이다.
ggplot(mpg, aes(x = displ, y = hwy)) +
geom_point() +
facet_wrap(~cyl)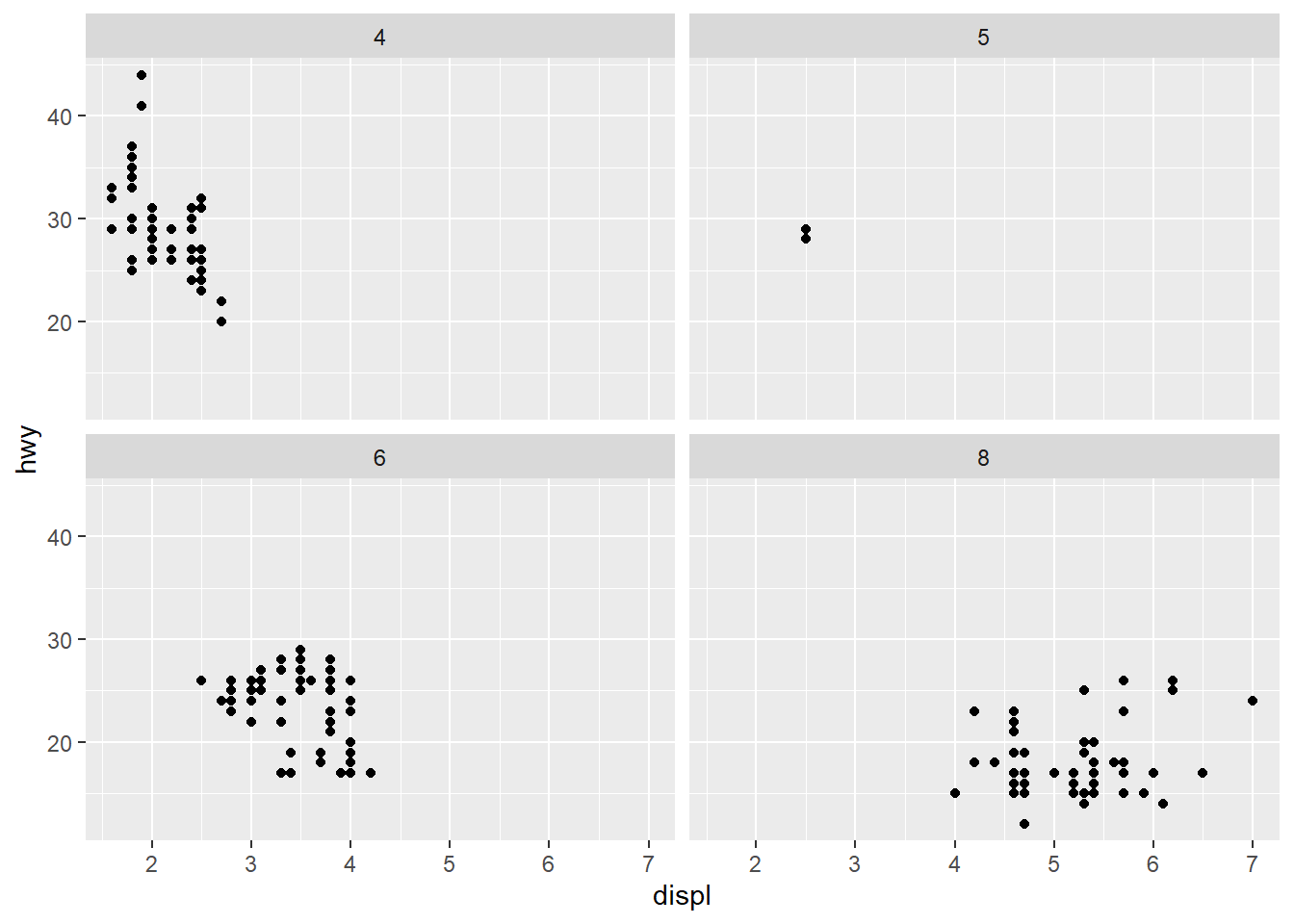
두 개의 변수에 의거해 패싯을 생성할 수도 있다. facet_wrap() 함수 대신 facet_grid() 함수가 적용된다.
ggplot(mpg, aes(x = displ, y = hwy)) +
geom_point() +
facet_grid(drv ~ cyl)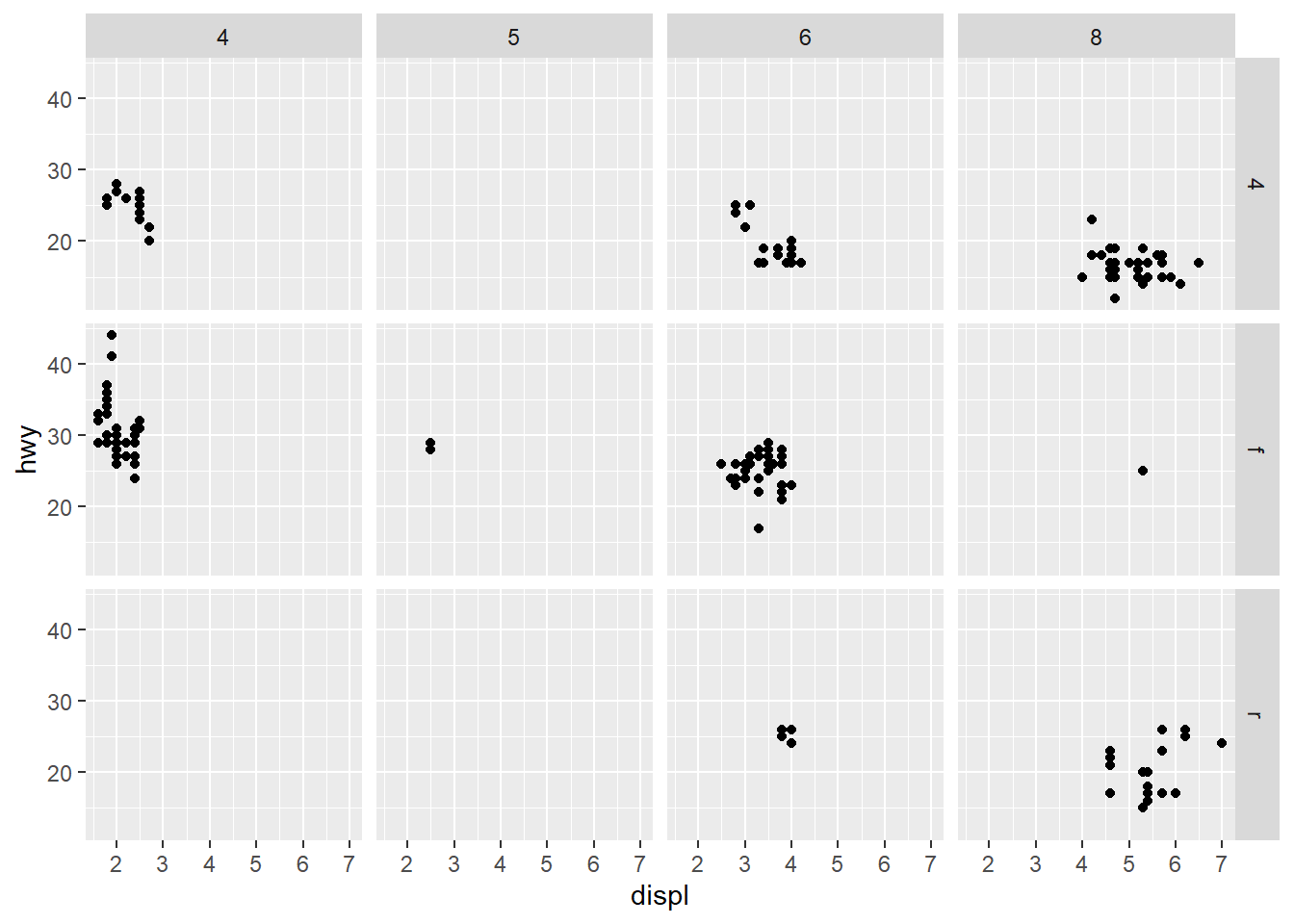
2.4 통계적 변환
어떤 시각화 과정은 필연적으로 통계적 변환(statistical transformation)을 수반한다.
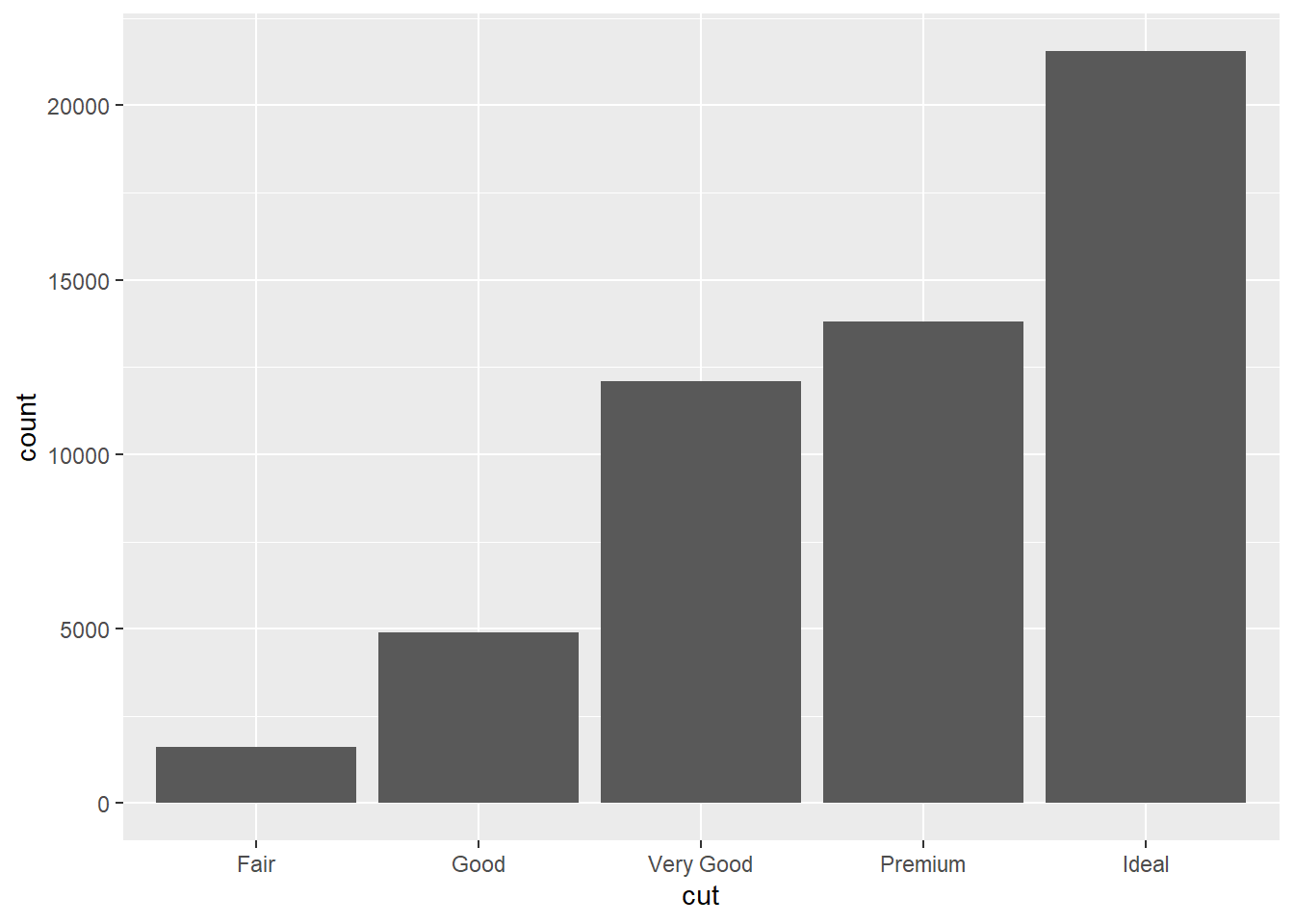
그림 23 는 그림 24 에서 보는 바와 같이, 원데이터로부터 빈도를 계산(통계적 전환)하고 그것을 그래프로 변환한다.
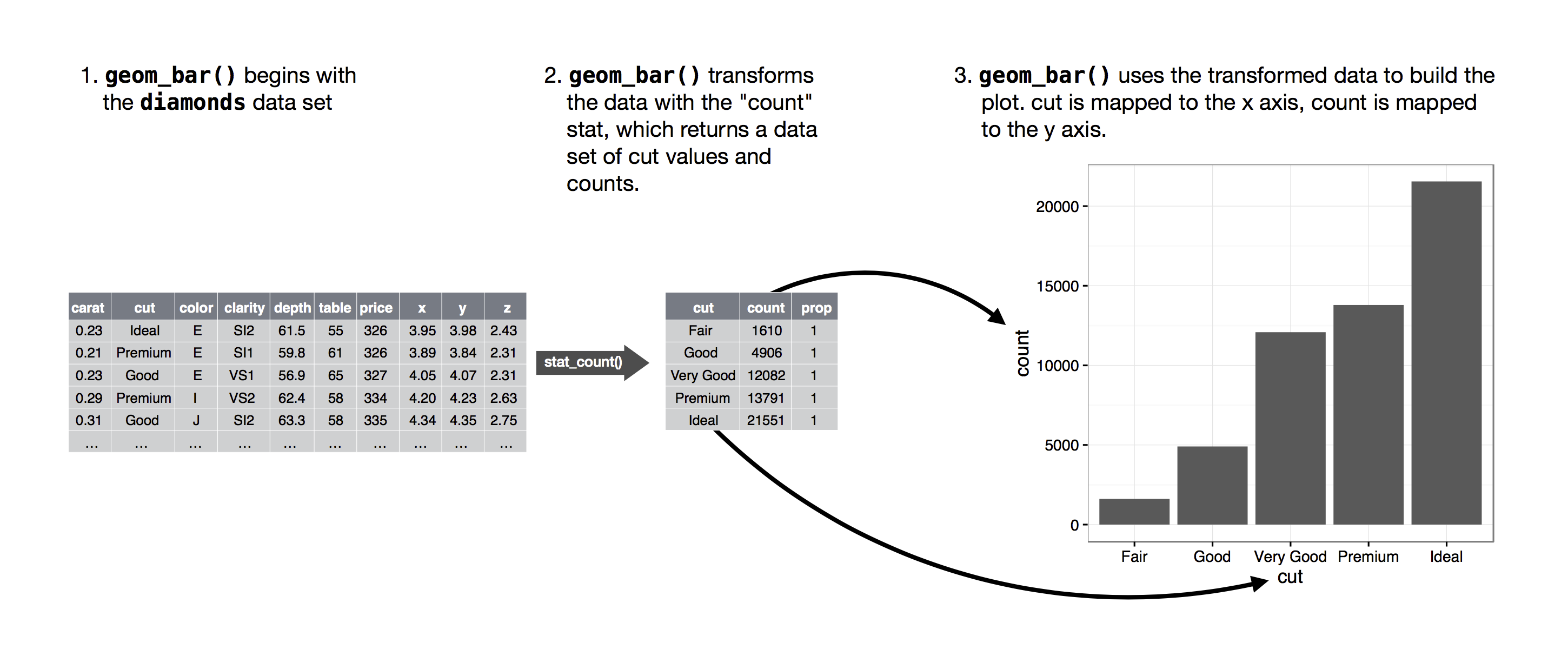
모든 geom_*()은 통계적 변환에 대한 인수인 stat에 대해 기본값을 가지고 있다. geom_bar()의 통계적 변환의 기본값은 stat = count 이다. 단일 변수에 대해 빈도 분포에 대한 막대 그래프를 작성할 때는 이 기본값이 잘 작동한다. 그런데, geom_bar()에 단일 변수가 아니라 두 개의 변수가 시각속성에 적용되는 경우(한 변수는 x축에 위치하는 범주 변수, 또 다른 변수는 해당 범주별 빈도값), 적절한 통계적 변환의 유형은 count가 아니라 identity이다. 따라서 이 경우에는 따라 stat = "identity"를 반드시 따로 지정해 주어야 한다. 그렇지 않으면 원하는 결과를 얻을 수 없다.
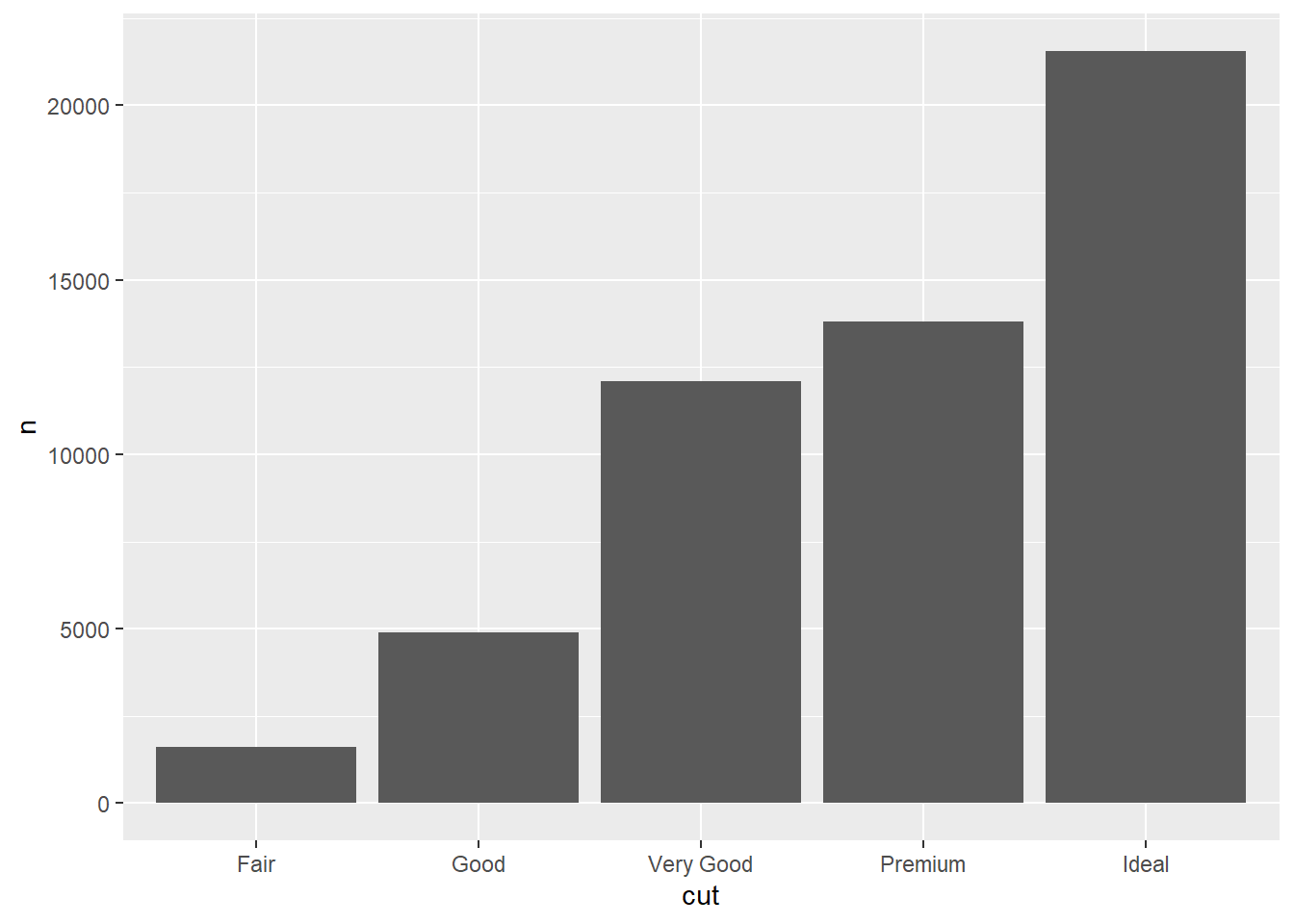
그런데 geom_bar()와 유사한 geom_col()이라는 함수를 사용해도 동일한 결과를 얻을 수 있다. geom_col()에서는 통계적 변환의 기본값이 count가 아니라 identity이기 때문에 위와 달리 stat = "identity"를 따로 지정할 필요가 없다. 결국 단일 변수에 대한 빈도 분포를 나타내고 싶으면 geom_bar()를, 두 변수를 이용해 빈도 분포를 나타내고 싶으면 geom_col()을 사용하면 된다.
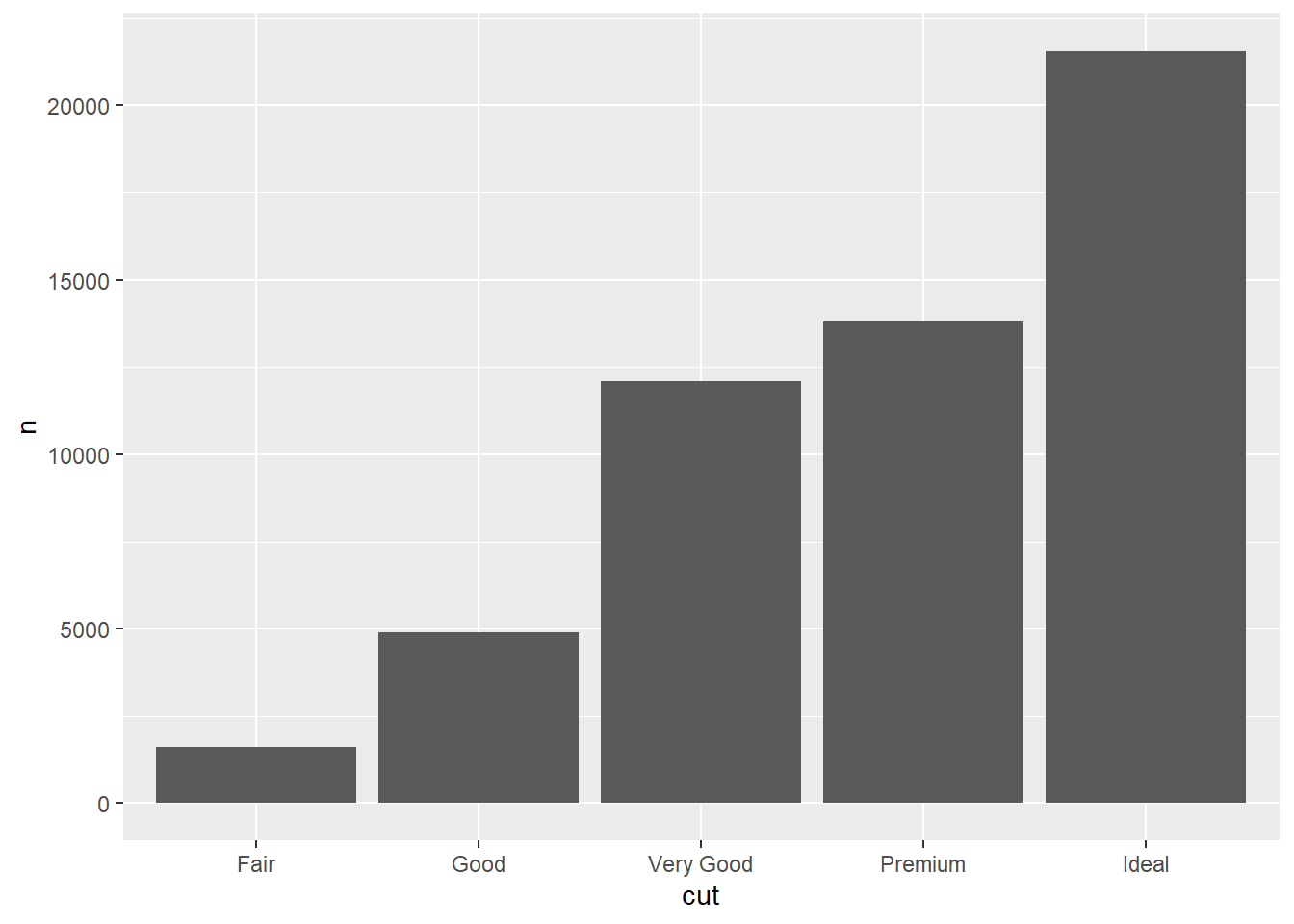
after_stat()이라고 하는 보조 함수를 사용하면, 이 그래프를 절대 빈도가 아닌 상대 빈도 그래프로 변환할 수 있다. 이 역시 통계적 변환 과정이 이면에 숨어 있다. group 인수가 매우 중요하다. 이것을 지정하지 않으면 개별 cut별로 계산하기 때문에 모든 막대가 1이 된다. group = 1로 지정했다는 것은 cut에 관계 없이 모두를 한 덩어리로 생각하고 비중을 구한다는 것을 의미한다. 사실 1이 아니라 어떤 다른 숫자여도 상관이 없다.
ggplot(diamonds, aes(x = cut, y = after_stat(prop), group = 1)) +
geom_bar()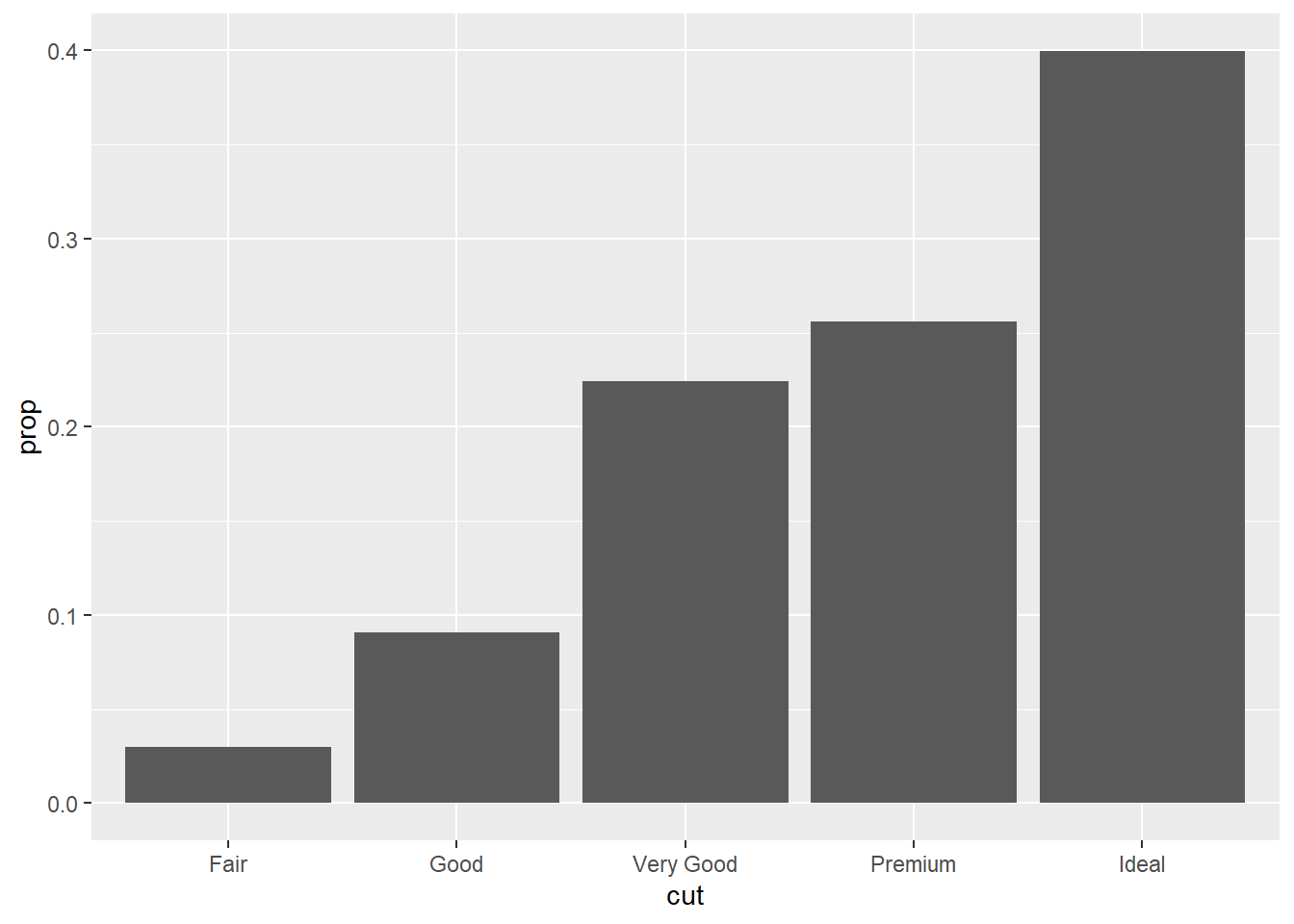
막대 그래프에 시각속성을 가미하고, position 인수를 통한 위치 조정(position adjustment)을 시도한다.
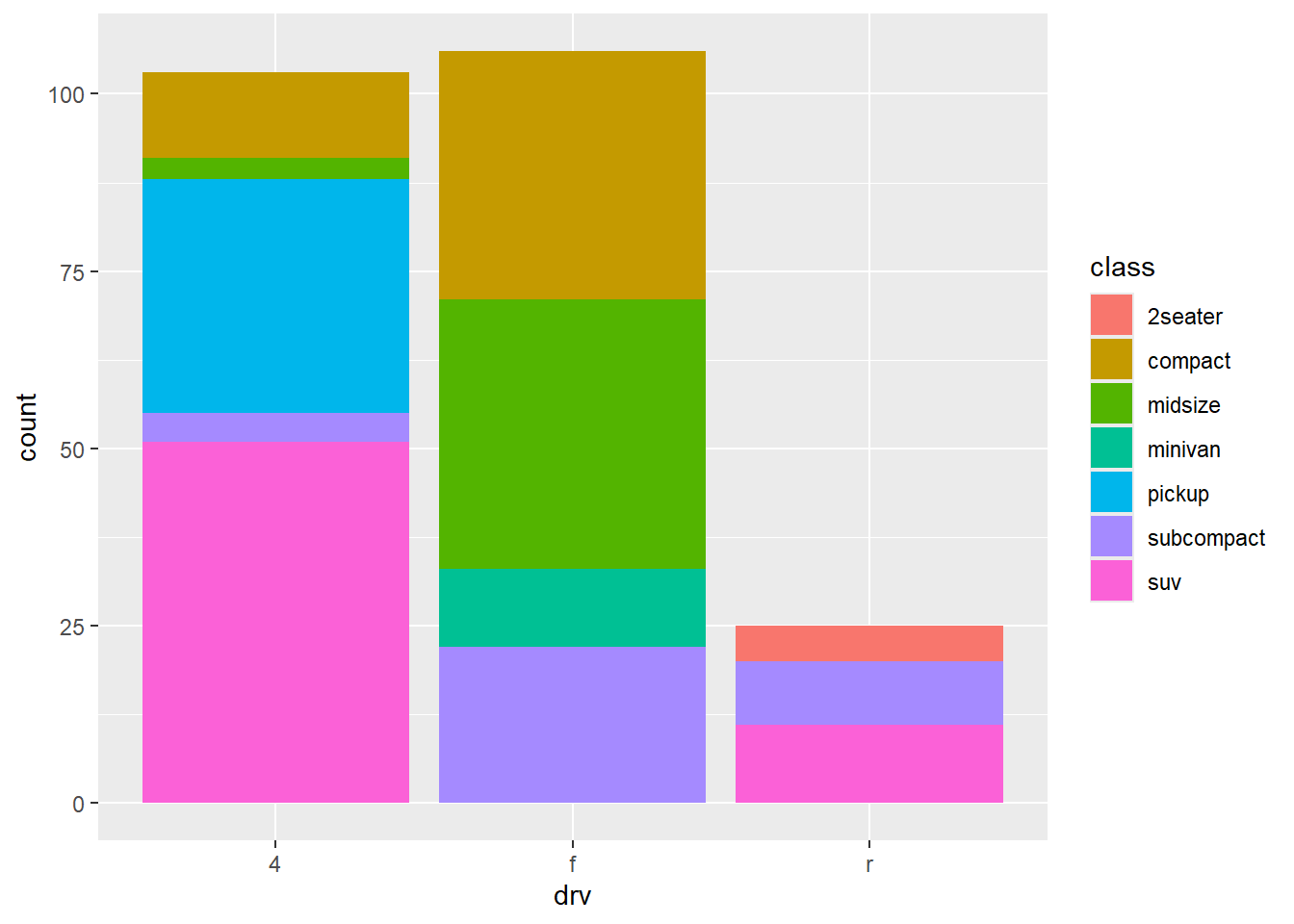
기하객체에 색상을 지정하고 싶을 때, 0차원(point)과 1차원(line) 객체에는 color라는 시각속성을 적용하지만, 막대 그래프와 같은 2차원(area) 객체에는 fill이라는 시각속성을 적용한다. 자주 혼돈이 되는 부분이다.
위치 조정을 위해 position 인수를 사용하는데, 네 가지 옵션이 있다.
position = "stack": 누적 배치. 같은 x축 범주에 속한 여러 집단의 값을 위로 쌓아 올려 표현한다. 전체 합계와 그룹별 비중을 한눈에 보기 쉽다.position = "identity": 원자료 그대로 배치. 겹치면 그대로 덮어써서 보이게 된다. 투명도를 조정하지 않으면 겹침 현상 때문에 해석이 어렵다.position = "dodge": 옆으로 나란히 배치. 같은 x축 범주에 속한 여러 집단을 옆으로 나란히 분리하여 표현하는데, 그룹 간 비교에 적합하다.position = "fill": 누적 비율 배치."stack"과 마찬가지로 쌓되, 전체 높이를 항상 1(100%)에 맞춰 상대적 비율만 보여준다. 전체 규모가 아니라 구성비(비율) 비교에 적합하다.
그림 28 에는 기본값으로 position = "stack"이 적용된 것이다. 그림 29 는 position = "dodge"를 적용한 것이다 .
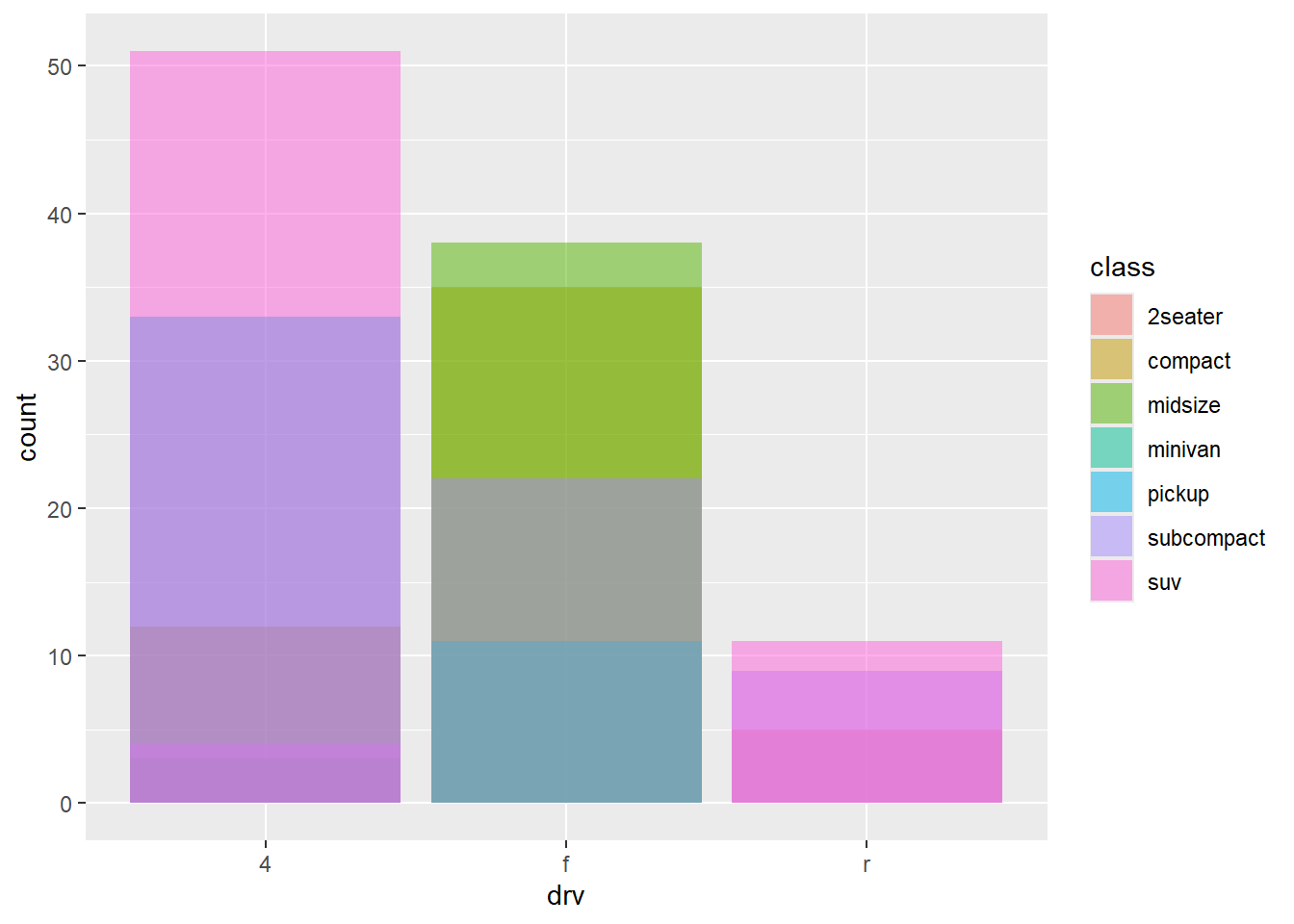
그림 30 는 position = "dodge"를 적용한 것이다 .
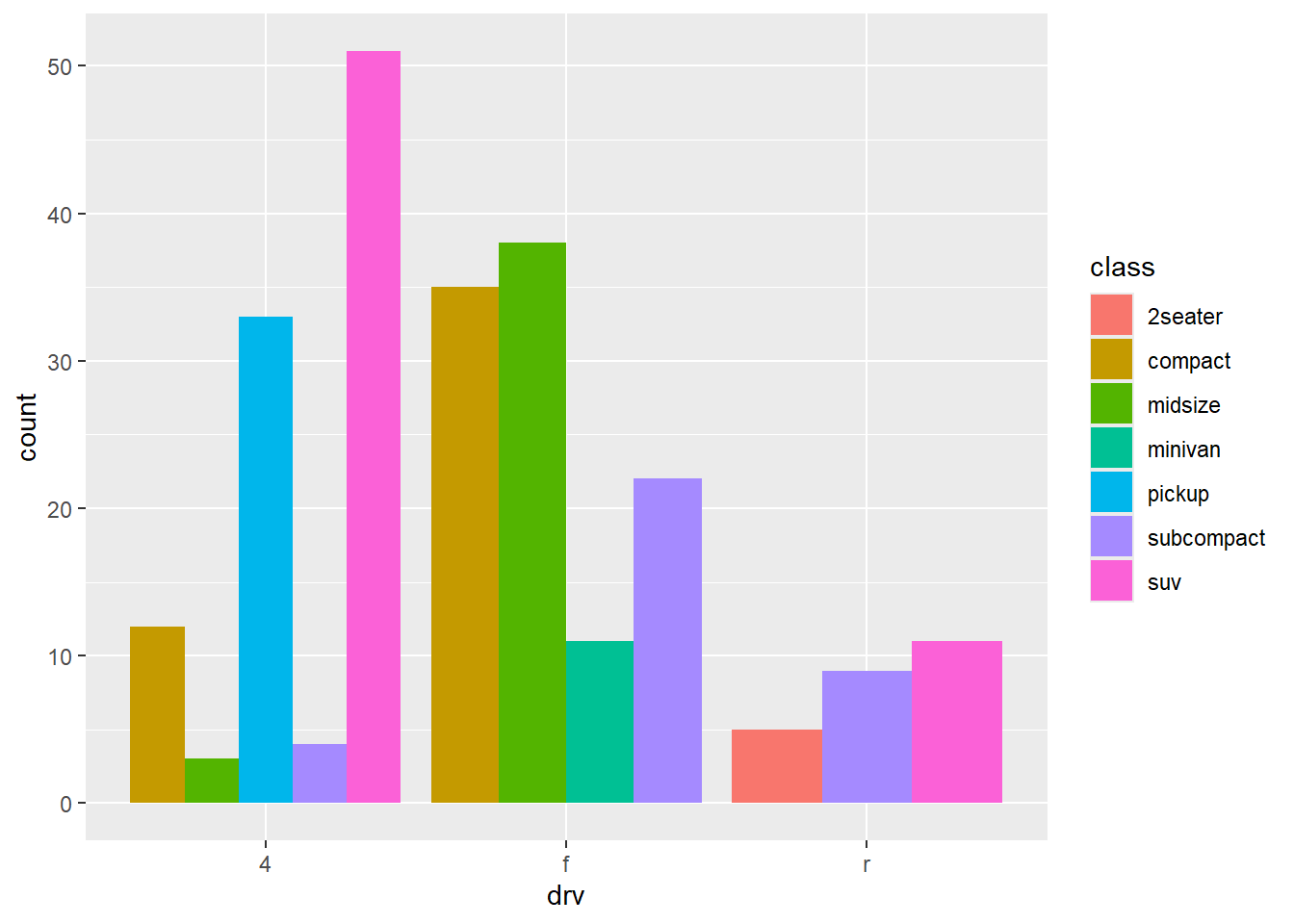
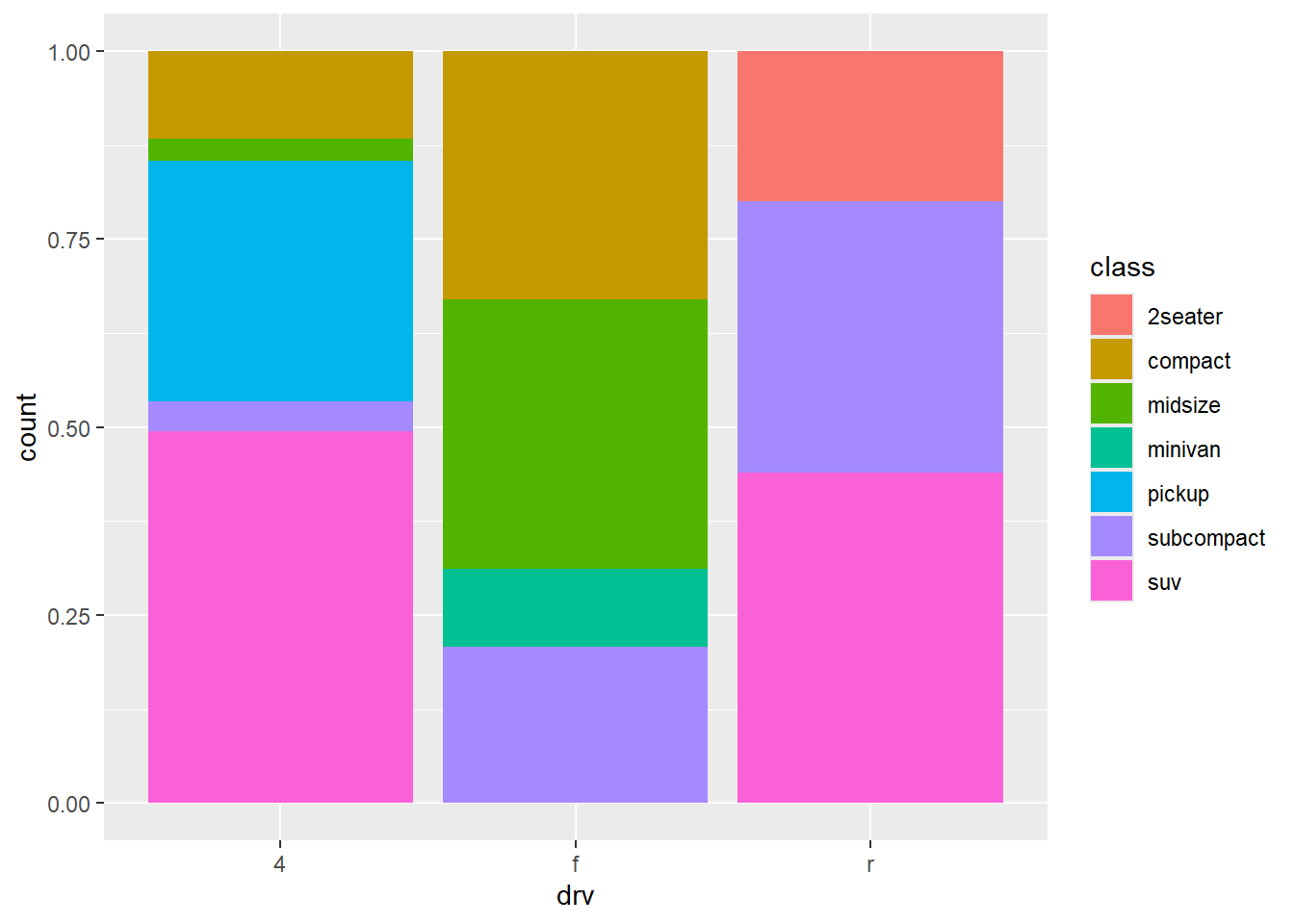
그림 31 는 position = "fill"을 적용한 것이다 .
2.5 좌표
좌표(coordinates) 혹은 좌표계(coordinate systems)는 그래픽 요소들의 위치 결정에 기준이 되는 준거체계이다. 특히 두 가지가 함수가 유용하다. coord_flip() 함수는 축을 전환한다.
ggplot(mpg, aes(x = drv, fill = class)) +
geom_bar(position = "fill") +
coord_flip()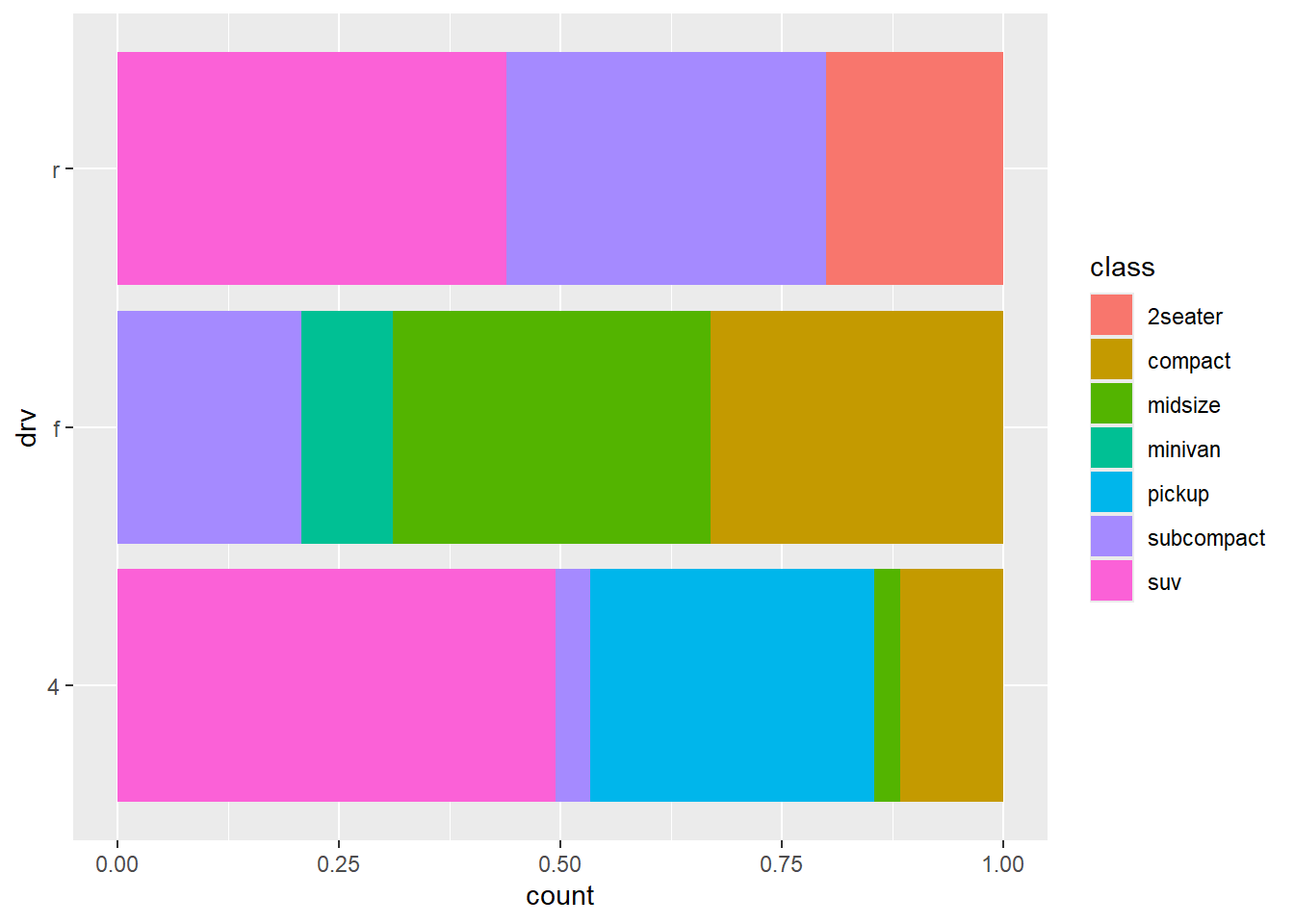
coord_fixed() 함수는 두 축의 스케일을 절대화하여 동일하게 적용한다. x-축의 10 간격이 y-축의 10 간격과 동일하다. 이것을 적용하지 않으면 x-축이 길어지기 때문에 절대적 비교를 할 수 없게 된다.
ggplot(mpg, aes(cty, hwy)) +
geom_point() +
coord_fixed()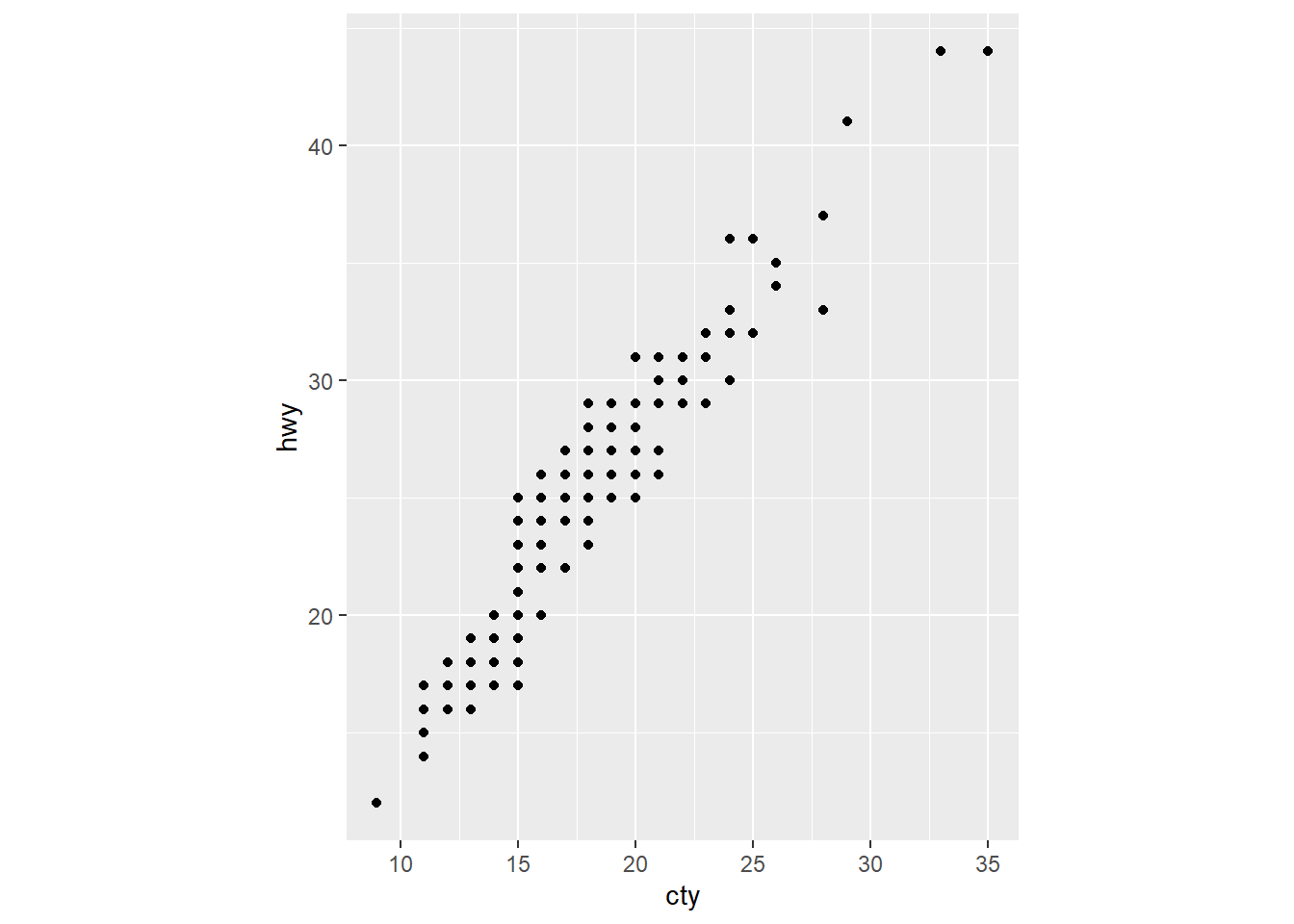
2.6 테마
테마(themes)는 그래프의 외양에 영향을 끼치는 또 다른 요소이다. 우선, 전체적인 외양을 한꺼번에 바꿀 수 있다. ggplot2는 그림 34 에서 보는 처럼 모두 8가지 기본 테마를 제공한다.
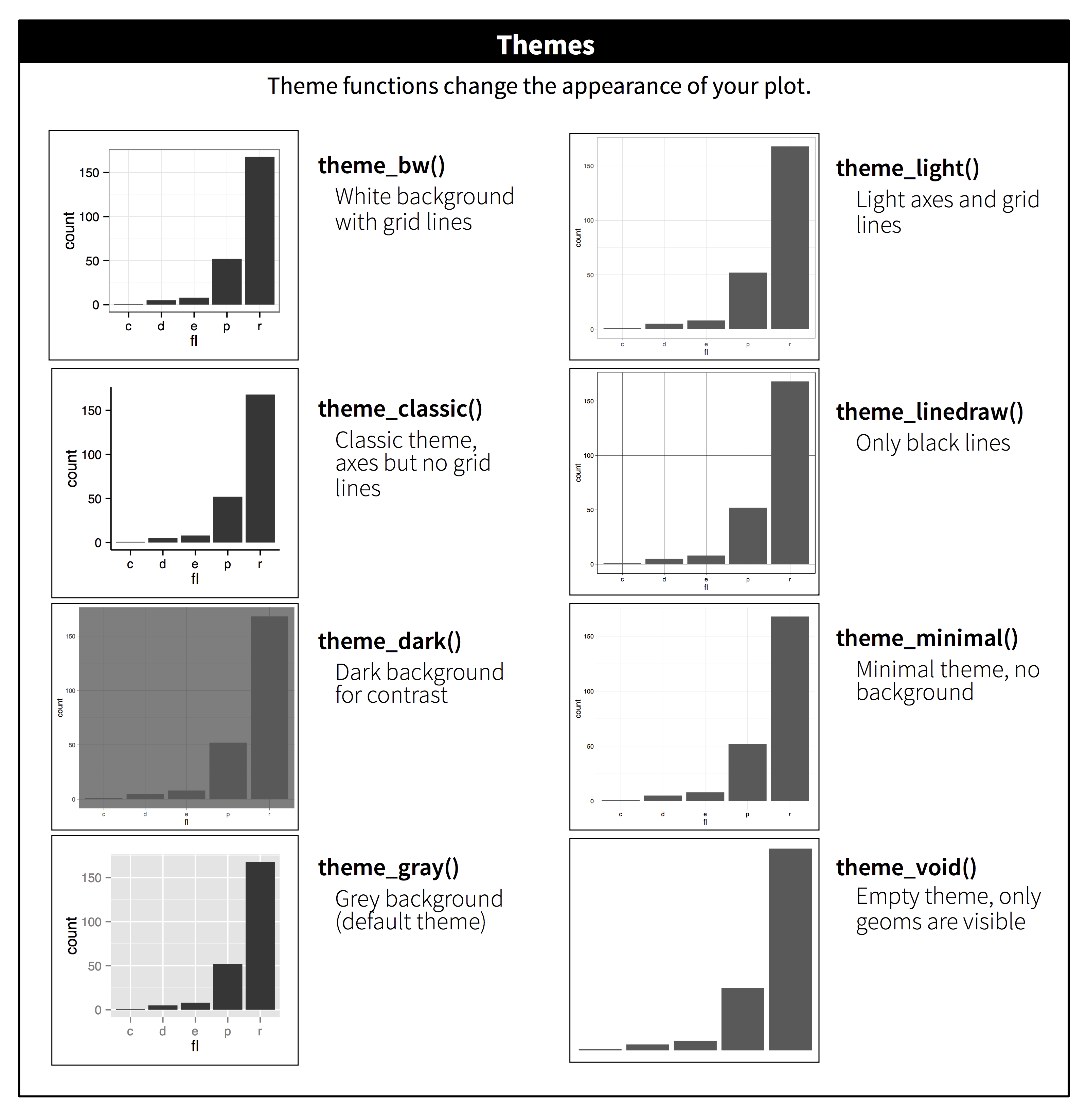
기본값인 회색빛 배경이 마음에 들지 않았다면 그림 35 처럼 흑백 테마(theme_bw())를 적용할 수도 있다. 다른 테마도 적용해 보고 그 차이를 알아본다.
ggplot(mpg, aes(x = displ, y = hwy)) +
geom_point(aes(color = class)) +
geom_smooth(se = FALSE) +
theme_bw()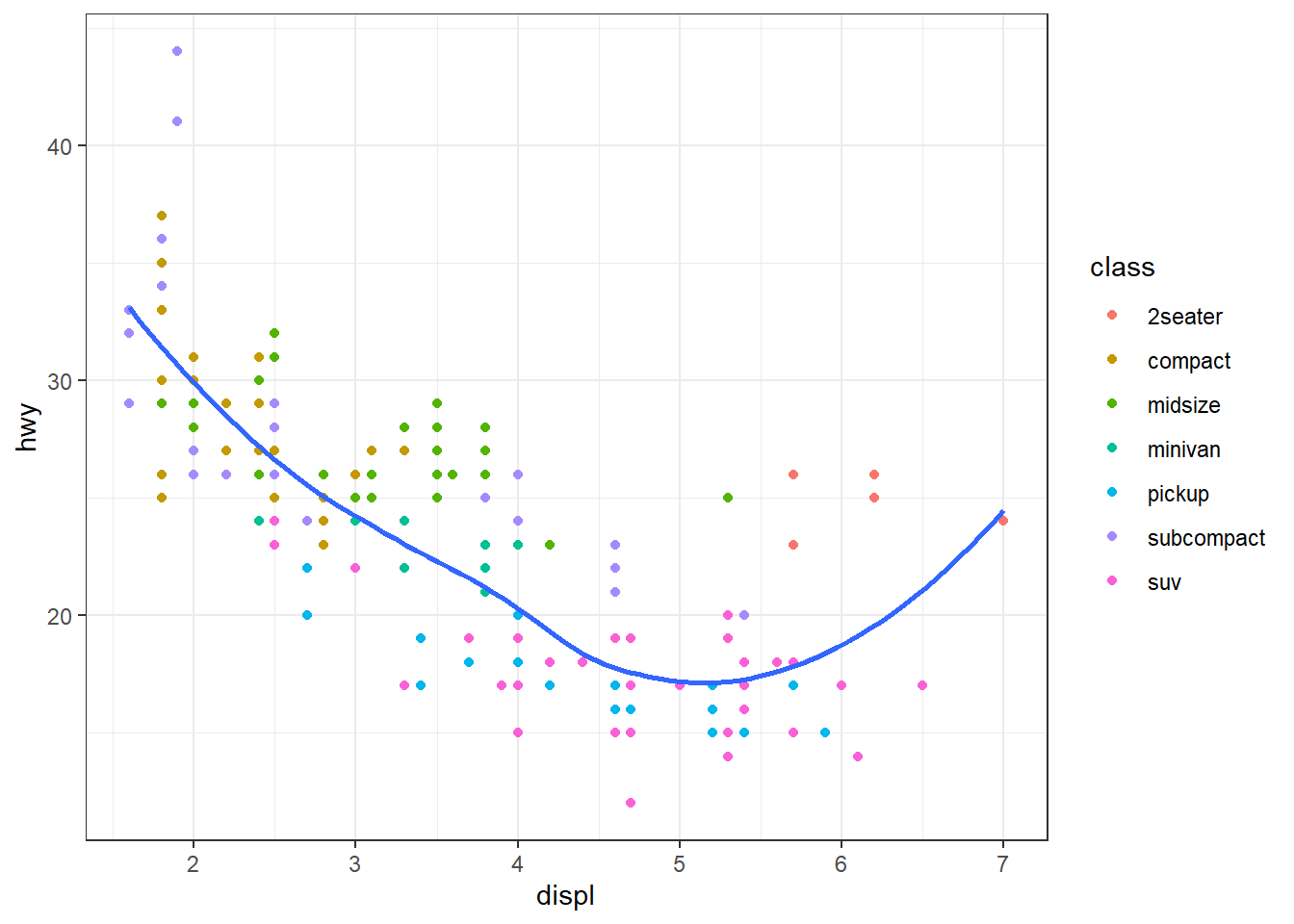
이렇게 한꺼번에 그래프의 외관을 바꿀 수도 있지만 theme() 함수를 통해 그래프의 개별 요소 하나씩을 모두 조정할 수 있다. 중요한 그래픽 요소가 그림 36 에 나타나 있다.
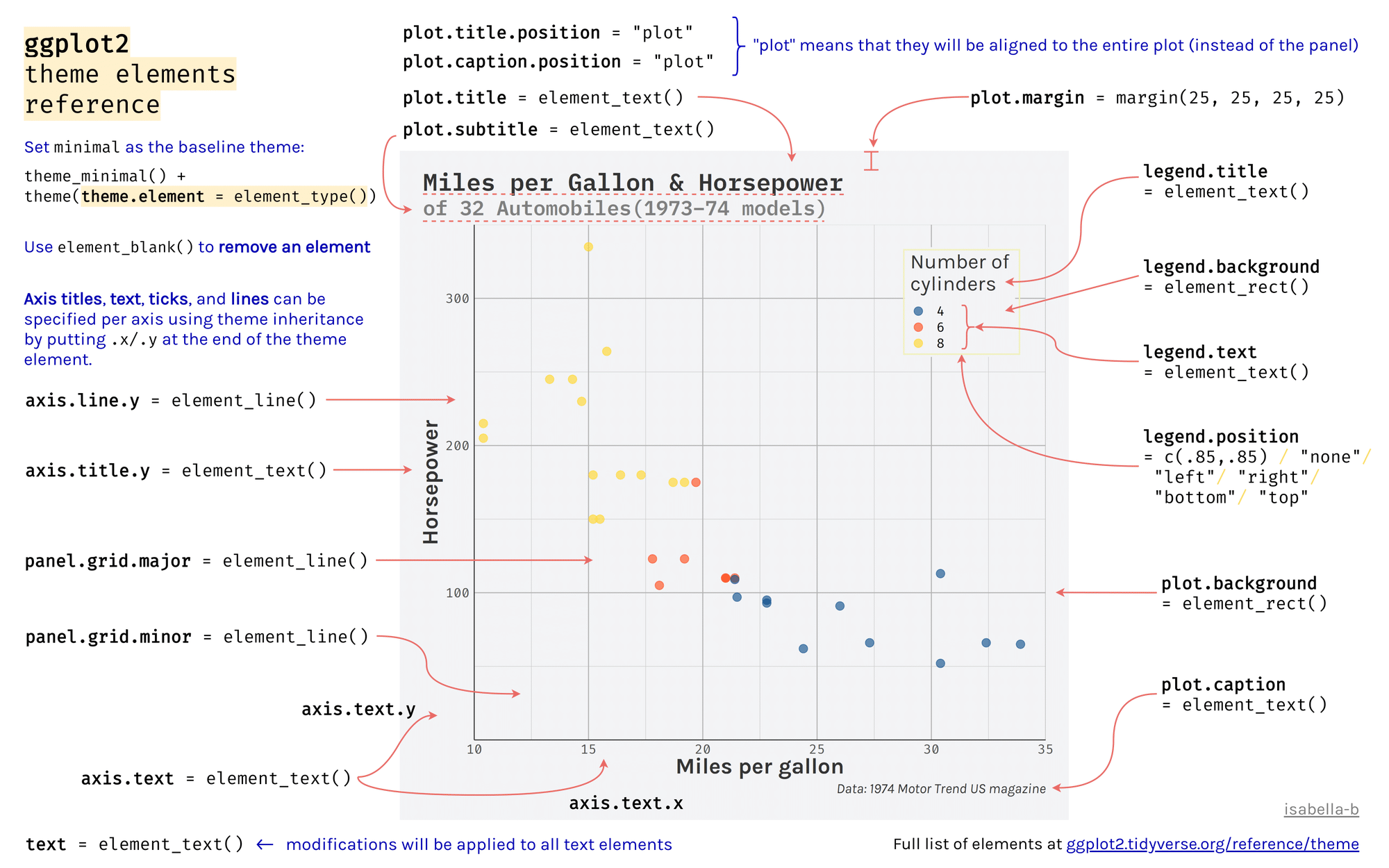
theme() 함수를 통해 수정 가능한 그래픽 요소는 그림 36 에 나타나 있는 것보다 훨씬 더 많다. 자세한 사항은 ggplot2 패키지의 해당 웹페이지를 참고한다.
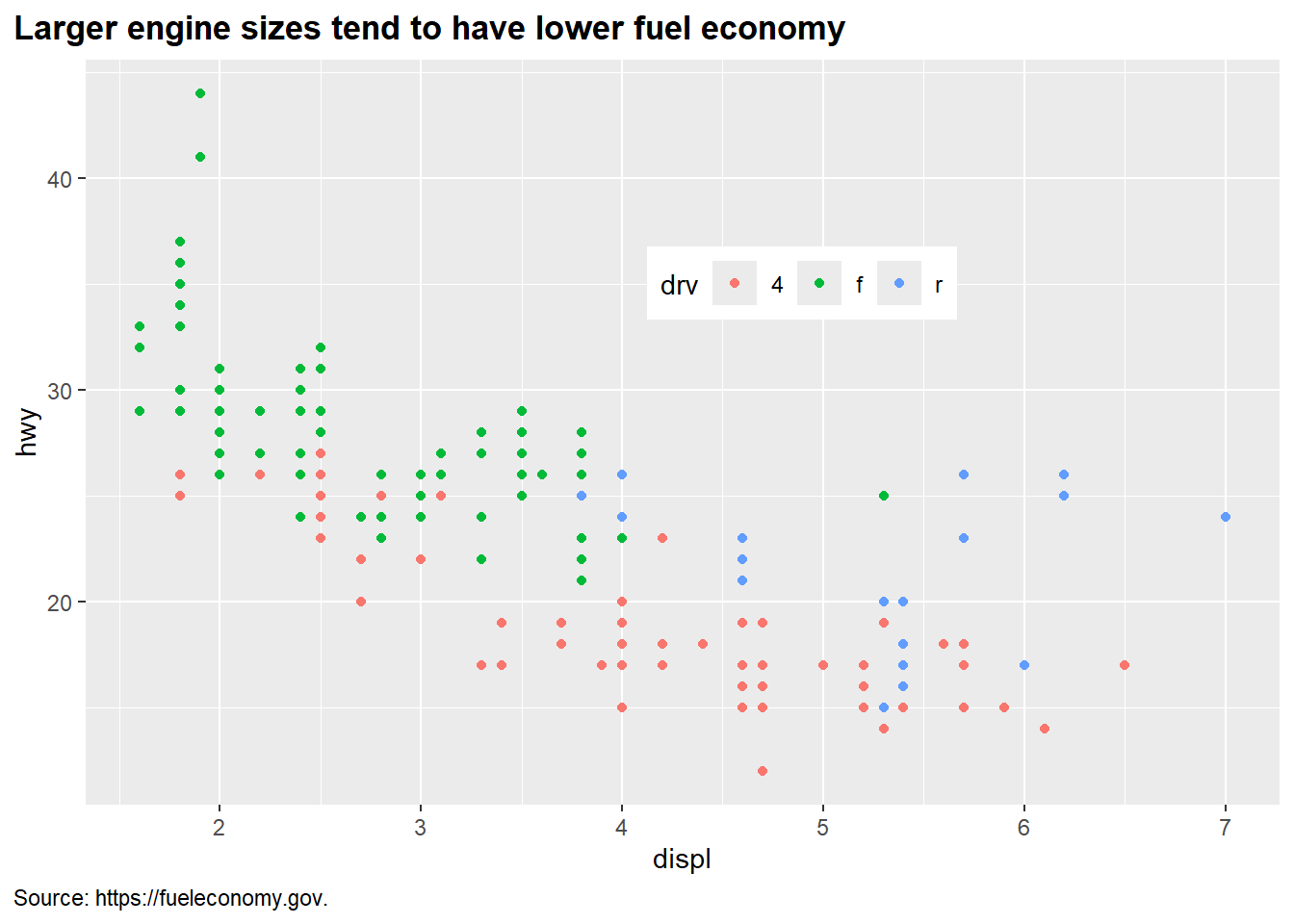
그림 37 는 몇 가지 요소를 수정한 사례이다.
ggplot(mpg, aes(x = displ, y = hwy, color = drv)) +
geom_point() +
labs(
title = "Larger engine sizes tend to have lower fuel economy",
caption = "Source: https://fueleconomy.gov."
) +
theme(
legend.position = c(0.6, 0.7),
legend.direction = "horizontal",
plot.title = element_text(face = "bold"),
plot.title.position = "plot",
plot.caption.position = "plot",
plot.caption = element_text(hjust = 0)
)
3 기타 사항
3.1 라벨과 주석
lab() 함수를 활용하면 그래프의 다양한 종류의 라벨을 설정할 수 있다.
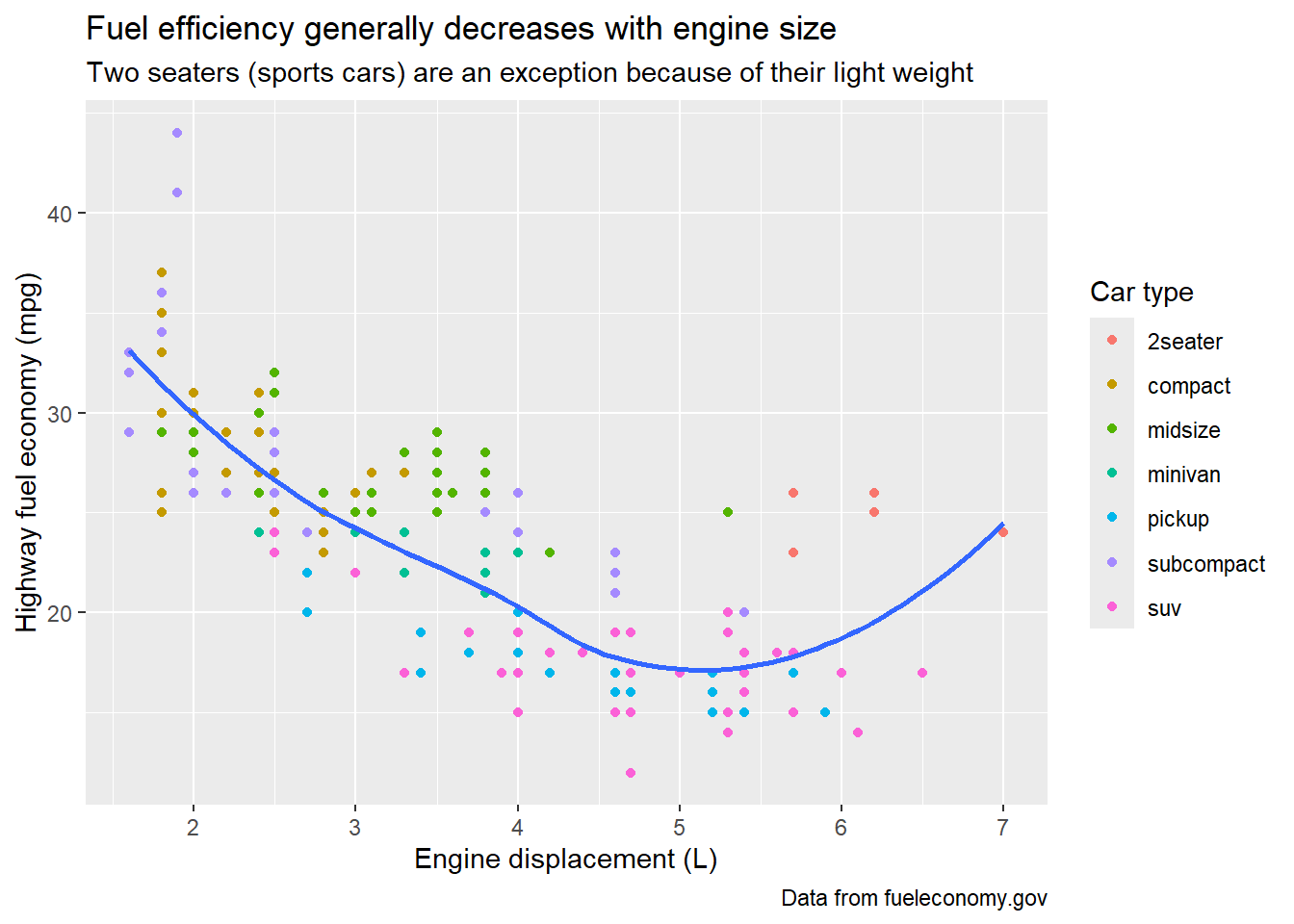
ggplot(mpg, aes(x = displ, y = hwy)) +
geom_point(aes(color = class)) +
geom_smooth(se = FALSE) +
labs(
x = "Engine displacement (L)",
y = "Highway fuel economy (mpg)",
color = "Car type",
title = "Fuel efficiency generally decreases with engine size",
subtitle = "Two seaters (sports cars) are an exception because of their light weight",
caption = "Data from fueleconomy.gov"
)
또 다른 기하객체인 geom_text() 혹은 geom_label()를 통해 그래프 속에 텍스트를 삽입할 수 있다. 주석이 겹치는 것을 방지하고자 싶다면 ggrepel 패키지를 사용하면 된다. 새로운 기하객체인 geom_label_repel() 함수가 사용되었는데, label이 하나의 시각속성으로 사용되는 것을 알 수 있다.
library(ggrepel)
ggplot(mpg, aes(displ, hwy)) +
geom_point(colour = "red") +
geom_label_repel(data = mpg |> slice_sample(prop = 0.1), aes(label = class))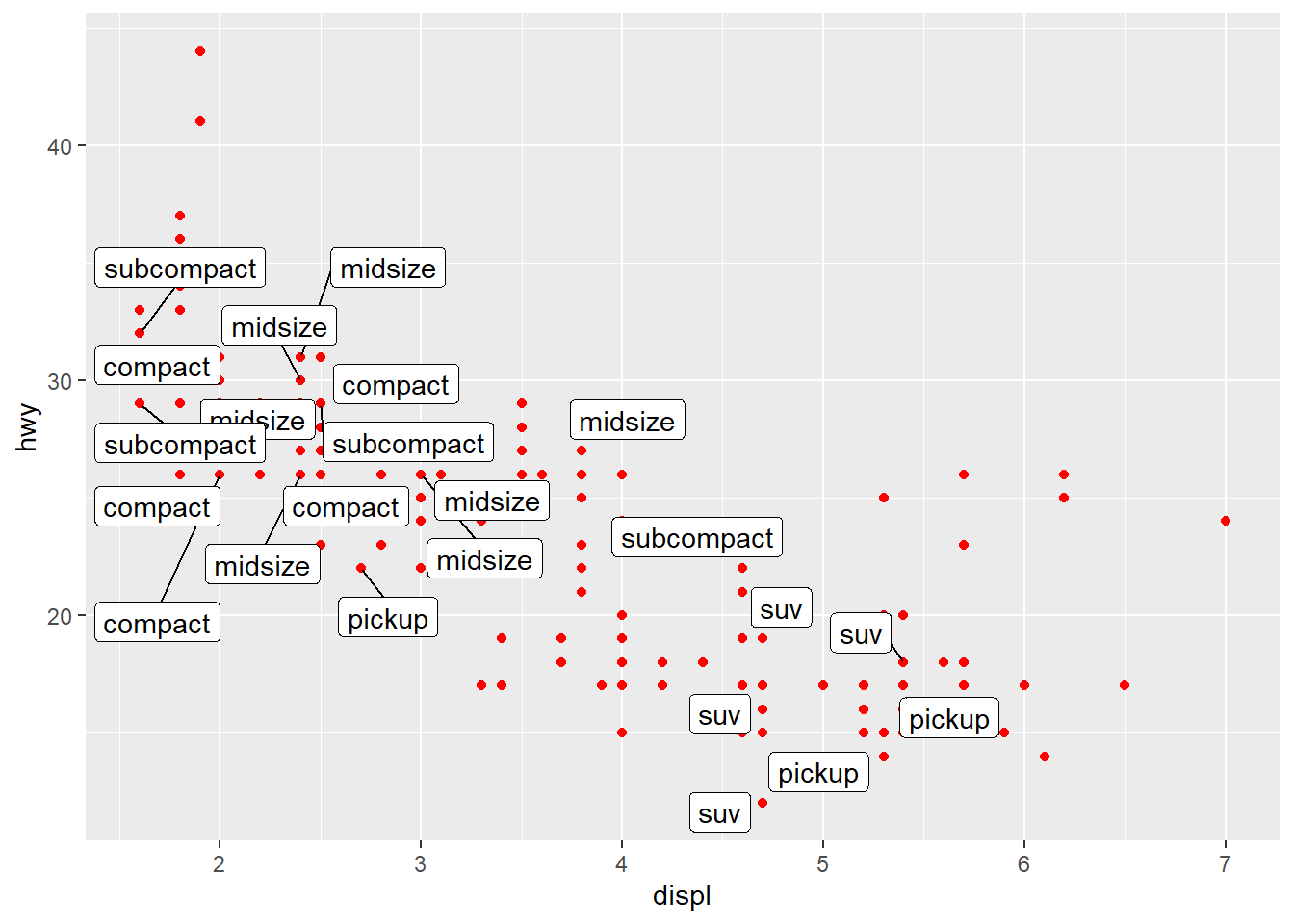
3.2 레이아웃
레이아웃(layout)은 복수의 그래프를 적절히 배치하여 하나의 그래픽으로 융합하는 과정을 의미한다. 수 많은 ggplot2의 확장 패키지(ggplot2 extensions) 중 하나인 patchwork 패키지를 활용하여 자유롭게 레이아웃을 만들 수 있다.
library(patchwork)
p1 <- ggplot(mpg, aes(x = displ, y = hwy)) +
geom_point() +
labs(title = "Plot 1")
p2 <- ggplot(mpg, aes(x = drv, y = hwy)) +
geom_boxplot() +
labs(title = "Plot 2")
p1 + p2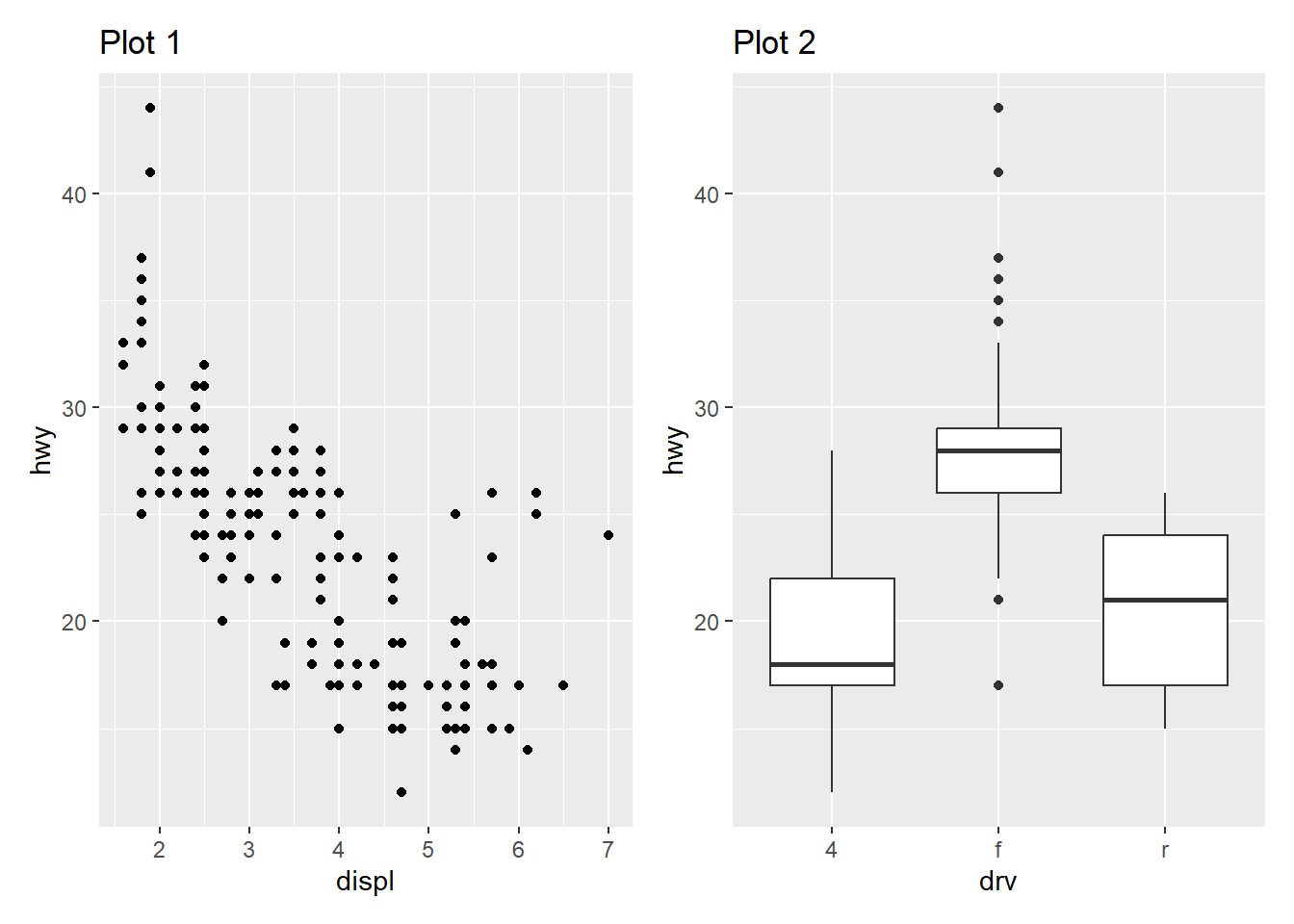
3.3 그래프의 저장
두 가지 방식이 있다.
첫 번째 방식은 Output 창의 Plots 탭에 있는 Export 버턴을 이용하는 것이다. 다양한 그래픽 포맷 뿐만 아니라 pdf 형식으로도 저장할 수 있다.
두 번째 방식은 ggplot2 의 ggsave() 함수를 이용하는 것이다. 결과물의 폰트 크기, 가로세로비(aspect ratio), 해상도 등을 종합적으로 고려하여 최적의 세팅값을 찾아야 한다. 자신의 디바이스에 따라 동일한 세팅값이 다른 결과를 산출할 수도 있다.
my_plot <- ggplot(mpg, aes(x = displ, y = hwy, color = drv)) +
geom_point() +
labs(
title = "Larger engine sizes tend to have lower fuel economy",
caption = "Source: https://fueleconomy.gov."
) +
theme(
legend.position = c(0.6, 0.7),
legend.direction = "horizontal",
plot.title = element_text(face = "bold"),
plot.title.position = "plot",
plot.caption.position = "plot",
plot.caption = element_text(hjust = 0)
)
ggsave(filename = "my_plot.jpg", plot = my_plot, width = 8, height = 8 * 0.618, dpi = 600)3.4 CHEET SHEET
Posit에서는 ggplot2의 핵심을 간추린 2페이지짜리 CHEET SHEET를 제공하고 있다. ggplot2를 사용하여 작업할 때, 옆에 켜놓고 작업을 하면 도움이 된다.