Lab_05: 데이터 변형하기
개요
여기서는 R로 데이터사이언스를 하는 과정 중 데이터 변형하기(transformation)를 다룬다. 그림 1 에서 볼 수 있는 것처럼, 데이터 변형하기는 데이터사이언스 프로세스의 핵심적인 분석 부분의 구성요소이다.
데이터 변형하기와 관련된 대부분의 함수는 tidyverse의 핵심 패키지 중의 하나인 dplyr 에서 제공된다. 데이터 변형하기는 크게 다음의 두 가지 범주로 나뉜다.
단일 테이블 조작: 데이터 변형하기의 핵심 부분으로, 한 데이터 프레임의 데이터 구조를 조작한다.
다중 테이블 결합: 두 개 이상의 데이터 프레임을 결합하는 방식을 다룬다.
두 가지 모두 데이터 테이블이 입력되고, 데이터 테이블이 출력된다.
우선 tidyverse 패키지를 불러온다.
1 단일 테이블 조작
단일 테이블 조작과 관련된 함수는 다시 네 가지로 범주화된다.
행 함수: 행(관측 개체)에 작동하는 함수, 즉 행의 변화를 야기하는 함수
열 함수: 열(변수)에 작동하는 함수, 즉 열의 변화를 야기하는 함수
그룹 함수: 그룹에 작동하는 함수
데이터 프레임 함수: 데이터 프레임 전체에 작동하는 함수
이번 실습에서는 행 함수, 열 함수, 그룹 함수에 집중한다. 사용할 데이터는 World Bank가 gapmider.org를 통해 무료로 배포하는 것으로 gapmider 패키지에 포함되어 있다. gapmider 패키지를 인스톨하고 불러온다. 데이터가 어떻게 구성되어 있는지 살펴본다.
# A tibble: 1,704 × 6
country continent year lifeExp pop gdpPercap
<fct> <fct> <int> <dbl> <int> <dbl>
1 Afghanistan Asia 1952 28.8 8425333 779.
2 Afghanistan Asia 1957 30.3 9240934 821.
3 Afghanistan Asia 1962 32.0 10267083 853.
4 Afghanistan Asia 1967 34.0 11537966 836.
5 Afghanistan Asia 1972 36.1 13079460 740.
6 Afghanistan Asia 1977 38.4 14880372 786.
7 Afghanistan Asia 1982 39.9 12881816 978.
8 Afghanistan Asia 1987 40.8 13867957 852.
9 Afghanistan Asia 1992 41.7 16317921 649.
10 Afghanistan Asia 1997 41.8 22227415 635.
# ℹ 1,694 more rows1.1 행 함수
1.1.1 filter() 함수
특정 열(변수)과 관련된 조건을 만족하는 행을 선정한다. 행의 길이가 준다.
gapminder |>
filter(continent == "Europe")# A tibble: 360 × 6
country continent year lifeExp pop gdpPercap
<fct> <fct> <int> <dbl> <int> <dbl>
1 Albania Europe 1952 55.2 1282697 1601.
2 Albania Europe 1957 59.3 1476505 1942.
3 Albania Europe 1962 64.8 1728137 2313.
4 Albania Europe 1967 66.2 1984060 2760.
5 Albania Europe 1972 67.7 2263554 3313.
6 Albania Europe 1977 68.9 2509048 3533.
7 Albania Europe 1982 70.4 2780097 3631.
8 Albania Europe 1987 72 3075321 3739.
9 Albania Europe 1992 71.6 3326498 2497.
10 Albania Europe 1997 73.0 3428038 3193.
# ℹ 350 more rowsgapminder |>
filter(pop > 50000000 & gdpPercap > 30000)# A tibble: 9 × 6
country continent year lifeExp pop gdpPercap
<fct> <fct> <int> <dbl> <int> <dbl>
1 France Europe 2007 80.7 61083916 30470.
2 Germany Europe 2002 78.7 82350671 30036.
3 Germany Europe 2007 79.4 82400996 32170.
4 Japan Asia 2007 82.6 127467972 31656.
5 United Kingdom Europe 2007 79.4 60776238 33203.
6 United States Americas 1992 76.1 256894189 32004.
7 United States Americas 1997 76.8 272911760 35767.
8 United States Americas 2002 77.3 287675526 39097.
9 United States Americas 2007 78.2 301139947 42952.gapminder |>
filter(year == 2007 & (lifeExp > 82 | gdpPercap > 40000))# A tibble: 7 × 6
country continent year lifeExp pop gdpPercap
<fct> <fct> <int> <dbl> <int> <dbl>
1 Hong Kong, China Asia 2007 82.2 6980412 39725.
2 Ireland Europe 2007 78.9 4109086 40676.
3 Japan Asia 2007 82.6 127467972 31656.
4 Kuwait Asia 2007 77.6 2505559 47307.
5 Norway Europe 2007 80.2 4627926 49357.
6 Singapore Asia 2007 80.0 4553009 47143.
7 United States Americas 2007 78.2 301139947 42952.
1.1.2 slice() 함수
filter() 함수와 마찬가지로 행의 숫자를 줄인다. slice() 함수 자체 보다는 slice_head(), slice_tail(), slice_max(), slice_min()과 같은 패밀리 함수가 더 널리 사용된다. 그런데 이 함수들은 작동 방식에 따라 두 가지로 구분된다.
특정 열(변수)과 관계 없이, 행의 위치에 의거해 행을 선정:
slice(),slice_head(),slice_tail()특정 열(변수)에 따른, 행의 위치에 의거해 행을 선정:
slice_max(),slice_min()
몇 번째에서 몇 번째 사이의 행만을 골라낸다.
gapminder |>
slice(1:5)# A tibble: 5 × 6
country continent year lifeExp pop gdpPercap
<fct> <fct> <int> <dbl> <int> <dbl>
1 Afghanistan Asia 1952 28.8 8425333 779.
2 Afghanistan Asia 1957 30.3 9240934 821.
3 Afghanistan Asia 1962 32.0 10267083 853.
4 Afghanistan Asia 1967 34.0 11537966 836.
5 Afghanistan Asia 1972 36.1 13079460 740.가장 앞에 위치한 몇 개(n)의 행만을 골라낸다. 실질적으로 위와 동일하다.
gapminder |>
slice_head(n = 5)# A tibble: 5 × 6
country continent year lifeExp pop gdpPercap
<fct> <fct> <int> <dbl> <int> <dbl>
1 Afghanistan Asia 1952 28.8 8425333 779.
2 Afghanistan Asia 1957 30.3 9240934 821.
3 Afghanistan Asia 1962 32.0 10267083 853.
4 Afghanistan Asia 1967 34.0 11537966 836.
5 Afghanistan Asia 1972 36.1 13079460 740.가장 뒤에 위치한 몇 개(n)의 행만을 골라낸다.
gapminder |>
slice_tail(n = 5)# A tibble: 5 × 6
country continent year lifeExp pop gdpPercap
<fct> <fct> <int> <dbl> <int> <dbl>
1 Zimbabwe Africa 1987 62.4 9216418 706.
2 Zimbabwe Africa 1992 60.4 10704340 693.
3 Zimbabwe Africa 1997 46.8 11404948 792.
4 Zimbabwe Africa 2002 40.0 11926563 672.
5 Zimbabwe Africa 2007 43.5 12311143 470.특정 열(변수)에 따라 값이 가장 큰 몇 개(n)의 행만을 골라낸다.
# A tibble: 5 × 6
country continent year lifeExp pop gdpPercap
<fct> <fct> <int> <dbl> <int> <dbl>
1 Norway Europe 2007 80.2 4627926 49357.
2 Kuwait Asia 2007 77.6 2505559 47307.
3 Singapore Asia 2007 80.0 4553009 47143.
4 United States Americas 2007 78.2 301139947 42952.
5 Ireland Europe 2007 78.9 4109086 40676.특정 열(변수)에 따라 값이 가장 작은 것들 중 주어진 비중(prop) 만큼의 행만을 골라낸다.
# A tibble: 3 × 6
country continent year lifeExp pop gdpPercap
<fct> <fct> <int> <dbl> <int> <dbl>
1 Afghanistan Asia 2007 43.8 31889923 975.
2 Iraq Asia 2007 59.5 27499638 4471.
3 Cambodia Asia 2007 59.7 14131858 1714.slice 함수는 데이터 프레임이 적용되는 것으로 모두 데이터 프레임을 산출한다. 그런데 유사한 작업을 벡터에 적용하는 함수들이 존재한다. slice_head(), slice_tail(), slice()에 대응하는 dplyr 벡터 함수로 first(), last(), nth()가 있다. 그런데 후자의 함수를 벡터가 아닌 데이터 프레임이 적용하면 slice 함수와 동일한 결과가 산출된다.
1.1.3 arrange() 함수
특정 열(변수)과 관련된 조건에 의거해 행의 순서를 바꾼다. 행의 길이에는 변화가 없다.
gapminder |>
arrange(lifeExp)# A tibble: 1,704 × 6
country continent year lifeExp pop gdpPercap
<fct> <fct> <int> <dbl> <int> <dbl>
1 Rwanda Africa 1992 23.6 7290203 737.
2 Afghanistan Asia 1952 28.8 8425333 779.
3 Gambia Africa 1952 30 284320 485.
4 Angola Africa 1952 30.0 4232095 3521.
5 Sierra Leone Africa 1952 30.3 2143249 880.
6 Afghanistan Asia 1957 30.3 9240934 821.
7 Cambodia Asia 1977 31.2 6978607 525.
8 Mozambique Africa 1952 31.3 6446316 469.
9 Sierra Leone Africa 1957 31.6 2295678 1004.
10 Burkina Faso Africa 1952 32.0 4469979 543.
# ℹ 1,694 more rowsdesc() 보조 함수(helper function)는 내림차순으로 행을 배열한다.
# A tibble: 1,704 × 6
country continent year lifeExp pop gdpPercap
<fct> <fct> <int> <dbl> <int> <dbl>
1 Rwanda Africa 1992 23.6 7290203 737.
2 Afghanistan Asia 1952 28.8 8425333 779.
3 Gambia Africa 1952 30 284320 485.
4 Angola Africa 1952 30.0 4232095 3521.
5 Sierra Leone Africa 1952 30.3 2143249 880.
6 Afghanistan Asia 1957 30.3 9240934 821.
7 Cambodia Asia 1977 31.2 6978607 525.
8 Mozambique Africa 1952 31.3 6446316 469.
9 Sierra Leone Africa 1957 31.6 2295678 1004.
10 Burkina Faso Africa 1952 32.0 4469979 543.
# ℹ 1,694 more rows
1.1.4 distinct() 함수
특정 열(변수)에 의거해 중복이 없이 고유한 행만을 골라낸다. 행의 길이가 준다.
gapminder 데이터와 관련하여 다음의 코드는 어떤 정보를 우리에게 주는지 생각해 본다.
gapminder |>
distinct(country)# A tibble: 142 × 1
country
<fct>
1 Afghanistan
2 Albania
3 Algeria
4 Angola
5 Argentina
6 Australia
7 Austria
8 Bahrain
9 Bangladesh
10 Belgium
# ℹ 132 more rows.keep_all 아규먼트를 이용하면 나머지 열도 함께 나타낼 수 있다. 나머지 열의 값이 무엇인지 생각해 본다.
gapminder |>
distinct(continent, .keep_all = TRUE)# A tibble: 5 × 6
country continent year lifeExp pop gdpPercap
<fct> <fct> <int> <dbl> <int> <dbl>
1 Afghanistan Asia 1952 28.8 8425333 779.
2 Albania Europe 1952 55.2 1282697 1601.
3 Algeria Africa 1952 43.1 9279525 2449.
4 Argentina Americas 1952 62.5 17876956 5911.
5 Australia Oceania 1952 69.1 8691212 10040.1.2 열 함수
1.2.1 select() 함수
열(변수)의 일부를 선택한다. 열의 길이가 준다.
gapminder |>
select(year, country, gdpPercap)# A tibble: 1,704 × 3
year country gdpPercap
<int> <fct> <dbl>
1 1952 Afghanistan 779.
2 1957 Afghanistan 821.
3 1962 Afghanistan 853.
4 1967 Afghanistan 836.
5 1972 Afghanistan 740.
6 1977 Afghanistan 786.
7 1982 Afghanistan 978.
8 1987 Afghanistan 852.
9 1992 Afghanistan 649.
10 1997 Afghanistan 635.
# ℹ 1,694 more rows열(변수)의 일부를 선택하지 않는다. 역시 열의 길이가 준다. 실질적으로 위와 동일한 결과가 산출된다. ! 부호 대신 - 부호를 사용할 수 있다. 전자가 선호된다.
# A tibble: 1,704 × 3
country year gdpPercap
<fct> <int> <dbl>
1 Afghanistan 1952 779.
2 Afghanistan 1957 821.
3 Afghanistan 1962 853.
4 Afghanistan 1967 836.
5 Afghanistan 1972 740.
6 Afghanistan 1977 786.
7 Afghanistan 1982 978.
8 Afghanistan 1987 852.
9 Afghanistan 1992 649.
10 Afghanistan 1997 635.
# ℹ 1,694 more rowsstarts_with(), ends_with(), contains()와 같은 보조 함수를 잘 활용하면 효율적으로 필요한 변수만을 선정할 수 있다.
gapminder |>
select(starts_with("c"))# A tibble: 1,704 × 2
country continent
<fct> <fct>
1 Afghanistan Asia
2 Afghanistan Asia
3 Afghanistan Asia
4 Afghanistan Asia
5 Afghanistan Asia
6 Afghanistan Asia
7 Afghanistan Asia
8 Afghanistan Asia
9 Afghanistan Asia
10 Afghanistan Asia
# ℹ 1,694 more rows
1.2.2 mutate() 함수
기존의 열(변수)에 기반하여 새로운 변수를 생성한다. 열의 길이가 늘어난다.
gapminder |>
mutate(
gdp_billion = gdpPercap * pop / 10^9
)# A tibble: 1,704 × 7
country continent year lifeExp pop gdpPercap gdp_billion
<fct> <fct> <int> <dbl> <int> <dbl> <dbl>
1 Afghanistan Asia 1952 28.8 8425333 779. 6.57
2 Afghanistan Asia 1957 30.3 9240934 821. 7.59
3 Afghanistan Asia 1962 32.0 10267083 853. 8.76
4 Afghanistan Asia 1967 34.0 11537966 836. 9.65
5 Afghanistan Asia 1972 36.1 13079460 740. 9.68
6 Afghanistan Asia 1977 38.4 14880372 786. 11.7
7 Afghanistan Asia 1982 39.9 12881816 978. 12.6
8 Afghanistan Asia 1987 40.8 13867957 852. 11.8
9 Afghanistan Asia 1992 41.7 16317921 649. 10.6
10 Afghanistan Asia 1997 41.8 22227415 635. 14.1
# ℹ 1,694 more rows여러개의 변수를 동시에 생성할 수 있다. row_number() 보조 함수는 값에 순위를 부여하는 것이고, .keep = "used"는 결과에 변수 생성에 동원된 변수만을 포함시키게 해 준다.
gapminder |>
filter(year == 2007) |>
mutate(
gdpPercap_rank = row_number(gdpPercap),
lifeExp_highlow = lifeExp > 30000,
.keep = "used"
)# A tibble: 142 × 4
lifeExp gdpPercap gdpPercap_rank lifeExp_highlow
<dbl> <dbl> <int> <lgl>
1 43.8 975. 19 FALSE
2 76.4 5937. 70 FALSE
3 72.3 6223. 72 FALSE
4 42.7 4797. 64 FALSE
5 75.3 12779. 101 FALSE
6 81.2 34435. 130 FALSE
7 79.8 36126. 132 FALSE
8 75.6 29796. 122 FALSE
9 64.1 1391. 30 FALSE
10 79.4 33693. 128 FALSE
# ℹ 132 more rowsdplyr 패키지는 데이터에 순위를 부여하는 여러 가지 방식을 제공하는데, row_number(), min_rank(), dense_rank(), percent_rank(), cumu_dist() 등이 있다. 자세한 사항은 맨 아래에 있는 기타 벡터 함수를 참고하면 된다.
1.2.3 rename() 함수
변수의 이름을 바꾼다. 열의 길이에는 변화가 없다. = 부호의 왼쪽에 있는 것이 새로운 변수명이다.
gapminder |>
rename(
gdp_percap = gdpPercap,
left_exp = lifeExp
)# A tibble: 1,704 × 6
country continent year left_exp pop gdp_percap
<fct> <fct> <int> <dbl> <int> <dbl>
1 Afghanistan Asia 1952 28.8 8425333 779.
2 Afghanistan Asia 1957 30.3 9240934 821.
3 Afghanistan Asia 1962 32.0 10267083 853.
4 Afghanistan Asia 1967 34.0 11537966 836.
5 Afghanistan Asia 1972 36.1 13079460 740.
6 Afghanistan Asia 1977 38.4 14880372 786.
7 Afghanistan Asia 1982 39.9 12881816 978.
8 Afghanistan Asia 1987 40.8 13867957 852.
9 Afghanistan Asia 1992 41.7 16317921 649.
10 Afghanistan Asia 1997 41.8 22227415 635.
# ℹ 1,694 more rows패밀리 함수인 rename_with()를 이용하면 다른 것도 가능하다. tolower은 변수명을 소문자로 바꾸는 보조 함수이고, toupper은 대문자로 바꾸는 보조 함수이다.
gapminder |>
rename_with(
tolower, starts_with("l")
)# A tibble: 1,704 × 6
country continent year lifeexp pop gdpPercap
<fct> <fct> <int> <dbl> <int> <dbl>
1 Afghanistan Asia 1952 28.8 8425333 779.
2 Afghanistan Asia 1957 30.3 9240934 821.
3 Afghanistan Asia 1962 32.0 10267083 853.
4 Afghanistan Asia 1967 34.0 11537966 836.
5 Afghanistan Asia 1972 36.1 13079460 740.
6 Afghanistan Asia 1977 38.4 14880372 786.
7 Afghanistan Asia 1982 39.9 12881816 978.
8 Afghanistan Asia 1987 40.8 13867957 852.
9 Afghanistan Asia 1992 41.7 16317921 649.
10 Afghanistan Asia 1997 41.8 22227415 635.
# ℹ 1,694 more rows
1.2.4 relocate() 함수
변수의 위치를 바꾼다. 열의 길이에는 변화가 없다. 기입한 변수들이 맨 앞으로 이동한다.
gapminder |>
relocate(year, continent)# A tibble: 1,704 × 6
year continent country lifeExp pop gdpPercap
<int> <fct> <fct> <dbl> <int> <dbl>
1 1952 Asia Afghanistan 28.8 8425333 779.
2 1957 Asia Afghanistan 30.3 9240934 821.
3 1962 Asia Afghanistan 32.0 10267083 853.
4 1967 Asia Afghanistan 34.0 11537966 836.
5 1972 Asia Afghanistan 36.1 13079460 740.
6 1977 Asia Afghanistan 38.4 14880372 786.
7 1982 Asia Afghanistan 39.9 12881816 978.
8 1987 Asia Afghanistan 40.8 13867957 852.
9 1992 Asia Afghanistan 41.7 16317921 649.
10 1997 Asia Afghanistan 41.8 22227415 635.
# ℹ 1,694 more rows.before나 .after 아규먼트를 사용하여 해당 변수를 어떤 변수의 앞이나 뒤로 보낼 수 있다.
gapminder |>
relocate(pop, .before = lifeExp )# A tibble: 1,704 × 6
country continent year pop lifeExp gdpPercap
<fct> <fct> <int> <int> <dbl> <dbl>
1 Afghanistan Asia 1952 8425333 28.8 779.
2 Afghanistan Asia 1957 9240934 30.3 821.
3 Afghanistan Asia 1962 10267083 32.0 853.
4 Afghanistan Asia 1967 11537966 34.0 836.
5 Afghanistan Asia 1972 13079460 36.1 740.
6 Afghanistan Asia 1977 14880372 38.4 786.
7 Afghanistan Asia 1982 12881816 39.9 978.
8 Afghanistan Asia 1987 13867957 40.8 852.
9 Afghanistan Asia 1992 16317921 41.7 649.
10 Afghanistan Asia 1997 22227415 41.8 635.
# ℹ 1,694 more rows
1.2.5 pull() 함수
데이터 프레임의 한 컬럼을 벡터로 추출한다.
Base R이 벡터 기반 연산에 강점이 있는 반면 tidyverse는 데이터 프레임별 연산에 강점이 있다. 이렇다 보니 Base R의 많은 벡터 기반 함수를 tidyverse에서 사용할 때 불편함을 느낄 수 있다. 이러한 문제점을 경감해 줄 수 있는 것이 pull() 함수이다. 예를 들어 위의 코드를 Base R에서 쓰면 다음과 같다.
mean(gapminder$lifeExp)동일한 것을 정규 tidyverse문법에 맞추어 쓰면 다음과 같다.
좀 성가시게 길어지는 측면이 있다. 이 때 pull() 함수는 유용하게 사용될 수 있고, tidyverse문법을 지키면서도 코드를 좀 더 간명하게 표현할 수 있다.
1.3 그룹 함수
1.3.1 group_by() 함수
특정 범주 열(변수)에 의거해 행을 분할한다. 행의 길이는 변하지 않는다.
우선 하나의 범주 변수에 의거해 그룹화한다. 산출물을 보면 year에 의거해 행이 12개의 그룹으로 나누어졌음을 알 수 있다(두 번째 줄: Group: year [12]).
gapminder |>
group_by(year)# A tibble: 1,704 × 6
# Groups: year [12]
country continent year lifeExp pop gdpPercap
<fct> <fct> <int> <dbl> <int> <dbl>
1 Afghanistan Asia 1952 28.8 8425333 779.
2 Afghanistan Asia 1957 30.3 9240934 821.
3 Afghanistan Asia 1962 32.0 10267083 853.
4 Afghanistan Asia 1967 34.0 11537966 836.
5 Afghanistan Asia 1972 36.1 13079460 740.
6 Afghanistan Asia 1977 38.4 14880372 786.
7 Afghanistan Asia 1982 39.9 12881816 978.
8 Afghanistan Asia 1987 40.8 13867957 852.
9 Afghanistan Asia 1992 41.7 16317921 649.
10 Afghanistan Asia 1997 41.8 22227415 635.
# ℹ 1,694 more rows두 개 이상의 범주 변수에 의거해 그룹화할 수도 있다.
gapminder |>
group_by(year, continent)# A tibble: 1,704 × 6
# Groups: year, continent [60]
country continent year lifeExp pop gdpPercap
<fct> <fct> <int> <dbl> <int> <dbl>
1 Afghanistan Asia 1952 28.8 8425333 779.
2 Afghanistan Asia 1957 30.3 9240934 821.
3 Afghanistan Asia 1962 32.0 10267083 853.
4 Afghanistan Asia 1967 34.0 11537966 836.
5 Afghanistan Asia 1972 36.1 13079460 740.
6 Afghanistan Asia 1977 38.4 14880372 786.
7 Afghanistan Asia 1982 39.9 12881816 978.
8 Afghanistan Asia 1987 40.8 13867957 852.
9 Afghanistan Asia 1992 41.7 16317921 649.
10 Afghanistan Asia 1997 41.8 22227415 635.
# ℹ 1,694 more rows
1.3.2 summarize() 함수
주어진 열(변수)에 대한 통계 요약값을 계산하고 그것으로 이루어진 새로운 데이터 프레임을 생성한다. 엄밀히 말해 기존 열(변수)을 변형한다기 보다는 기존 데이터 프레임으로부터 새로운 데이터 프레임을 생성한다고 볼 수 있다. summarize() 함수는 대부분의 경우 group_by() 함수와 함께 사용된다. 다음의 둘을 비교해 보라.
# A tibble: 1 × 1
mean_gdpPercap
<dbl>
1 11680.# A tibble: 5 × 2
continent mean_gdpPercap
<fct> <dbl>
1 Africa 3089.
2 Americas 11003.
3 Asia 12473.
4 Europe 25054.
5 Oceania 29810.좀 더 복잡한 확장이 가능하다. 마지막의 n()은 특별한 요약 함수로, 어떤 아규먼트도 없이 단독으로 사용되며 “현재(current)” 그룹의 빈도값을 산출한다.
# A tibble: 60 × 7
# Groups: continent [5]
continent year mean_gdpPercap sd_gdpPercap mean_pop sd_pop n
<fct> <int> <dbl> <dbl> <dbl> <dbl> <int>
1 Africa 1952 1253. 983. 4570010. 6317450. 52
2 Africa 1957 1385. 1135. 5093033. 7076042. 52
3 Africa 1962 1598. 1462. 5702247. 7957545. 52
4 Africa 1967 2050. 2848. 6447875. 8985505. 52
5 Africa 1972 2340. 3287. 7305376. 10130833. 52
6 Africa 1977 2586. 4142. 8328097. 11585184. 52
7 Africa 1982 2482. 3243. 9602857. 13456243. 52
8 Africa 1987 2283. 2567. 11054502. 15277484. 52
9 Africa 1992 2282. 2644. 12674645. 17562719. 52
10 Africa 1997 2379. 2821. 14304480. 19873013. 52
# ℹ 50 more rowsgroup_by()와 arrange()를 결합하는 경우, .by_group = TRUE를 하면 그룹별로 행을 배열할 수 있다(그렇지 않으면 그룹 설정을 무시한 채 행을 배열한다.)
# A tibble: 1,704 × 6
# Groups: year, continent [60]
country continent year lifeExp pop gdpPercap
<fct> <fct> <int> <dbl> <int> <dbl>
1 South Africa Africa 1952 45.0 14264935 4725.
2 Gabon Africa 1952 37.0 420702 4293.
3 Angola Africa 1952 30.0 4232095 3521.
4 Reunion Africa 1952 52.7 257700 2719.
5 Djibouti Africa 1952 34.8 63149 2670.
6 Algeria Africa 1952 43.1 9279525 2449.
7 Namibia Africa 1952 41.7 485831 2424.
8 Libya Africa 1952 42.7 1019729 2388.
9 Congo, Rep. Africa 1952 42.1 854885 2126.
10 Mauritius Africa 1952 51.0 516556 1968.
# ℹ 1,694 more rows아래는 연도별/대륙별로 일인당 GDP가 가장 높은 국가를 추출한 것이다. 코드를 생각해 보라.
# A tibble: 60 × 6
# Groups: year, continent [60]
country continent year lifeExp pop gdpPercap
<fct> <fct> <int> <dbl> <int> <dbl>
1 South Africa Africa 1952 45.0 14264935 4725.
2 United States Americas 1952 68.4 157553000 13990.
3 Kuwait Asia 1952 55.6 160000 108382.
4 Switzerland Europe 1952 69.6 4815000 14734.
5 New Zealand Oceania 1952 69.4 1994794 10557.
6 South Africa Africa 1957 48.0 16151549 5487.
7 United States Americas 1957 69.5 171984000 14847.
8 Kuwait Asia 1957 58.0 212846 113523.
9 Switzerland Europe 1957 70.6 5126000 17909.
10 New Zealand Oceania 1957 70.3 2229407 12247.
# ℹ 50 more rowsgroup_by() 함수가 한 번 적용되면, 그 뒤의 모든 오퍼레이션에 그룹 분할이 적용되기 때문에 예기치 못한 일이 발생할 수 있다. 이것을 회피하기 위해 두 가지 옵션이 있다. 첫번째 방법은 마지막에 upgroup() 함수를 첨가하는 것이다. 아래에 위 질문에 대한 정답이 나타나 있다.
# A tibble: 60 × 6
country continent year lifeExp pop gdpPercap
<fct> <fct> <int> <dbl> <int> <dbl>
1 South Africa Africa 1952 45.0 14264935 4725.
2 United States Americas 1952 68.4 157553000 13990.
3 Kuwait Asia 1952 55.6 160000 108382.
4 Switzerland Europe 1952 69.6 4815000 14734.
5 New Zealand Oceania 1952 69.4 1994794 10557.
6 South Africa Africa 1957 48.0 16151549 5487.
7 United States Americas 1957 69.5 171984000 14847.
8 Kuwait Asia 1957 58.0 212846 113523.
9 Switzerland Europe 1957 70.6 5126000 17909.
10 New Zealand Oceania 1957 70.3 2229407 12247.
# ℹ 50 more rows두 번째 방법은 group_by() 함수 대신 by 아규먼트를 사용하는 것이다. 결과가 달라보이겠지만 정렬의 차이일 뿐 동일하다.
# A tibble: 60 × 6
country continent year lifeExp pop gdpPercap
<fct> <fct> <int> <dbl> <int> <dbl>
1 Kuwait Asia 1952 55.6 160000 108382.
2 Kuwait Asia 1957 58.0 212846 113523.
3 Kuwait Asia 1962 60.5 358266 95458.
4 Kuwait Asia 1967 64.6 575003 80895.
5 Kuwait Asia 1972 67.7 841934 109348.
6 Kuwait Asia 1977 69.3 1140357 59265.
7 Saudi Arabia Asia 1982 63.0 11254672 33693.
8 Kuwait Asia 1987 74.2 1891487 28118.
9 Kuwait Asia 1992 75.2 1418095 34933.
10 Kuwait Asia 1997 76.2 1765345 40301.
# ℹ 50 more rows
1.3.3 count() 함수
특정 범주 열(변수)에 의거한 빈도를 빠르게 계산해 준다. 빈도는 자동적으로 n이라는 이럼의 컬럼에 저장된다.
gapminder |>
count(year, continent)# A tibble: 60 × 3
year continent n
<int> <fct> <int>
1 1952 Africa 52
2 1952 Americas 25
3 1952 Asia 33
4 1952 Europe 30
5 1952 Oceania 2
6 1957 Africa 52
7 1957 Americas 25
8 1957 Asia 33
9 1957 Europe 30
10 1957 Oceania 2
# ℹ 50 more rowswt 아규먼트를 사용하면 빈도가 아니라 범주별 특정 변수의 합산값을 구할 수 있다.
gapminder |>
count(year, continent, wt = pop)# A tibble: 60 × 3
year continent n
<int> <fct> <dbl>
1 1952 Africa 237640501
2 1952 Americas 345152446
3 1952 Asia 1395357351
4 1952 Europe 418120846
5 1952 Oceania 10686006
6 1957 Africa 264837738
7 1957 Americas 386953916
8 1957 Asia 1562780599
9 1957 Europe 437890351
10 1957 Oceania 11941976
# ℹ 50 more rows위의 두 개는 사실 아래와 동일하다.
# A tibble: 60 × 4
# Groups: year [12]
year continent n sum_pop
<int> <fct> <int> <dbl>
1 1952 Africa 52 237640501
2 1952 Americas 25 345152446
3 1952 Asia 33 1395357351
4 1952 Europe 30 418120846
5 1952 Oceania 2 10686006
6 1957 Africa 52 264837738
7 1957 Americas 25 386953916
8 1957 Asia 33 1562780599
9 1957 Europe 30 437890351
10 1957 Oceania 2 11941976
# ℹ 50 more rows
1.3.4 across() 함수
다수의 열(변수)에 동일한 함수를 적용할 수 있다.
# A tibble: 1,704 × 6
country continent year lifeExp pop gdpPercap
<fct> <fct> <int> <dbl> <int> <dbl>
1 Afghanistan Asia 1952 29 8425333 779
2 Afghanistan Asia 1957 30 9240934 821
3 Afghanistan Asia 1962 32 10267083 853
4 Afghanistan Asia 1967 34 11537966 836
5 Afghanistan Asia 1972 36 13079460 740
6 Afghanistan Asia 1977 38 14880372 786
7 Afghanistan Asia 1982 40 12881816 978
8 Afghanistan Asia 1987 41 13867957 852
9 Afghanistan Asia 1992 42 16317921 649
10 Afghanistan Asia 1997 42 22227415 635
# ℹ 1,694 more rows이것은 다음과 동일하다.
# A tibble: 1,704 × 6
country continent year lifeExp pop gdpPercap
<fct> <fct> <int> <dbl> <int> <dbl>
1 Afghanistan Asia 1952 29 8425333 779
2 Afghanistan Asia 1957 30 9240934 821
3 Afghanistan Asia 1962 32 10267083 853
4 Afghanistan Asia 1967 34 11537966 836
5 Afghanistan Asia 1972 36 13079460 740
6 Afghanistan Asia 1977 38 14880372 786
7 Afghanistan Asia 1982 40 12881816 978
8 Afghanistan Asia 1987 41 13867957 852
9 Afghanistan Asia 1992 42 16317921 649
10 Afghanistan Asia 1997 42 22227415 635
# ℹ 1,694 more rowssummarize() 함수와 결합하여 선택된 변수에 특정 함수를 적용하고 그 결과의 이름을 변수명과 함수명을 사용하여 부여할 수 있다.
# A tibble: 60 × 4
# Groups: year [12]
year continent mean_lifeExp mean_gdpPercap
<int> <fct> <dbl> <dbl>
1 1952 Africa 39.1 1253.
2 1952 Americas 53.3 4079.
3 1952 Asia 46.3 5195.
4 1952 Europe 64.4 5661.
5 1952 Oceania 69.3 10298.
6 1957 Africa 41.3 1385.
7 1957 Americas 56.0 4616.
8 1957 Asia 49.3 5788.
9 1957 Europe 66.7 6963.
10 1957 Oceania 70.3 11599.
# ℹ 50 more rowsacross() 함수에서 중요한 것은 함수 아규먼트에 함수명 그 자체만 쓸 수 있을 뿐(즉, mean), 함수명 뒤에 ()가 붙을 수 없다. 예를 들어 mean() 함수의 매우 중요한 아규먼트인 na.rm을 사용할 수 없다. 위의 예에서 두 변수 중 어느 변수에라도 결측값이 포함되어 있었다면 에러가 발생했을 것이다. 이 문제는 다음과 같은 방식으로 해결할 수 있다.
# A tibble: 60 × 4
# Groups: year [12]
year continent lifeExp gdpPercap
<int> <fct> <dbl> <dbl>
1 1952 Africa 38.8 987.
2 1952 Americas 54.7 3048.
3 1952 Asia 44.9 1207.
4 1952 Europe 65.9 5142.
5 1952 Oceania 69.3 10298.
6 1957 Africa 40.6 1024.
7 1957 Americas 56.1 3781.
8 1957 Asia 48.3 1548.
9 1957 Europe 67.6 6067.
10 1957 Oceania 70.3 11599.
# ℹ 50 more rows혹은 보다 간단하게 function()을 \()로 대체할 수도 있다.
# A tibble: 60 × 4
# Groups: year [12]
year continent lifeExp gdpPercap
<int> <fct> <dbl> <dbl>
1 1952 Africa 38.8 987.
2 1952 Americas 54.7 3048.
3 1952 Asia 44.9 1207.
4 1952 Europe 65.9 5142.
5 1952 Oceania 69.3 10298.
6 1957 Africa 40.6 1024.
7 1957 Americas 56.1 3781.
8 1957 Asia 48.3 1548.
9 1957 Europe 67.6 6067.
10 1957 Oceania 70.3 11599.
# ℹ 50 more rows만일 across() 함수 속에서 두 개 이상의 함수를 적용한다면 list()를 활용해야 한다. 결과에 새로 생성된 변수명이 원변수명_함수명({.col}_{.fn})의 형태를 띠고 있음에 주목하라. 사실 이것은 across() 함수 속에 .names = "{.col}_{.fn}"라고 지정한 것과 동일한 것으로, 만일 .names = "{.fn}_{.col}" 이라고 지정하면 다른 결과가 나타날 것이다.
# A tibble: 60 × 6
# Groups: year [12]
year continent lifeExp_mean lifeExp_median gdpPercap_mean gdpPercap_median
<int> <fct> <dbl> <dbl> <dbl> <dbl>
1 1952 Africa 39.1 38.8 1253. 987.
2 1952 Americas 53.3 54.7 4079. 3048.
3 1952 Asia 46.3 44.9 5195. 1207.
4 1952 Europe 64.4 65.9 5661. 5142.
5 1952 Oceania 69.3 69.3 10298. 10298.
6 1957 Africa 41.3 40.6 1385. 1024.
7 1957 Americas 56.0 56.1 4616. 3781.
8 1957 Asia 49.3 48.3 5788. 1548.
9 1957 Europe 66.7 67.6 6963. 6067.
10 1957 Oceania 70.3 70.3 11599. 11599.
# ℹ 50 more rowsacross() 함수의 파생 함수로 if_any()와 if_all()이 있다. 두 함수 모두 매우 유용하지만 여기서는 다루지 않는다.
1.3.5 c_across() 함수
group_by() 함수와 across() 함수가 결합하는 것과 정반대로, rowwise() 함수와 c_across() 함수를 결합하며, 행별 통계값을 산출할 수 있다. 물론 여기서 each_sd 값은 아무런 의미가 없다. 행별로 수치형 변수(year, lifeExp, pop, gdpPercap)의 표준편차를 구한 것이다.
# A tibble: 1,704 × 7
# Rowwise:
country continent year lifeExp pop gdpPercap each_sd
<fct> <fct> <int> <dbl> <int> <dbl> <dbl>
1 Afghanistan Asia 1952 28.8 8425333 779. 4212207.
2 Afghanistan Asia 1957 30.3 9240934 821. 4619999.
3 Afghanistan Asia 1962 32.0 10267083 853. 5133067.
4 Afghanistan Asia 1967 34.0 11537966 836. 5768510.
5 Afghanistan Asia 1972 36.1 13079460 740. 6539272.
6 Afghanistan Asia 1977 38.4 14880372 786. 7439719.
7 Afghanistan Asia 1982 39.9 12881816 978. 6440408.
8 Afghanistan Asia 1987 40.8 13867957 852. 6933499.
9 Afghanistan Asia 1992 41.7 16317921 649. 8158513.
10 Afghanistan Asia 1997 41.8 22227415 635. 11113262.
# ℹ 1,694 more rows대륙별로 기대수명이 가장 높은 국가 찾기
2007년을 기준으로, 각 대륙의 평균 기대수명과 기대수명이 가장 높은 국가 1개를 찾아보시오.
결과로는 5개 대륙을 행으로 갖는 데이터셋을 기대수명이 높은 순서대로 정렬하시오.
결과에는 continent, country, lifeExp, avg_lifeExp(평균기대수명) 열만 표시하시오.
# A tibble: 5 × 4
# Groups: continent [5]
continent country avg_lifeExp lifeExp
<fct> <fct> <dbl> <dbl>
1 Asia Japan 70.7 82.6
2 Europe Iceland 77.6 81.8
3 Oceania Australia 80.7 81.2
4 Americas Canada 73.6 80.7
5 Africa Reunion 54.8 76.42 다중 테이블 결합
2.1 테이블 조인
테이블 조인(join)은 두 개 데이터 프레임을 공통키(common key)를 이용해 결합함으로써 하나의 데이터 프레임을 생성하는 것을 의미한다. 서로 상이한 방식의 조인이 가능하면, dplyr 패키지는 다양한 종류의 조인 함수를 제공한다.
left_join(): 첫 번째 테이블은 그대로 둔 상태에서 두 번째 테이블을 결합함으로써 두 번째 변수의 열을 가져옴right_join(): 두 번째 테이블은 그대로 둔 상태에서 첫 번째 테이블을 결합함으로써 첫 번째 테이블의 열을 가져옴inner_join(): 두 테이블 모두에 존재하는 열을 취함full_join(): 최소한 한 테이블에 존재하는 열을 모두 취함semi_join(): 첫 번째 테이블의 행 중 두 번째 테이블에 대응하는 행이 있는 것만 취함anti_join(): 첫 번째 테이블의 행 중 두 번째 테이블에 대응하는 행이 없는 것만 취함
이들 중 left_join()이 가장 많이 사용되기 때문에 그것에 집중한다.
2.1.1 left_join() 함수
실습을 위해 nycflights13 패키지의 데이터를 사용한다. 이 패키지에는 다섯 개의 데이터 프레임이 포함되어 있다. 지난 번에는 첫 번째 데이터만 사용했다.
flights: 2013년 NYC를 출발한 모든 항공기weather: 공항별 시간별 기상 상황planes: 항공기별 건조 정보airports: 공항명과 위치airlines: 항공사
그리고 이 6개의 데이터 프레임은 그림 2 처럼 공통키(common key)를 통해 서로 연결되어 있다.
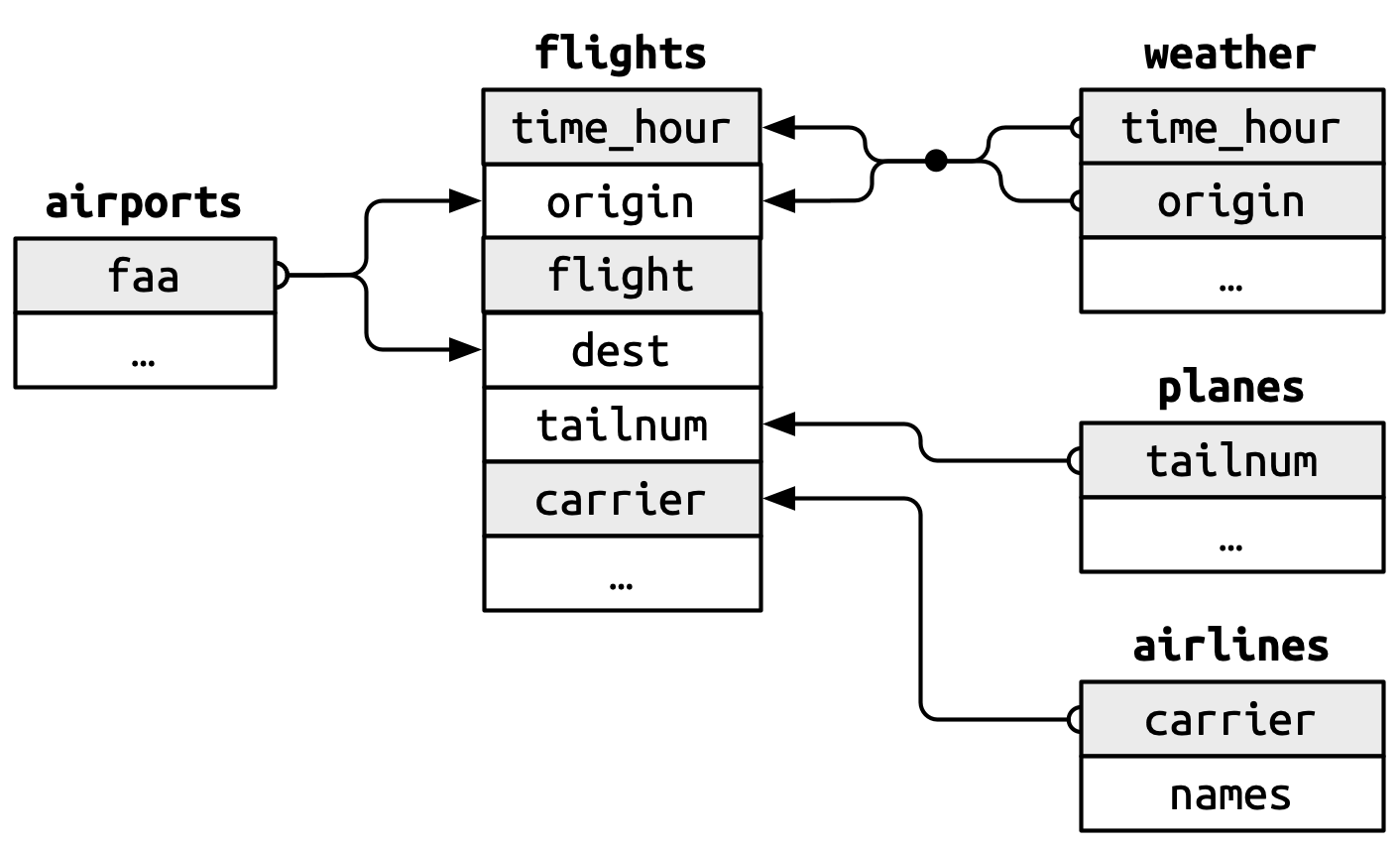
nycflights13 데이터(https://github.com/tidyverse/nycflights13)
flights 데이터의 변수가 너무 많기 때문에 조인을 위한 공통키를 중심으로 변수를 줄인다.
flights2 <- flights |>
select(year, time_hour, origin, dest, tailnum, carrier)
flights2# A tibble: 336,776 × 6
year time_hour origin dest tailnum carrier
<int> <dttm> <chr> <chr> <chr> <chr>
1 2013 2013-01-01 05:00:00 EWR IAH N14228 UA
2 2013 2013-01-01 05:00:00 LGA IAH N24211 UA
3 2013 2013-01-01 05:00:00 JFK MIA N619AA AA
4 2013 2013-01-01 05:00:00 JFK BQN N804JB B6
5 2013 2013-01-01 06:00:00 LGA ATL N668DN DL
6 2013 2013-01-01 05:00:00 EWR ORD N39463 UA
7 2013 2013-01-01 06:00:00 EWR FLL N516JB B6
8 2013 2013-01-01 06:00:00 LGA IAD N829AS EV
9 2013 2013-01-01 06:00:00 JFK MCO N593JB B6
10 2013 2013-01-01 06:00:00 LGA ORD N3ALAA AA
# ℹ 336,766 more rowsflights2 데이터를 중심으로 나머지 4개의 데이터와 조인한다.
airlines# A tibble: 16 × 2
carrier name
<chr> <chr>
1 9E Endeavor Air Inc.
2 AA American Airlines Inc.
3 AS Alaska Airlines Inc.
4 B6 JetBlue Airways
5 DL Delta Air Lines Inc.
6 EV ExpressJet Airlines Inc.
7 F9 Frontier Airlines Inc.
8 FL AirTran Airways Corporation
9 HA Hawaiian Airlines Inc.
10 MQ Envoy Air
11 OO SkyWest Airlines Inc.
12 UA United Air Lines Inc.
13 US US Airways Inc.
14 VX Virgin America
15 WN Southwest Airlines Co.
16 YV Mesa Airlines Inc. flights2 |>
left_join(airlines)# A tibble: 336,776 × 7
year time_hour origin dest tailnum carrier name
<int> <dttm> <chr> <chr> <chr> <chr> <chr>
1 2013 2013-01-01 05:00:00 EWR IAH N14228 UA United Air Lines Inc.
2 2013 2013-01-01 05:00:00 LGA IAH N24211 UA United Air Lines Inc.
3 2013 2013-01-01 05:00:00 JFK MIA N619AA AA American Airlines Inc.
4 2013 2013-01-01 05:00:00 JFK BQN N804JB B6 JetBlue Airways
5 2013 2013-01-01 06:00:00 LGA ATL N668DN DL Delta Air Lines Inc.
6 2013 2013-01-01 05:00:00 EWR ORD N39463 UA United Air Lines Inc.
7 2013 2013-01-01 06:00:00 EWR FLL N516JB B6 JetBlue Airways
8 2013 2013-01-01 06:00:00 LGA IAD N829AS EV ExpressJet Airlines I…
9 2013 2013-01-01 06:00:00 JFK MCO N593JB B6 JetBlue Airways
10 2013 2013-01-01 06:00:00 LGA ORD N3ALAA AA American Airlines Inc.
# ℹ 336,766 more rowsweather# A tibble: 26,115 × 15
origin year month day hour temp dewp humid wind_dir wind_speed
<chr> <int> <int> <int> <int> <dbl> <dbl> <dbl> <dbl> <dbl>
1 EWR 2013 1 1 1 39.0 26.1 59.4 270 10.4
2 EWR 2013 1 1 2 39.0 27.0 61.6 250 8.06
3 EWR 2013 1 1 3 39.0 28.0 64.4 240 11.5
4 EWR 2013 1 1 4 39.9 28.0 62.2 250 12.7
5 EWR 2013 1 1 5 39.0 28.0 64.4 260 12.7
6 EWR 2013 1 1 6 37.9 28.0 67.2 240 11.5
7 EWR 2013 1 1 7 39.0 28.0 64.4 240 15.0
8 EWR 2013 1 1 8 39.9 28.0 62.2 250 10.4
9 EWR 2013 1 1 9 39.9 28.0 62.2 260 15.0
10 EWR 2013 1 1 10 41 28.0 59.6 260 13.8
# ℹ 26,105 more rows
# ℹ 5 more variables: wind_gust <dbl>, precip <dbl>, pressure <dbl>,
# visib <dbl>, time_hour <dttm># A tibble: 336,776 × 8
year time_hour origin dest tailnum carrier temp wind_speed
<int> <dttm> <chr> <chr> <chr> <chr> <dbl> <dbl>
1 2013 2013-01-01 05:00:00 EWR IAH N14228 UA 39.0 12.7
2 2013 2013-01-01 05:00:00 LGA IAH N24211 UA 39.9 15.0
3 2013 2013-01-01 05:00:00 JFK MIA N619AA AA 39.0 15.0
4 2013 2013-01-01 05:00:00 JFK BQN N804JB B6 39.0 15.0
5 2013 2013-01-01 06:00:00 LGA ATL N668DN DL 39.9 16.1
6 2013 2013-01-01 05:00:00 EWR ORD N39463 UA 39.0 12.7
7 2013 2013-01-01 06:00:00 EWR FLL N516JB B6 37.9 11.5
8 2013 2013-01-01 06:00:00 LGA IAD N829AS EV 39.9 16.1
9 2013 2013-01-01 06:00:00 JFK MCO N593JB B6 37.9 13.8
10 2013 2013-01-01 06:00:00 LGA ORD N3ALAA AA 39.9 16.1
# ℹ 336,766 more rowsplanes# A tibble: 3,322 × 9
tailnum year type manufacturer model engines seats speed engine
<chr> <int> <chr> <chr> <chr> <int> <int> <int> <chr>
1 N10156 2004 Fixed wing multi… EMBRAER EMB-… 2 55 NA Turbo…
2 N102UW 1998 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
3 N103US 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
4 N104UW 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
5 N10575 2002 Fixed wing multi… EMBRAER EMB-… 2 55 NA Turbo…
6 N105UW 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
7 N107US 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
8 N108UW 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
9 N109UW 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
10 N110UW 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
# ℹ 3,312 more rows# A tibble: 336,776 × 9
year time_hour origin dest tailnum carrier type engines seats
<int> <dttm> <chr> <chr> <chr> <chr> <chr> <int> <int>
1 2013 2013-01-01 05:00:00 EWR IAH N14228 UA Fixed w… 2 149
2 2013 2013-01-01 05:00:00 LGA IAH N24211 UA Fixed w… 2 149
3 2013 2013-01-01 05:00:00 JFK MIA N619AA AA Fixed w… 2 178
4 2013 2013-01-01 05:00:00 JFK BQN N804JB B6 Fixed w… 2 200
5 2013 2013-01-01 06:00:00 LGA ATL N668DN DL Fixed w… 2 178
6 2013 2013-01-01 05:00:00 EWR ORD N39463 UA Fixed w… 2 191
7 2013 2013-01-01 06:00:00 EWR FLL N516JB B6 Fixed w… 2 200
8 2013 2013-01-01 06:00:00 LGA IAD N829AS EV Fixed w… 2 55
9 2013 2013-01-01 06:00:00 JFK MCO N593JB B6 Fixed w… 2 200
10 2013 2013-01-01 06:00:00 LGA ORD N3ALAA AA <NA> NA NA
# ℹ 336,766 more rowsairports# A tibble: 1,458 × 8
faa name lat lon alt tz dst tzone
<chr> <chr> <dbl> <dbl> <dbl> <dbl> <chr> <chr>
1 04G Lansdowne Airport 41.1 -80.6 1044 -5 A America/…
2 06A Moton Field Municipal Airport 32.5 -85.7 264 -6 A America/…
3 06C Schaumburg Regional 42.0 -88.1 801 -6 A America/…
4 06N Randall Airport 41.4 -74.4 523 -5 A America/…
5 09J Jekyll Island Airport 31.1 -81.4 11 -5 A America/…
6 0A9 Elizabethton Municipal Airport 36.4 -82.2 1593 -5 A America/…
7 0G6 Williams County Airport 41.5 -84.5 730 -5 A America/…
8 0G7 Finger Lakes Regional Airport 42.9 -76.8 492 -5 A America/…
9 0P2 Shoestring Aviation Airfield 39.8 -76.6 1000 -5 U America/…
10 0S9 Jefferson County Intl 48.1 -123. 108 -8 A America/…
# ℹ 1,448 more rows# A tibble: 336,776 × 13
year time_hour origin dest tailnum carrier name lat lon
<int> <dttm> <chr> <chr> <chr> <chr> <chr> <dbl> <dbl>
1 2013 2013-01-01 05:00:00 EWR IAH N14228 UA Newark Li… 40.7 -74.2
2 2013 2013-01-01 05:00:00 LGA IAH N24211 UA La Guardia 40.8 -73.9
3 2013 2013-01-01 05:00:00 JFK MIA N619AA AA John F Ke… 40.6 -73.8
4 2013 2013-01-01 05:00:00 JFK BQN N804JB B6 John F Ke… 40.6 -73.8
5 2013 2013-01-01 06:00:00 LGA ATL N668DN DL La Guardia 40.8 -73.9
6 2013 2013-01-01 05:00:00 EWR ORD N39463 UA Newark Li… 40.7 -74.2
7 2013 2013-01-01 06:00:00 EWR FLL N516JB B6 Newark Li… 40.7 -74.2
8 2013 2013-01-01 06:00:00 LGA IAD N829AS EV La Guardia 40.8 -73.9
9 2013 2013-01-01 06:00:00 JFK MCO N593JB B6 John F Ke… 40.6 -73.8
10 2013 2013-01-01 06:00:00 LGA ORD N3ALAA AA La Guardia 40.8 -73.9
# ℹ 336,766 more rows
# ℹ 4 more variables: alt <dbl>, tz <dbl>, dst <chr>, tzone <chr>airports의 경우만 왜 join_by()라는 아규먼트가 사용되었는데, 이 경우에는 공통키의 이름이 동일하지 않기 때문이다. 즉, flights2 데이터의 origin 컬럼과 airports 데이터의 faa가 공통키임을 지정해 주어야 하는 것이다.
2.2 테이블 병합
테이블 병합(merge)은 두 데이터 프레임을 결합해 새로운 단일한 데이터 프레임을 생성한다는 의미에서는 테이블 조인과 동일하지만, 공통키가 없으며, 행과 열 중 하나는 만드시 동일해야 한다. 가장 널리 사용되는 함수에 bind_row() 함수와 bind_col() 함수가 있다. 전자는 컬럼이 동일한 두 테이블을 상하로 연결하는 것이고, 후자는 행이 동일한 두 테이블을 좌우로 연결하는 것이다.
2.2.1 bind_row() 와 bind_col() 함수
gapminder 데이터를 25년 간격으로 세 개의 연도(1957, 1982, 2007년)로 분할한다.
이 세개의 데이터 프레임은 동일한 열 구조(동일한 변수)를 가지고 있지만, 행이 다르다. 이런 경우 bind_row() 함수를 사용하여 하나의 데이터 프레임으로 결합할 수 있다.
gapminder_merge_row <- bind_rows(
gap_1957, gap_1982, gap_2007
)
gapminder_merge_row# A tibble: 426 × 6
country continent year lifeExp pop gdpPercap
<fct> <fct> <int> <dbl> <int> <dbl>
1 Afghanistan Asia 1957 30.3 9240934 821.
2 Albania Europe 1957 59.3 1476505 1942.
3 Algeria Africa 1957 45.7 10270856 3014.
4 Angola Africa 1957 32.0 4561361 3828.
5 Argentina Americas 1957 64.4 19610538 6857.
6 Australia Oceania 1957 70.3 9712569 10950.
7 Austria Europe 1957 67.5 6965860 8843.
8 Bahrain Asia 1957 53.8 138655 11636.
9 Bangladesh Asia 1957 39.3 51365468 662.
10 Belgium Europe 1957 69.2 8989111 9715.
# ℹ 416 more rows이제 gapminder 데이터 프레임을 변수 세 개씩 묶어 두 개의 데이터 프레임으로 분할한다.
이 두개의 데이터 프레임은 동일한 행 구조(동일한 관측 개체)를 가지고 있지만, 열이 다르다. 이런 경우 bind_col() 함수를 사용하여 하나의 데이터 프레임으로 결합할 수 있다.
gapminder_merge_col <- bind_cols(gap_var1, gap_var2)
gapminder_merge_col# A tibble: 1,704 × 6
country continent year lifeExp pop gdpPercap
<fct> <fct> <int> <dbl> <int> <dbl>
1 Afghanistan Asia 1952 28.8 8425333 779.
2 Afghanistan Asia 1957 30.3 9240934 821.
3 Afghanistan Asia 1962 32.0 10267083 853.
4 Afghanistan Asia 1967 34.0 11537966 836.
5 Afghanistan Asia 1972 36.1 13079460 740.
6 Afghanistan Asia 1977 38.4 14880372 786.
7 Afghanistan Asia 1982 39.9 12881816 978.
8 Afghanistan Asia 1987 40.8 13867957 852.
9 Afghanistan Asia 1992 41.7 16317921 649.
10 Afghanistan Asia 1997 41.8 22227415 635.
# ℹ 1,694 more rows2.2.2 기타 집합 연산 함수
집합 연산(set operation) 함수란 두 데이터 프레임을 수학적 집합 연산(합집합, 교집합, 차집합, 동등성 검사)을 적용하여 새로운 데이터 프레임을 산출하는 함수를 말한다. 두 데이터 프레임은 동일한 열 구조를 가져야 하며, 행 전체를 하나의 원소로 취급한다. 여기에 해당하는 함수로, intersect(), union(), setdiff() 함수 등이 있다.
3 기타 벡터 함수
타이디버스 함수의 기본 작동 방식은 데이터 프레임을 입력으로 받아 데이터 프레임을 출력하는 것이다. 이에 반해 Base R은 기본적으로 벡터에 대한 연산에 기반하고 있다. 타이디버스의 이러한 측면은 주로 장점으로 작용한다고 볼 수 있지만, 단점으로 작용하는 경우도 적지 않다. 이를 극복하기 위해 dplyr 패키지는 몇 가지 유용한 벡터 함수를 제공하고 있다. 이러한 함수는 주로 단일 테이블 조작 함수의 내부에서 작동한다.
| 범주 | 함수 | 설명 |
|---|---|---|
| 값 추출 | first() |
첫 번째 값 |
last() |
마지막 값 | |
nth() |
n-번째 값 | |
| 값 변경 | if_else() |
단일 벡터에 대해, 이진 조건식을 통해 재코드화 |
case_match() |
단일 벡터에 대해, 조건식을 통해 재코드화 | |
case_when() |
다중 벡터에 대해, 조건식을 통해 재코드화 | |
| 순위 부여 | row_number() |
일련번호 부여 |
min_rank() |
동일값에 동순위를 부여하고, 그 다음 값에는 동순위 갯수를 감안한 그 다음 순위를 부여 | |
dense_rank() |
동일값에 동순위를 부여하고, 그 다음 값에는 동순위 갯수에 상관없이 바로 그 다음 순위를 부여 | |
percent_rank() |
백분위수(percentile)을 계산해 주는데, 해당 값보다 작은 값의 개수를 전체 개수에서 1을 뺀 값으로 나눈값을 산출 | |
cume_dist() |
백분위수(percentile)을 계산해 주는데, 해당 값보다 작거나 같은 값의 개수를 전체 개수로 나눈값을 산출 | |
ntile() |
값의 크기에 따라 몇 개의 그룹으로 나누고, 그룹 순위를 부여 | |
consecutive_id() |
동일한 값에는 동일한 일련번호를, 새로운 값이 나타날 때에는 그 다음 일련번호를 부여 | |
| 값 순서 변경 | desc() |
내림차순으로 정렬 |
lag() |
뒤로 밀어 이전 값을 가져옴. 첫번째 값이 NA | |
lead() |
앞으로 당겨서 이후 값을 가져옴. 마지막 값이 NA | |
| 결측치 처리 | coalesce() |
NA에 특정한 값을 부여 |
na_if() |
특정한 값에 NA를 부여 | |
| 논리형 벡터 생성 | between() |
특정한 값이 두 값 사이에 존재하는 지의 여부 검토 |
near() |
두 값이 충분히 가까운지의 여부 검토 |
3.1 값 추출 함수
first() 함수는 해당 벡터의 첫 번째 셀 값을 반환한다. last() 함수는 해당 벡터의 마지막 셀 값을 반환한다. nth() 함수는 해당 벡터의 n-번째 셀 값을 반환한다. 주로 summarize() 함수와 함께 사용된다. 아래의 사례는 대륙별로 1인당 GDP가 가장 큰 국가와 가장 작은 국가를 추출한 것이다.
# A tibble: 5 × 3
continent country_first country_last
<fct> <fct> <fct>
1 Africa Gabon Congo, Dem. Rep.
2 Americas United States Haiti
3 Asia Kuwait Myanmar
4 Europe Norway Albania
5 Oceania Australia New Zealand 유사한 기능을 하는 데이터 프레임 함수로 slice_head(), slice_tail(), slice() 함수가 있다. 궁극적인 차이점은 이 함수들은 특정한 행(들)으로 구성된 데이터 프레임을 반환한다는 것이다.
3.2 값 변경 함수
if_else() 함수는 값 변경 함수 중 가장 빈번하게 사용되는 것으로, 주로 단일 벡터에 대해, 이진 조건식을 통해 해당 변수의 값을 변경하는 것이다.
# A tibble: 2 × 2
gdp_status n
<chr> <int>
1 high 33
2 low 109위의 사례는 수치형 변수를 범주형 변수로 바꾸는 것으로 보통 재코드화(recode)라고 불리는 연산이다. 두 개 이상의 범주로 분할하는 경우에도 if_else() 함수를 사용할 수 있지만, 이 경우는 case_when() 함수가 더 유용하다.
# A tibble: 3 × 2
gdp_status n
<chr> <int>
1 High 33
2 Low 49
3 Medium 60case_when() 함수는 조건식에 두 개 이상의 변수를 포함할 수 있다.
# A tibble: 3 × 2
overall_status n
<chr> <int>
1 Medium 113
2 Really Bad 16
3 Really Good 13case_match() 함수는 범주의 개수를 줄이는데 유용하게 사용될 수 있다. .default 인수를 통해 부여된 조건식에 해당하지 않는 나머지 모든 케이스에 대해 어떤 값을 부여할지를 결정할 수 있다. 이와 동일한 것을 case_when() 함수로도 가능하기 때문에 모든 경우에 대해 case_when() 함수를 활용하면 된다.
# A tibble: 2 × 2
gdp_status n
<dbl> <int>
1 1 109
2 2 333.3 순위 부여 함수
특정 벡터의 값을 기준으로 순위를 부여하고, 그 순위값으로 구성된 새로운 벡터를 생성하는 함수에 기본적으로 다음의 세 가지 방식이 있다.
row_number()함수는 동일값이라 하더라도 값의 등장 순서에 따라 서로 다른 순위를 부여한다. 예를 들어, 다섯개의 숫자가 있고 두 번째 순위 값이 두 개라고 했을 때, 1~5의 모든 순위가 존재한다.min_rank()함수는 동일값에 동순위를 부여하고, 그 다음 값에는 동순위 갯수를 감안한 그 다음 순위를 부여한다. 예를 들어, 다섯개의 숫자가 있고 두 번째 순위 값이 두 개라고 했을 때, 3은 없다.dense_rank()함수는 동일값에 동순위를 부여하고, 그 다음 값에는 동순위 갯수에 상관없이 바로 그 다음 순위를 부여한다 예를 들어, 다섯개의 숫자가 있고 두 번째 순위 값이 두 개라고 했을 때, 5는 없다.
tbl_rank <- tibble(x = c(10, 20, 20, 30, 40))
tbl_rank |>
mutate(
row_number = row_number(x),
min_rank = min_rank(x),
dense_rank = dense_rank(x)
)# A tibble: 5 × 4
x row_number min_rank dense_rank
<dbl> <int> <int> <int>
1 10 1 1 1
2 20 2 2 2
3 20 3 2 2
4 30 4 4 3
5 40 5 5 4이 외에 두 개의 부가적인 함수가 존재하는데, 백분위수(percentile)를 계산한다는 의미에서는 동일하지만 계산 방식이 조금 다르다.
percent_rank()함수: 백분위수을 계산해 주는데, 해당 값보다 작은 값의 개수를 전체 개수에서 1을 뺀 값으로 나눈값을 산출한다.cume_dist()함수: 백분위수를 계산해 주는데, 해당 값보다 작거나 같은 값의 개수를 전체 개수로 나눈값을 산출한다.
tbl_rank <- tibble(x = c(10, 20, 20, 30, 40))
tbl_rank |>
mutate(
percent_rank = percent_rank(x),
cume_dist = cume_dist(x)
)# A tibble: 5 × 3
x percent_rank cume_dist
<dbl> <dbl> <dbl>
1 10 0 0.2
2 20 0.25 0.6
3 20 0.25 0.6
4 30 0.75 0.8
5 40 1 1 3.4 값 순서 변경 함수
값 순서 변경 함수 중 가장 빈번하게 사용되는 것이 desc() 함수이다. 데이터 프레임 함수인 arrange()가 기본적으로 오름차순으로 정렬하는데, desc() 함수를 쓰면 내림차순으로 정렬할 수 있다.
# A tibble: 5 × 1
x
<dbl>
1 40
2 30
3 20
4 20
5 10lag()과 lead() 함수는 주어진 벡터를 행방향으로 한칸 이동한 새로운 벡터를 생성하는데 사용된다. lag() 함수는 뒤로 한칸 밀어 이전 값을 가져와서 새로운 벡터를 생성하는데, 새로 만들어진 벡터의 첫 번째 셀 값은 NA가 된다. 이에 반해 lead() 함수는 앞으로 한칸 당겨 이후 값을 가져와서 새로운 벡터를 생성하는데, 새로 만들어진 벡터의 마지막 셀 값은 NA가 된다.
# A tibble: 5 × 3
x x_lag x_lead
<dbl> <dbl> <dbl>
1 10 NA 20
2 20 10 20
3 20 20 30
4 30 20 40
5 40 30 NAdefault 인자를 활용하면 NA의 생성을 막을 수 있다.
3.5 결측치 처리 함수
결측치 처리 함수는 벡터의 NA값과 관련된 함수이다. coalesce() 함수는 NA에 특정한 값을 부여하는데 반해, na_if() 함수는 특정한 값에 NA를 부여하는 함수이다.
3.6 논리형 벡터 생성 함수
논리형 벡터 생성 함수는 조건의 부합 여부에 따라 TRUE와 FALSU로 구성된 새로운 벡터를 생성하는 함수를 의미한다. Base R에는 다음과 같은 논리형 벡터 생성 함수가 빈번하게 사용된다.
is.na(): 결측치 여부is.numeric(): 수치형 여부is.integer(): 정수형 여부is.character(): 문자형 여부is.logical(): 논리형 여부is.factor(): 팩터 여부
여기에 덧붙여 dplyr은 흥미로운 논리형 벡터 생성 함수를 제공한다.
# A tibble: 13 × 6
country continent year lifeExp pop gdpPercap
<fct> <fct> <int> <dbl> <int> <dbl>
1 Bahrain Asia 2007 75.6 708573 29796.
2 Czech Republic Europe 2007 76.5 10228744 22833.
3 Greece Europe 2007 79.5 10706290 27538.
4 Israel Asia 2007 80.7 6426679 25523.
5 Italy Europe 2007 80.5 58147733 28570.
6 Korea, Rep. Asia 2007 78.6 49044790 23348.
7 New Zealand Oceania 2007 80.2 4115771 25185.
8 Oman Asia 2007 75.6 3204897 22316.
9 Portugal Europe 2007 78.1 10642836 20510.
10 Saudi Arabia Asia 2007 72.8 27601038 21655.
11 Slovenia Europe 2007 77.9 2009245 25768.
12 Spain Europe 2007 80.9 40448191 28821.
13 Taiwan Asia 2007 78.4 23174294 28718.near() 함수는 많이 사용되지는 않지만, 부등소수점 수(floating point number)의 정확도로 인해 발생하는 상동성 평가의 문제점을 극복하기 위한 함수이다. 아래의 예시를 보자. 두 값은 명백히 1과 2이다.
그러나 다음의 상동성 평가 문제가 발생한다.
x == c(1, 2)[1] FALSE FALSE이것은 부등소수점 수의 정확도로 발생하는 문제이다.
print(x, digits = 16)[1] 0.9999999999999999 2.0000000000000004near() 함수는 이러한 미세한 차이를 무시할 수 있게 해주어 상동성 평가 문제를 해결한다.