1[1] 1R과 R Studio를 설치할 수 있다.
프로젝트와 스크립트를 생성하고, 관리할 수 있다.
R Studio의 구조 및 기본 사용법을 이해할 수 있다.
R은 실행과정에서 폴더 경로에 한글이 포함된 경우 오류가 자주 발생한다. 따라서 사용자 계정 이름이 한국어로 설정되어 있지 않은지 반드시 확인해야 하며, 앞으로 만들 프로젝트 폴더 등도 이름을 모두 영어로 설정하는 것이 좋다.
Windows: [설정] -> [계정] -> [사용자 정보]로 들어가 볼드체로 된 사용자 계정 이름이 영어인지 확인하기. 사용자 계정이 한국어로 설정되어 있다면 영어로 된 새로운 윈도우 사용자 계정을 만들어야 한다.
Mac: 프로젝트 폴더 이름 설정만 잘 신경쓰면 된다.
프로그램을 다운로드하기 위해 다음의 웹사이트로 이동한다. 여기는 RStudio를 만든 posit(과거에는 회사명 자체도 RStudio였음)이라는 회사가 관리하는 RStudio Desktop 다운로드 페이지이다.
그러면 그림 1 과 같이 R과 RStudio를 설치할 수 있는 화면이 나타날 것이다.
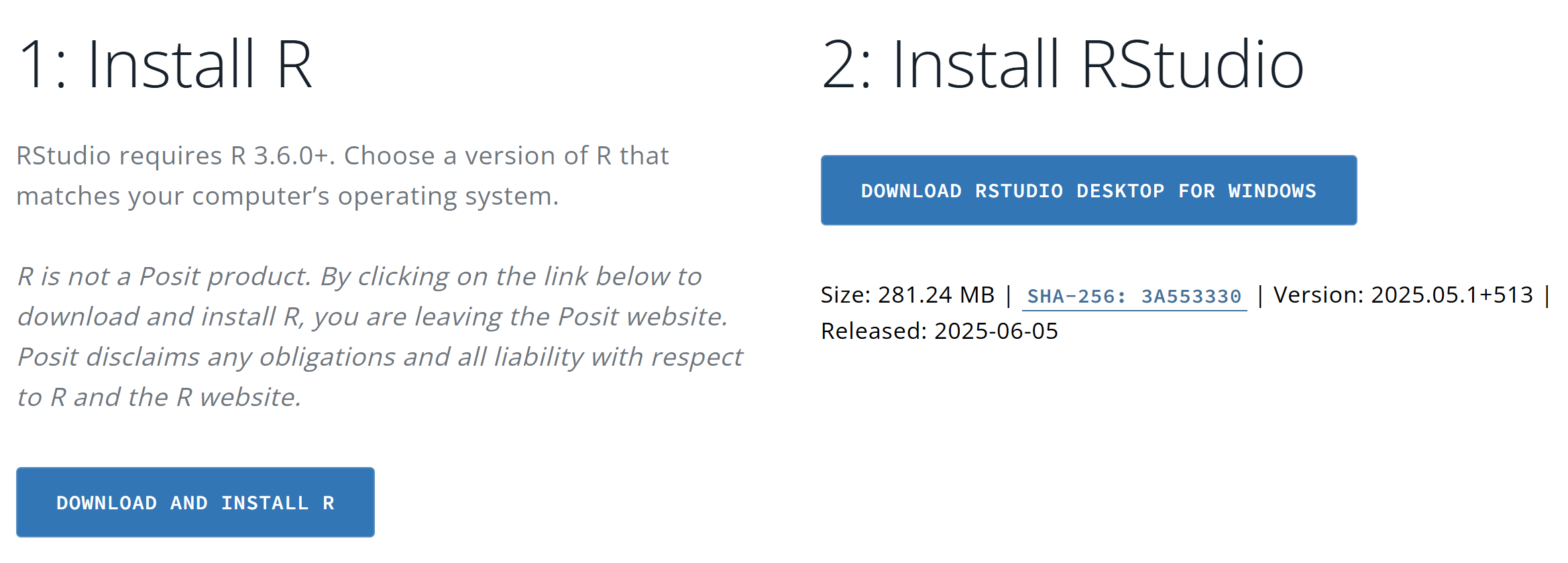
왼쪽의 다운로드 바를 클릭하면 CRAN(The Comprehensive R Archive Network)으로 이동한다. 자신의 운영체계에 맞는 R의 최신 버전을 다운로드하고 자신의 디바이스에 설치한다. 이 다큐먼트 작성 시점 기준으로 R의 최신 버전은 4.5.2이다.
R의 지배적인 IDE(Integrated Development Environment, 통합개발환경)인 RStudio를 설치한다. 다시 원래의 다운로드 페이지로 돌아와, 오른편의 다운로드 바를 클릭하면 윈도우즈용 RStudio의 파일을 다운로드할 수 있다. 스크롤 다운하면 다른 운영체계를 위한 RStudio를 다운로드할 수 있다. 다운받은 RStudio를 자신의 디바이스에 설치한다. 이 다큐먼트 작성 시점 기준으로 RStudio의 최신 버전은 2025년 9월에 발표된 2025.09.2+418이다.
RStudio는 R만을 위한 IDE인데, posit은 최근 R과 Python 모두를 사용할 수 있는 범용 IDE인 Positron을 개발하였다. 2025년 7월 3일에 베타 버전을 끝내고 정식 출시했으며, 현재는 2025년 12월 2일에 출시된 2025.12.2-5이 최신 버전이다. Positron은 RStudio와 Python에서 많이 사용되는 VS Code를 결합한 것으로, 향상된 기능과 외견이 기대된다. 2026년부터는 RStudio에서 Positron으로의 이동이 본격화될 것이다. Positron을 살펴보는데 다음 영상이 도움이 될 것이다. Positron 영상
R로 분석을 진행할 때, 프로젝트단위로 작업을 관리하는 것이 중요하다. 여기서 프로젝트란 하나의 분석이나 과제, 우리의 경우 실습을 수행하기 위해 필요한 데이터, 스크립트, 결과물을 모두 하나의 폴더 안에서 체계적으로 관리하는 작업방식이다. 따라서, 하나의 일관된 목적을 위해 이러한 다양한 일을 한다면, 이것들을 한데 모아 함께 관리하는 것이 좋을 것이다. 반면, 이질적인 과업을 하게 된다면 기존의 프로젝트 속에서 하기 보다는 또 다른 프로젝트를 만들어 그 속에서 하는 것이 효과적일 것이다.
효율적인 프로젝트 관리를 위해 다음과 같은 관행을 추천한다.
디바이스에 모든 R 프로젝트를 포괄하는 최상위 폴더를 만든다. 걸맞는 폴더명(예: R_Projects)을 부여한다. 이것은 R 외부에서 미리 해둔다. 물론 Output 창의 Files 탭을 이용하면 R 내부에서도 할 수 있다.
최상위 폴더 아래에 개별 R 프로젝트를 위한 폴더를 만든다. 과업에 걸맞는 폴더명(예: AI_Class_2026)을 부여한다. 이것을 R 외부에서 미리 해둘 수도 있고, R 내부에서 프로젝트를 생성할 때 할 수도 있다. 후자를 추천한다.
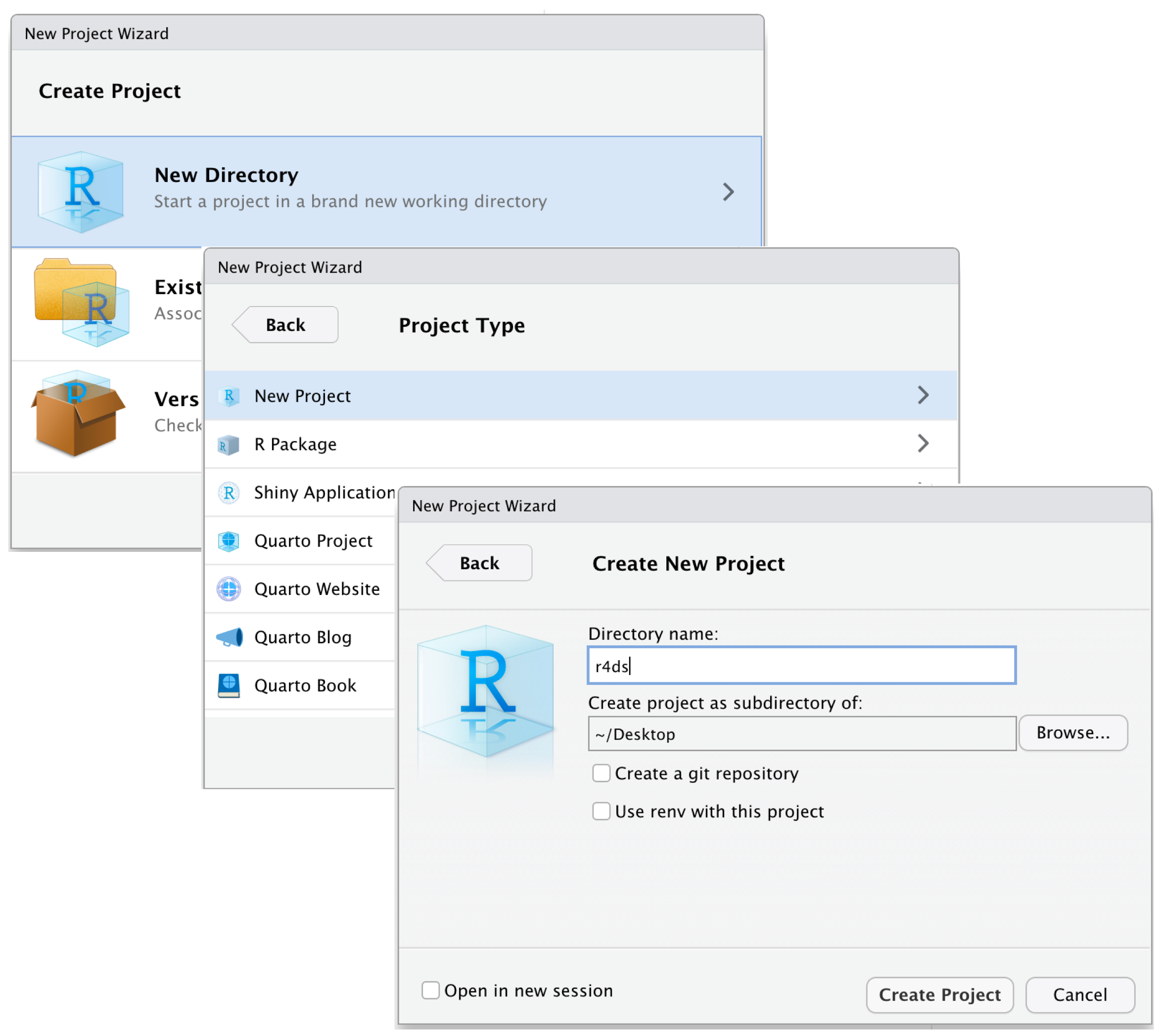
그림 2 에 나타나 있는 절차를 통해 프로젝트를 생성한다. 각각 다음의 단계를 거친다.
1단계: 과제 폴더(디렉토리)를 미리 만들어 두지 않았다면, New Directory를 선택한다(추천). 만들어 두었다면, Existing Directory를 선택한다.
2단계: New Project를 선택한다.
최상단 메뉴를 이용: File > New Project
상단 메뉴바 오른쪽 끝의 화살표 아이콘: New Project
Output 창의 Files 탭을 누르면, 다양한 기본 파일들이 해당 폴더에 생성되었음을 확인할 수 있다. 가장 중요한 파일은 .RProj라는 확장자를 가진 파일이다. 나중에 R 외부에서 이 파일을 더블클릭하면 R 프로젝트를 열 수 있다.
R 외부의 파일 관리 시스템(윈도우즈의 경우 파일 탐색기)를 사용하지 말고, Output 창의 Files 탭을 사용하는 것이 훨씬 유용하다. 파일 탐색기에서 제공하는 거의 대부분의 기능을 제공한다.
Rstudio의 기본 세팅값을 바꿀 수 있는 다양한 옵션이 존재한다. Tools > Global Options를 선택하면 그림 3 과 같은 화면을 볼 수 있을 것이다.
스크립트 파일을 생성하는 세 가지 정도의 방법이 있다.
File > New File > R Script 선택
File 메뉴 바로 아래의 New File 아이콘을 누른 후 R Script 선택
단축키(Ctrl + Shift + N) 실행 (Mac의 경우 Command + Shift + N)
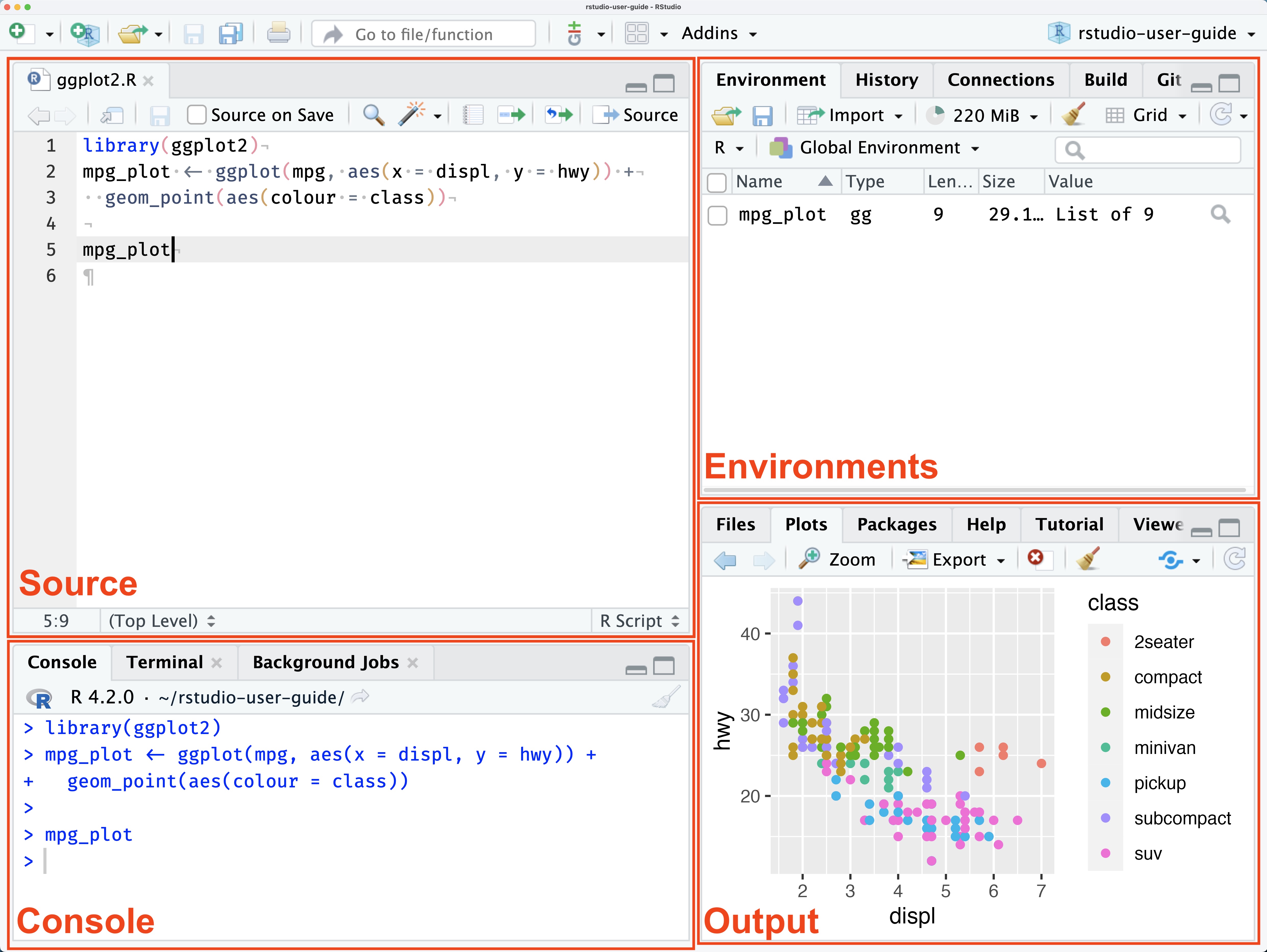
이렇게 하면 그림 4 과 같이 좌상에 Editor 창이 생성된다. 그 안에서 그림에서 보는 바와 같이 코드를 작성하게 된다.
스크립트 파일에 이름을 부여하고 저장한다.
File > Save 선택
Save current document 아이콘 클릭
단축키(Ctrl + S) 실행 (Mac의 경우 Command + S)
RStudio를 실행하면 아마도 대부분의 경우 그림 5 와 같은 화면을 보게 될 것이다. 크게 세 개의 창으로 구성되어 있음을 알 수 있다.
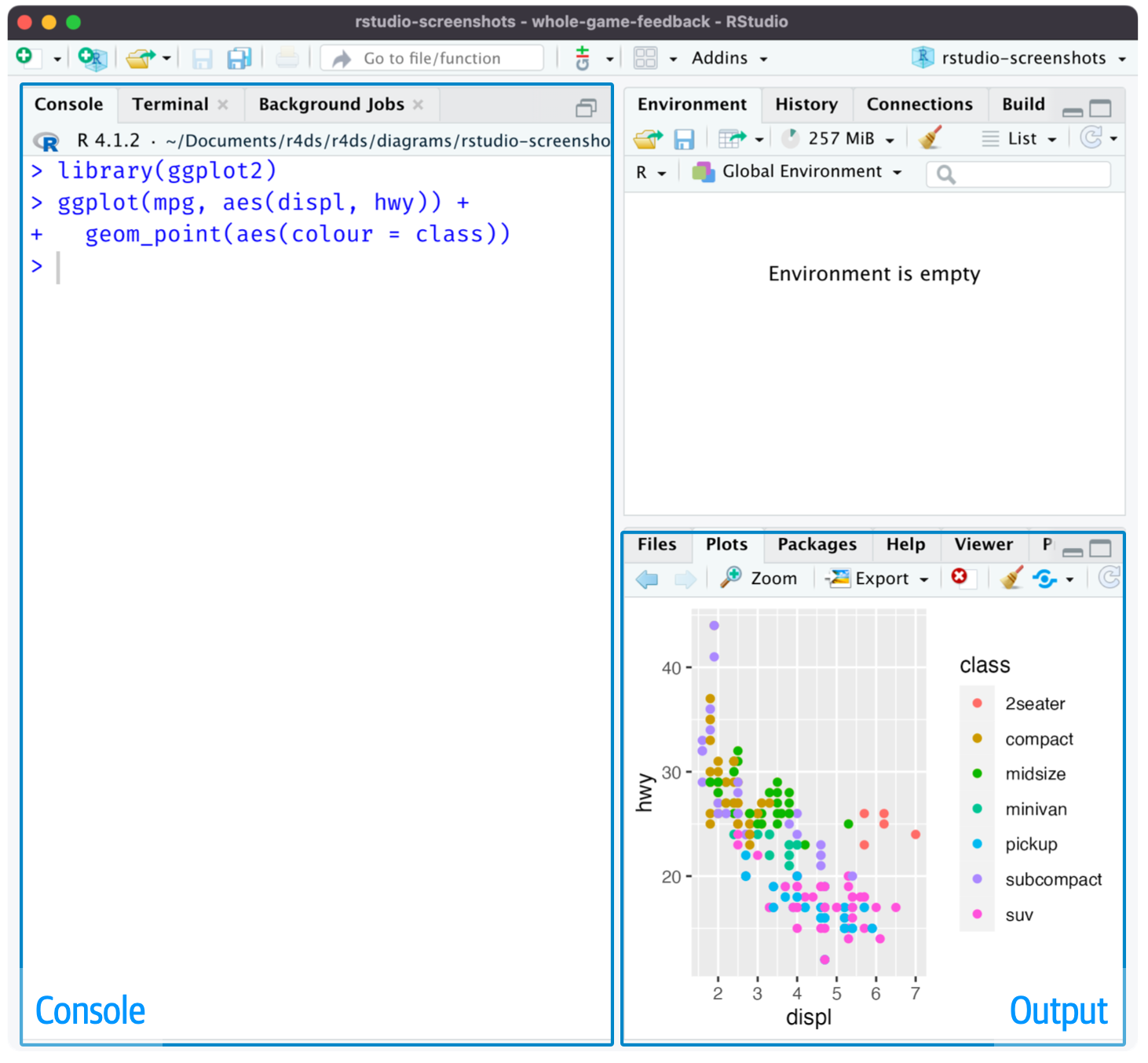
왼편에 가장 크게 나타나 있는 것을 Console 창(pane)이라고 부르고, 우하의 창은 Output 창 혹은 File 창이라고 부른다. 우상에도 또 다른 창이 하나 보이는데 보통 Environment 창이라고 부른다.
개별 창은 여러 개의 탭(tab)으로 구성되어 있는데, 탭의 기능이 매우 다양하기 때문에 소속 탭의 모든 기능을 포괄하는 일관성 있는 창 이름을 붙이는 것이 매우 어렵다. 예를 들어 Output 창의 경우 Plots와 Viewer 탭은 결과물을 보여주는 것이라 할 수 있지만 나머지 탭은 꼭 그렇지도 않다.
여기서는 Console 창을 통해 R의 가장 기본적인 다음의 개념들에 대해 알아보고자 한다. Console 창은 R에서 CLI(command-line interface, 명령줄(어) 인터페이스) 역할을 하는 가장 핵심적인 부분이다. 사용자가 프로그램을 통해 컴퓨터와 상호작용하는 인터페이스이다.
프롬프트(prompt): 명령 프롬프트(command prompt)라고도 불리는 것으로, CLI에서 명령어 대기 상태를 나타내는 일종의 부호이다. R에서는 >를 사용한다.
할당(assignment): 값을 식별자(identifier)를 가진 객체로 전환하는 과정을 의미한다. 프로그래밍 언어는 할당을 위한 고유한 연산자(operator)를 가지고 있는데, R은 <-을 사용한다. =도 동일한 기능을 하는데, 권장하지는 않는다.
객체(object): 값을 품고 있는, 식별자를 가진, 메모리 상의 기본 단위
함수(function): 특정 동작을 수행하는 코드 블록을 의미한다. 인풋을 함수에 적용하면 함수의 고유한 동작을 통해 아웃풋이 산출된다.
벡터(vector): 숫자의 일차원적 집합으로 보통 개별 행(row) 혹은 개별 열(column)을 의미한다.
데이터 프레임(data frame): 하나 이상의 벡터를 모아 둔 숫자의 2차원적 집합으로, 다수의 행과 다수의 열로 이루어진 테이블을 의미한다. 이것이 보통 우리가 데이터셋이라고 부르는 것이다.
콘솔 창에 R 프롬프트인 >가 나타나 있을 것이다. 아래와 같이 숫자 1을 타이핑하고 실행을 위해 [enter] 키를 누른다.
1[1] 1간단한 연산을 해본다. 사실 R은 기본적으로 계산기이다.
1 + 2[1] 3이제 할당 연산자(<-)를 활용하여 할당을 해보자.
a <- 1우상의 Environment 창을 보면 뭔가 생성된 것을 확인할 수 있을 것이다. a라는 객체가 생성되었으며 그것은 1이라는 값을 품고 있다는 의미이다. 이제 a는 알파벳 소문자가 아니라 1이라는 숫자와 필연적으로 결합해 있는 객체이다. 다음을 실행하면 이러한 사실을 보다 명확히 확인할 수 있다.
할당 연산자의 단축키는 Alt + _ 이다. 가장 많이 사용하게 될 단축키 중의 하나이다. 이 단축키를 사용하면 좋은 점 중의 하나는 전후에 빈 공간이 자동적으로 생성된다는 점이다. 따라서 객체 이름 다음에 할당 연산자를 사용하기 위해 스페이스바를 사용할 필요가 없다.
a[1] 1아래와 같이 하면 객체끼리의 연산이 가능하다.
b <- 2
c <- a + b
c[1] 3Base R에는 할당 연사자 외에도 여러 연산자가 존재한다. 이를 정리하면 다음과 같다.
| 범주 | 연산자 | 설명 | 예시 |
|---|---|---|---|
| 할당(assignment) 연산자 |
<- 혹은 ->
|
데이터를 객체에 할당 | a <- 5 |
| 수리(arithmetic) 연산자 | + |
더하기(addition) | 5 + 5 = 10 |
- |
빼기(subtraction) | 5 - 5 = 0 |
|
* |
곱하기(multiplication) | 2 * 8 = 16 |
|
/ |
나누기(division) | 100 / 10 = 10 |
|
^ 혹은 **
|
제곱(exponent/power) | 5^2 = 25 |
|
%% |
나머지(modulo) | 100 %% 15 = 10 |
|
%/% |
몫(integer division) | 100 %/% 15 = 6 |
|
| 관계(relational) 연산자 | x < y |
x가 y보다 작은 경우 | 3 < 4 TRUE
|
x > y |
x가 y보다 큰 경우 | 3 > 4 FALSE
|
|
x <= y |
x가 y보다 작거나 같은 경우 | 3 <= 4 TRUE
|
|
x >= y |
x가 y보다 크거나 같은 경우 | 3 >= 4 FALSE
|
|
x == y |
x와 y가 같은 경우 | 3 == 4 FALSE
|
|
x != y |
x와 y가 다른 경우 | 3 != 4 TRUE
|
|
| 논리(logical) 연산자 | ! |
논리 부정(negation) | |
& |
논리곱(logical “and”) | ||
| |
논리합(logical “or”) | ||
xor |
배타적 논리합(logical “exclusive or”) | ||
| 기타 연산자 | x %in% y |
원소 포함 | 벡터 x의 각 원소가 y 안에 존재하는지 확인 |
!(x %in% y) |
원소 비포함 | 벡터 x의 각 원소가 y 안에 존재하지 않는지 확인 |
sum() 함수를 사용하여 동일한 연산을 할 수 있다. sum()은 R에 기본적으로 내장되어 있는 Base R 함수 중 하나이다.
sum(a, b)[1] 3지금부터 모든 함수명에는 항상 ()를 연결하여 나타낼 것이다. 다른 객체명과의 혼동을 방지하기 위한 것도 있지만, 모든 함수는 () 속에 인풋(이것을 인자(argument)라고 부른다)을 받아들이기 때문이다.
R에는 수많은 내장 함수가 있다. 그 중 몇가지만 실행하면 다음과 같다. sqrt()는 제곱근을, abs()는 절대값을, log10()는 밑을 10으로 하는 로그값을 산출해준다.
Base R에서 사용되는 주요 내장 함수를 정리하면 다음과 같다.
| 범주 | 구분 | 함수 |
|---|---|---|
| 논리형 판별 함수 | 결측치 여부 |
is.na(), is.nan(), is.infinite(), is.finite()
|
| 유형 확인 |
is.numeric(), is.integer(), is.character(), is.logical(), is.factor()
|
|
| 구조 확인 |
is.data.frame(), is.matrix(), is.list(), is.vector()
|
|
| 기타 |
is.null(), is.atomic(), is.element()
|
|
| 위치 기반 추출 함수 | 첫 번째 원소 | x[1] |
| 마지막 원소 | x[length(x)] |
|
| n번째 원소 | x[n] |
|
| 앞의 몇 개의 원소 | head() |
|
| 뒤의 몇 개의 원소 | tail() |
|
| 수학 함수 | 절댓값/부호 |
abs(), sign()
|
| 제곱근/지수 |
sqrt(), exp()
|
|
| 로그 |
log(), log10(), log2()
|
|
| 삼각함수 |
sin(), cos(), tan(), asin()
|
|
| 반올림 |
round(), floor(), ceiling(), trunc()
|
|
| 요약 |
sum(), mean(), median(), var(), sd(), min(), max(), range(), summary()
|
|
| 벡터 생성 함수 | 수열/반복 |
seq(), rep()
|
| 특정 유형 |
numeric(), integer(), logical(), character()
|
|
| 난수/표본 생성 |
sample(), rnorm(), runif(), rbinom()
|
|
| 집합 연산 함수 | 합집합 | union() |
| 교집합 | intersect() |
|
| 차집합 | setdiff() |
|
| 동일 여부 | setequal() |
|
| 원소 포함 여부 | is.element() |
|
| 변환 함수 | 유형 변환 |
as.numeric(), as.character(), as.factor(), as.data.frame()
|
| 재코딩/재배열 |
cut(), relevel(), reorder()
|
|
| 표준화 | scale() |
|
| 기타 함수 | 길이 | length() |
| 정렬 |
sort(), order()
|
|
| 중복 처리 |
unique(), duplicated()
|
|
| 결측치 처리 | na.omit() |
최근 tidyverse 패키지의 사용이 활발해 지면서 이러한 Base R 함수의 활용에 약간의 변동이 발생하고 있다. tidyverse 패키지는 타이디버스 디자인 원리에 의거해 새로운 함수를 디자인하여 제공하고 있다. 이러한 타이디버스 함수가 Base R 함수나 기존의 패키지의 함수를 대체해 나가고 있는 실정이다. 여전히 많은 사람이 여기에 열거되어 있는 Base R의 기본 함수를 사용하고, 그러한 문법에 따라 코드를 작성하고 있다. 나는 타이디버스가 R의 미래라고 확신하며 가능한 코드를 타이디버스 함수를 이용해 작성하도록 노력할 것이다. 여기서 Base R의 함수는 기본적으로 벡터에 적용되는 함수이고, 타이디버스 함수는 데이터 프레임에 적용되는 함수라는 점을 명확히 할 필요가 있다. 따라서 타이디버스에서 벡터 연산을 할 때는 위에서 열거한 많은 함수를 그대로 사용한다. 특히, 논리형 판별 함수와 수학 함수는 그대로 사용하고 있다. 집합 연산 함수는 이름은 동일하지만 사실 새롭게 디자인한 함수이다. 타이디버스는 새로운 데이터 프레임 기반 함수를 통해 기존의 벡터 기반 함수가 하는 일을 대체하고자 한다. 그렇지만 모든 코드를 데이터 프레임 함수로만 작성할 수 없고, Base R의 여러 벡터 함수는 여전히 유용하게 사용되고 있다. 타이디버스가 부가적으로 제공하는 벡터 함수에 대해서는 다른 장에서 다루도록 한다.
위에서 살펴본 숫자 하나하나는 큰 의미가 없다. 우리는 보통 숫자의 집합(array), 즉 벡터를 다룬다.
a, b, c, d는 모두 벡터이다. 우상의 Environment 창에서도 이러한 사실을 확인할 수 있다. 그런데, 이 세가지 벡터는 데이터의 유형(type)이라는 측면에서 서로 다르다. a는 숫자형(numeric), b는 정수형(integer), c는 논리형(logical), d는 문자형(character)이다. Environment 창을 보면, a에 대해서는 num, b에 대해서는 int, c에 대해서는 logi, d에 대해서는 chr이라는 축약어가 붙어 있음을 알 수 있는데, 이것이 바로 벡터의 유형을 나타내고 있는 것이다. 사실 R에서 다루는 벡터의 유형은 10가지가 넘는다.
tidyverse 패키지의 핵심 패키지 중의 하나인 tibble 패키지에서 규정된 데이터 유형에 대해서는 다음의 웹사이트를 참고할 수 있다. https://tibble.tidyverse.org/articles/types.html
벡터를 data.frame()이라는 함수를 통해 결합하면 데이터 프레임을 만들 수 있다.
df <- data.frame(a, b, c, d)
df a b c d
1 30 30 TRUE 이상일
2 27 27 TRUE 김우형
3 23 23 FALSE 박서우우상의 Environment 창을 보면 뭔가 변화가 있음을 확인할 수 있을 것이다. Data가 생겼고 그 아래에 df가 생성되어 있을 것이다. “3 obs. of 4 variables”라는 말이 굉장히 중요하다. 이것은 df라는 데이터 프레임 객체가 3개의 관측 개체(observations)와 4개의 변수(variables)로 구성되어 있다는 것을 의미한다. 데이터 프레임, 관측 개체, 변수에 대해서는 강의에서 상세하게 다룬다.
Environment 창에서 df를 클릭해보라. 그러면 왼편에 또 하나의 창이 생기면서 마치 엑셀과 같은 형식으로 데이터가 나타날 것이다. View() 함수를 실행해도 동일한 결과를 얻을 수 있다.
View(df)여기서 중요한 것은 새로 생긴 창이다. 이것을 보통 Editor 창이라고 부른다. 이제부터 Console은 부차적인 목적으로만 사용할 것이고 Editor 창이 주인공이 된다.
앞에서 Console에서 했던 모든 일을 동일하게 할 수 있다. 단 실행 방식이 조금 다르다. 앞에서 생성한 df 데이터 프레임의 a 벡터(변수)의 평균값을 구하기 위해 이전과 동일하게 입력한다. 그런데 프롬프트가 없고, [enter]를 눌러도 실행되지 않는다.
mean(df$a)우선 실행할 코드 라인 혹은 코드의 영역을 지정해야 한다. 두 가지 방법이 있다.
실행할 코드 라인 혹은 코드 블록에 커서를 위치시킨다.
왼쪽 마우스 버튼을 누른 상태에서 커서를 이동시켜 실행할 영역 전체를 선택한다.
영역이 지정되면 실행하면 되는데, 여기에도 두 가지 방법이 있다.
단축키(Ctrl + Enter) 실행 (Mac의 경우 Command + Enter)
Editor 창의 우상에 있는 ‘Run the current line or selection’ 아이콘을 클릭(그림 6 참조)
이전의 실행을 반복하고자 할 때는 다음과 같이 하면 된다.
단축키(Ctrl + Alt +P) 실행 (Mac의 경우 Option + Command + P)
Editor 창의 우상에 있는 ‘Re-run the previous code region’ 아이콘을 클릭(그림 6 참조)
코드에 대한 코멘트를 스크립트 파일 곳곳에 남겨두면 나중에 코드 작성의 의도를 보다 쉽게 파악할 수 있다. 이와 관련하여 두 가지 사항을 알아두면 유용하다.
첫째, # 표시 뒤의 것은 R이 실행하지 않기 때문에 중간중간에 # 표시를 하고 그 뒤에 자신의 코멘트를 남겨두는 것을 권한다.
mean(df$a) # 세 사람의 나이 평균을 구함. 첫 번째 사람 나이가 엄청나게 많음.둘째, 코드가 길어지면, 그것을 몇 개의 섹션으로 나누고 그것에 코멘트를 달아 줄 수 있다. 단축키(Crtl + Shift + R, Mac은 Command + Shift + R)를 실행하여 섹션 라벨(Section label)을 달 수 있고, Editor 창의 왼쪽 하단에 있는 작은 아이콘을 이용해 섹션을 빠르게 이동할 수 있다.