Day 2: 데이터의 수집과 정리
오늘 사용할 패키지
tidyversereadxl,writexlnycflight13kosisDTopenxlsx
1 티블(tibble)
실습을 시작하기에 앞서 tidyverse 패키지를 불러오자. 설치는 이미 지난 시간에 했기 때문에 오늘은 library()함수를 통해 패키지를 불러오기만 하면 된다.
왼쪽 위 Editor 창에서 코드를 실행하기 위해서는 그냥 enter가 아니라 ctrl+enter(Mac은 cmd+enter)를 눌러야 한다.
1.1 티블 생성하기
1.1.1 기존 데이터를 티블 포맷으로 변환하기
Base R에 포함되어 있는 iris라는 데이터 프레임을 사용한다. 우선 지난 시간에 배운 파이프 연산자(pipe operator)를 가지고 iris 데이터를 살펴보자.
iris |>
glimpse() Rows: 150
Columns: 5
$ Sepal.Length <dbl> 5.1, 4.9, 4.7, 4.6, 5.0, 5.4, 4.6, 5.0, 4.4, 4.9, 5.4, 4.…
$ Sepal.Width <dbl> 3.5, 3.0, 3.2, 3.1, 3.6, 3.9, 3.4, 3.4, 2.9, 3.1, 3.7, 3.…
$ Petal.Length <dbl> 1.4, 1.4, 1.3, 1.5, 1.4, 1.7, 1.4, 1.5, 1.4, 1.5, 1.5, 1.…
$ Petal.Width <dbl> 0.2, 0.2, 0.2, 0.2, 0.2, 0.4, 0.3, 0.2, 0.2, 0.1, 0.2, 0.…
$ Species <fct> setosa, setosa, setosa, setosa, setosa, setosa, setosa, s…class() 함수를 통해 iris 데이터의 형식이 data.frame인 것을 확인할 수 있다.
class(iris)[1] "data.frame"as_tibble() 함수를 이용하여 tibble 객체로 전환한다. 그러면 data.frame 객체가 tibble 객체로 전환된 것을 알 수 있다.
1.1.2 티블 객체를 직접 생성하기
tibble 객체를 직접 생성하는 방식은 두 가지로 나뉜다.
- 열-단위 방식(보다 일반적): 우선 열-벡터를 만들고 그것을 결합해 최종적인
tibble객체를 만든다.tibble()함수를 이용한다.
# 열-벡터를 만들고 이들을 결합하여 최종적인 tibble 객체 생성
tibble(
x = c(1, 2, 5),
y = c("h", "m", "g"),
z = c(0.08, 0.83, 0.60)
)# A tibble: 3 × 3
x y z
<dbl> <chr> <dbl>
1 1 h 0.08
2 2 m 0.83
3 5 g 0.6 # 수식 등을 활용해서도 tibble 객체를 생성할 수 있다.
tibble(
x = 1:5,
y = 1,
z = x ^ 2 + y
)# A tibble: 5 × 3
x y z
<int> <dbl> <dbl>
1 1 1 2
2 2 1 5
3 3 1 10
4 4 1 17
5 5 1 26- 행-단위 방식: 우선 행-벡터를 만들고 그것을 결합해 최종적인
tibble객체를 만든다.tribble()함수를 이용한다.tribble은 전치티블(transposed tibble)의 약자이다.
# 행-벡터를 만들고 이들을 결합하여 최종적인 tibble 객체 생성
tribble(
~x, ~y, ~z,
1, "h", 0.08,
2, "m", 0.83,
5, "g", 0.60
)# A tibble: 3 × 3
x y z
<dbl> <chr> <dbl>
1 1 h 0.08
2 2 m 0.83
3 5 g 0.6 2 데이터 불러오기
2.1 readr 패키지
2.1.1 파일 형식
readr 패키지는 다양한 함수를 이용해 다양한 형식의 데이터를 불러올 수 있게 도와준다.
read_csv(): 콤마분리(comma-separated values, CSV) 형식의 파일read_csv2(): 세미콜론분리(semicolon-separated) 형식의 파일read_tsv(): 탭구분(tab-delimited) 형식의 파일read_delim(): 여타의 구분 형식의 파일read_fwf(): 고정폭(fixed-width) 형식의 파일read_table(): 공백구분 형식의 파일read_log(): 아파치 형식(Apache-style)의 로그 파일
2.1.2 read_csv() 함수의 활용
students <- read_csv("https://pos.it/r4ds-students-csv")
students# A tibble: 6 × 5
`Student ID` `Full Name` favourite.food mealPlan AGE
<dbl> <chr> <chr> <chr> <chr>
1 1 Sunil Huffmann Strawberry yoghurt Lunch only 4
2 2 Barclay Lynn French fries Lunch only 5
3 3 Jayendra Lyne N/A Breakfast and lunch 7
4 4 Leon Rossini Anchovies Lunch only <NA>
5 5 Chidiegwu Dunkel Pizza Breakfast and lunch five
6 6 Güvenç Attila Ice cream Lunch only 6 다음의 몇 가지 점이 불만족스럽다.
변수명: 특히
Student ID와Full Name변수명은 규칙에 어긋난다. 변수명 속에 공란이 있으면 좋지 않다. 이런 이름을 비구문명(non-syntactic name)이라고 하고, ``로 둘러싸여 표시된다. 나중에 다른 분석을 할 때 문제를 일으킬 수 있기 때문에 바꿔주는 것이 좋다.변수 형식:
mealPlan은 문자형(chr)이 아니라 팩트형(fct)이,AGE는 문자형(chr)이 아니라 수치형(dbl)이 적절하다.결측치(NA):
favourite.food의 ’N/A’는 형식에 맞지 않아 결측치가 아니라 문자로 취급된다. 따라서 ’N/A’가 결측치임을 알려주어야 한다.
students <- read_csv(
"https://pos.it/r4ds-students-csv",
skip = 1, # 첫 행을 건너뛰기
col_names = c("student_id", "full_name", "favorite_food", "meal_plan", "age"), # 새로운 변수명 지정
col_types = cols(
meal_plan = col_factor(),
age = col_number()), # 변수별 타입 지정
na = "N/A" # 문자 "N/A"를 결측치 NA로 수정
)
students# A tibble: 6 × 5
student_id full_name favorite_food meal_plan age
<dbl> <chr> <chr> <fct> <dbl>
1 1 Sunil Huffmann Strawberry yoghurt Lunch only 4
2 2 Barclay Lynn French fries Lunch only 5
3 3 Jayendra Lyne <NA> Breakfast and lunch 7
4 4 Leon Rossini Anchovies Lunch only NA
5 5 Chidiegwu Dunkel Pizza Breakfast and lunch NA
6 6 Güvenç Attila Ice cream Lunch only 62.2 엑셀 파일
2.2.1 readxl 패키지
가장 널리 사용되는 스프레드시트(spreadsheet) 형식인 엑셀 파일을 불러들이기 위해서는 readxl이라는 패키지가 필요하다. tidyverse의 핵심 패키지는 아니지만 일종의 친척 패키지라 할 수는 있다. tidyverse에 포함되어 있지 않기 때문에 따로 인스톨하고 library() 함수를 통해 불러와야 한다.
가장 널리 사용되는 명령어는 다음의 세 가지이다.
read_xls(): xls 포맷의 엑셀 파일 불러오기read_xlsx(): xlsx 포맷의 엑셀 파일 불러오기read_excel(): xls, xlsx 포맷의 엑셀 파일 불러오기
2.2.2 read_excel() 함수의 활용
World Population Prospects 2022 데이터를 직접 다운받아 실습을 진행하고자 한다. 이 데이터셋은 매우 중요하다. 다음의 절차에 따라 해당 엑셀 파일을 다운로드한다.
WPP 웹사이트(https://population.un.org/wpp/)에 접속한다.
Download Data Files를 클릭한다.
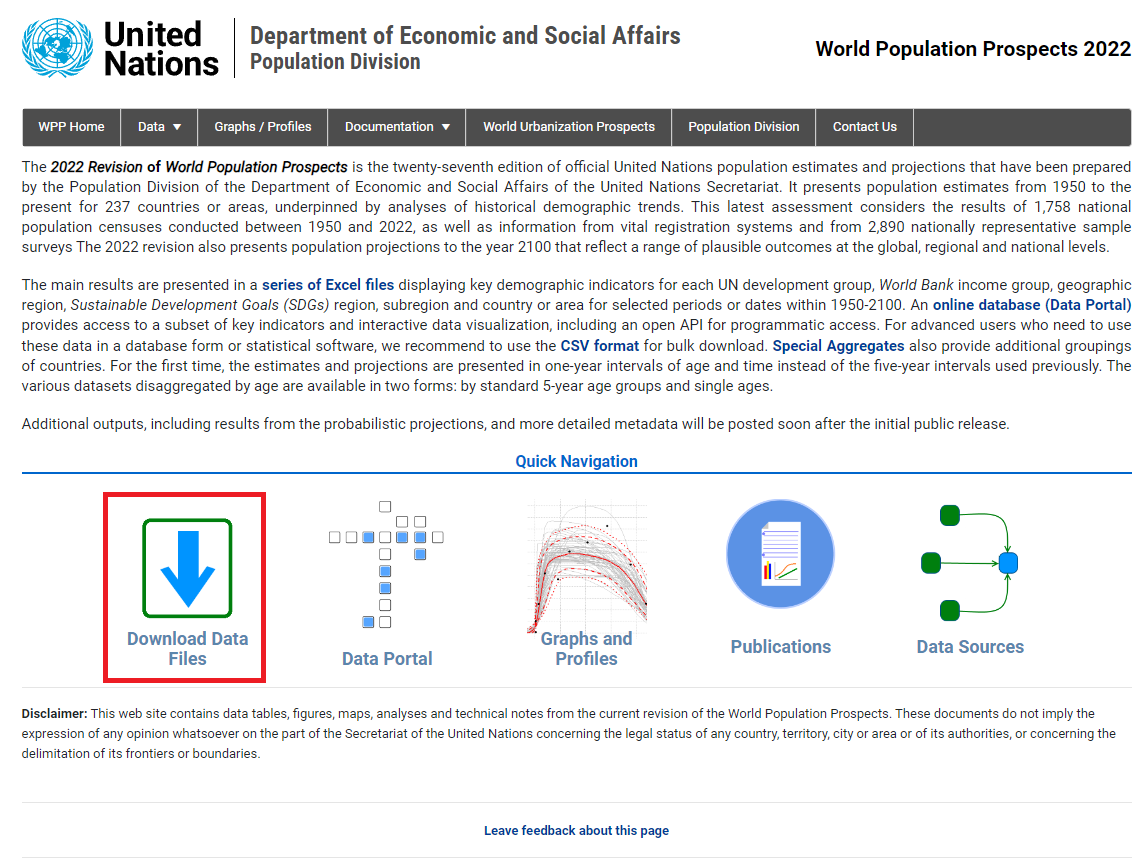
- 다음의 파일을 클릭한다: Compact (most used: estimates and medium projections) (XLSX, 24.07 MB)
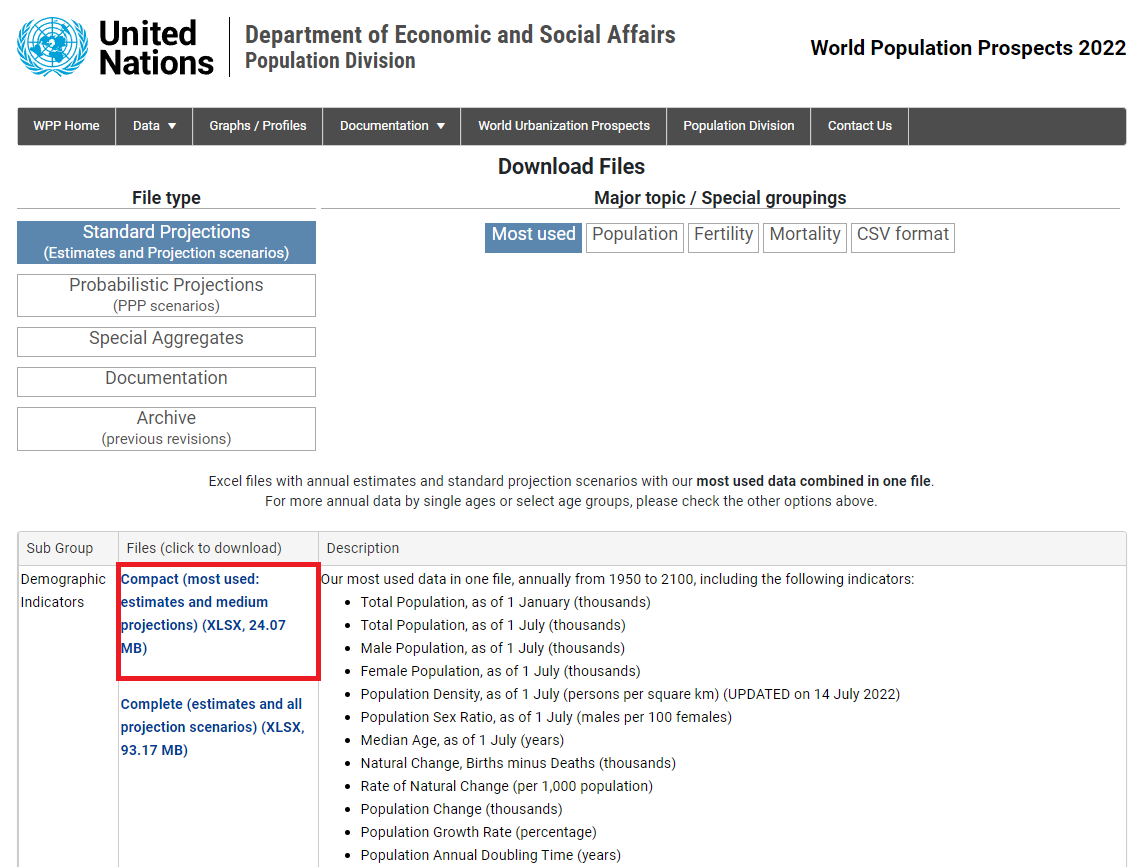
- 엑셀 파일(WPP2024_GEN_F01_DEMOGRAPHIC_INDICATORS_COMPACT)을 다운로드하여 자신의 프로젝트 폴더에 저장한다. 프로젝트 폴더에 저장하지 않으면 따로 경로를 설정해주어야 한다.
R 바깥에서 다운로드한 파일을 열어 어떠한 정보가 어떠한 방식으로 수록되어 있는지 살펴본다. 데이터 불러오기를 위해 다음의 네 가지 사항에 유의해야 함을 이해한다.
16번 행까지는 불필요한 영역이다.
17번 행을 변수명으로 사용할 경우 많은 문제점이 발생한다.
결측치는 공란이거나 ‘…’ 기호로 표시되어 있다.
첫 번째 워킹시트(Estimates)에는 1950~2023의 데이터가, 두 번째 워킹시트(Medium variant)에는 2024~2100년의 데이터가 수록되어 있다. 나중에 결합해야한다.
우선 엑셀 파일을 그대로 불러와 본다.
read_excel(
"WPP2024_GEN_F01_DEMOGRAPHIC_INDICATORS_COMPACT.xlsx",
sheet = "Estimates"
)# A tibble: 21,995 × 65
...1 ...2 ...3 ...4 `United Nations` ...6 ...7 ...8 ...9 ...10 ...11
<chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
1 <NA> <NA> <NA> <NA> "Population Divi… <NA> <NA> <NA> <NA> <NA> <NA>
2 <NA> <NA> <NA> <NA> "Department of E… <NA> <NA> <NA> <NA> <NA> <NA>
3 <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
4 <NA> <NA> <NA> <NA> "World Populatio… <NA> <NA> <NA> <NA> <NA> <NA>
5 <NA> <NA> <NA> <NA> "File GEN/01/REV… <NA> <NA> <NA> <NA> <NA> <NA>
6 <NA> <NA> <NA> <NA> "Estimates, 1950… <NA> <NA> <NA> <NA> <NA> <NA>
7 <NA> <NA> <NA> <NA> "POP/DB/WPP/Rev.… <NA> <NA> <NA> <NA> <NA> <NA>
8 <NA> <NA> <NA> <NA> "© July 2024 by … <NA> <NA> <NA> <NA> <NA> <NA>
9 <NA> <NA> <NA> <NA> "Suggested citat… <NA> <NA> <NA> <NA> <NA> <NA>
10 <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA> <NA>
# ℹ 21,985 more rows
# ℹ 54 more variables: ...12 <chr>, ...13 <chr>, ...14 <chr>, ...15 <chr>,
# ...16 <chr>, ...17 <chr>, ...18 <chr>, ...19 <chr>, ...20 <chr>,
# ...21 <chr>, ...22 <chr>, ...23 <chr>, ...24 <chr>, ...25 <chr>,
# ...26 <chr>, ...27 <chr>, ...28 <chr>, ...29 <chr>, ...30 <chr>,
# ...31 <chr>, ...32 <chr>, ...33 <chr>, ...34 <chr>, ...35 <chr>,
# ...36 <chr>, ...37 <chr>, ...38 <chr>, ...39 <chr>, ...40 <chr>, …끔찍할 것이다. 아래의 과정을 거쳐 사용할 수 있는 데이터로 바꾸어 불러온다.
우선 새로운 변수명들을 하나의 벡터로 만든다.
# 새롭게 사용될 변수명 지정
new_names <- c("index", "variant", "region_name", "notes", "location_code",
"ISO3", "ISO2", "SDMX", "type", "parent_code", "year", "pop_jan_total",
"pop_jul_total", "pop_jul_male", "pop_jul_female", "pop_den", "sex_ratio",
"median_age", "natural_change", "RNC", "pop_change", "PGR",
"dubling_time", "births", "births_by_f1519", "CBR", "TFR", "NRR",
"mean_age_childbearing", "sex_ratio_birth", "deaths_total",
"deaths_male", "deaths_female", "CDR", "life_exp_total",
"life_exp_male", "life_exp_female", "life_exp_15_total",
"life_exp_15_male", "life_exp_15_female", "life_exp_65_total",
"life_exp_65_male", "life_exp_65_female", "life_exp_80_total",
"life_exp_80_male", "life_exp_80_female", "infant_deaths",
"IMR", "live_births", "under_five_deaths", "mort_under_five",
"mort_bf_40_total", "mort_bf_40_male", "mort_bf_40_female", "mort_bf_60_total",
"mort_bf_60_male", "mort_bf_60_female", "mort_bt_1550_total",
"mort_bt_1550_male", "mort_bt_1550_female", "mort_bt_1560_total",
"mort_bt_1560_male", "mort_bt_1560_female", "net_migrants", "NMR")앞에서 했던 과정과 유사하게 필요한 내용들을 수정하여 엑셀 파일을 불러온다.
# Estimates 시트 정리
wpp_2024_estimates <- read_excel(
"WPP2024_GEN_F01_DEMOGRAPHIC_INDICATORS_COMPACT.xlsx",
sheet = "Estimates",
skip = 17,
col_names = new_names,
col_types = c(rep("guess", 3), "text", "guess", rep("text", 2), rep("guess", 58)),
na = c("...", "")
)
# Medium variant 시트 정리
wpp_2024_future <- read_excel(
"WPP2024_GEN_F01_DEMOGRAPHIC_INDICATORS_COMPACT.xlsx",
sheet = "Medium variant",
skip = 17,
col_names = new_names,
col_types = c(rep("guess", 3), "text", "guess", rep("text", 2), rep("guess", 58)),
na = c("...", "")
)
# 행 단위로 결합
wpp_2024 <- bind_rows(wpp_2024_estimates, wpp_2024_future)
# 새 창에서 보기
View(wpp_2024)rep() 함수
rep()함수는 Basic R 함수로 값들을 반복하는 데 사용된다.
[1] "A" "B" "C" "A" "B" "C" "A" "B" "C"[1] "A" "B" "C" "A" "B" "C" "A" "B" "C"해야 할 일이 한가지 더 남아있다. 많은 변수 중에 데이터 탐색이라는 측면에서 가장 중요한 것은 type 변수이다. 다음을 통해 distinct()함수를 통해 type 변수에 어떤 내용이 담겨 있는지 확인한다.
wpp_2024 |>
distinct(type) # type 변수에 어떤 값들이 들어가 있는지 확인# A tibble: 9 × 1
type
<chr>
1 World
2 Label/Separator
3 SDG region
4 Development Group
5 Special other
6 Income Group
7 Region
8 Subregion
9 Country/Area distinct() 함수의 결과를 통해 세계 전체(World), 국가군(SDG region, Region 등), 국가(Country/Area) 등으로 데이터를 활용할 수 있다는 것을 인지한다. 그런데, “Label/Separator”는 엑셀 내에서 분할선의 역할만 하는 것으로, 무의미한 값이다. 따라서 이를 제거한다.
wpp_2024 <- wpp_2024 |>
filter(type != "Label/Separator") # type 변수의 값이 "Label/Separator"가 아닌 행만 추출나중에 사용하기 위해, writexl 패키지의 write_xlsx() 함수를 이용하여 엑셀 파일로 저장한다.
library(writexl)
write_xlsx(wpp_2024, "wpp_2024.xlsx")그런데, 저장된 파일을 read_excel() 함수로 다시 불러 들이면 컬럼 형식에 대한 정보가 사라져 버리는 등의 에러가 발생한다. 이런 점 때문에 다음과 같은 대안이 존재한다. readr 패키지의 write_rds() 함수로 저장하고, 다시 read_rds() 함수로 불러들이면 정확히 동일한 것을 얻을 수 있다.
# A tibble: 44,847 × 65
index variant region_name notes location_code ISO3 ISO2 SDMX type
<dbl> <chr> <chr> <chr> <dbl> <chr> <chr> <dbl> <chr>
1 1 Estimates World <NA> 900 <NA> <NA> 1 World
2 2 Estimates World <NA> 900 <NA> <NA> 1 World
3 3 Estimates World <NA> 900 <NA> <NA> 1 World
4 4 Estimates World <NA> 900 <NA> <NA> 1 World
5 5 Estimates World <NA> 900 <NA> <NA> 1 World
6 6 Estimates World <NA> 900 <NA> <NA> 1 World
7 7 Estimates World <NA> 900 <NA> <NA> 1 World
8 8 Estimates World <NA> 900 <NA> <NA> 1 World
9 9 Estimates World <NA> 900 <NA> <NA> 1 World
10 10 Estimates World <NA> 900 <NA> <NA> 1 World
# ℹ 44,837 more rows
# ℹ 56 more variables: parent_code <dbl>, year <dbl>, pop_jan_total <dbl>,
# pop_jul_total <dbl>, pop_jul_male <dbl>, pop_jul_female <dbl>,
# pop_den <dbl>, sex_ratio <dbl>, median_age <dbl>, natural_change <dbl>,
# RNC <dbl>, pop_change <dbl>, PGR <dbl>, dubling_time <dbl>, births <dbl>,
# births_by_f1519 <dbl>, CBR <dbl>, TFR <dbl>, NRR <dbl>,
# mean_age_childbearing <dbl>, sex_ratio_birth <dbl>, deaths_total <dbl>, ….rds 파일은 R 전용 특수한 형태의 파일로, R에서 사용하기 편리한 구조를 가지고 있다. R에서 작업을 할 경우에는 .rds 파일을 이용하고 R을 사용하지 않는 사람과 파일을 주고 받을 때에는 .csv파일을 이용하면 좋다.
3 데이터 정리하기
여기서는 데이터 늘이기(lengthening data), 데이터 넓히기(widening data), 데이터 결합하기(joining data)를 다룬다.
3.1 데이터 늘이기
실습을 위해 tidyverse 패키지에 포함되어 있는 who2 데이터를 사용한다. 이것은 WHO(world Health Organization, 세계보건기구)에서 제공한 데이터로서 1980~2013년 전세계 209개국의 결핵 환자수에 대한 데이터이다.
glimpse(who2)Rows: 7,240
Columns: 58
$ country <chr> "Afghanistan", "Afghanistan", "Afghanistan", "Afghanistan",…
$ year <dbl> 1980, 1981, 1982, 1983, 1984, 1985, 1986, 1987, 1988, 1989,…
$ sp_m_014 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ sp_m_1524 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ sp_m_2534 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ sp_m_3544 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ sp_m_4554 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ sp_m_5564 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ sp_m_65 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ sp_f_014 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ sp_f_1524 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ sp_f_2534 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ sp_f_3544 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ sp_f_4554 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ sp_f_5564 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ sp_f_65 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ sn_m_014 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ sn_m_1524 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ sn_m_2534 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ sn_m_3544 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ sn_m_4554 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ sn_m_5564 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ sn_m_65 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ sn_f_014 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ sn_f_1524 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ sn_f_2534 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ sn_f_3544 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ sn_f_4554 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ sn_f_5564 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ sn_f_65 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ ep_m_014 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ ep_m_1524 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ ep_m_2534 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ ep_m_3544 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ ep_m_4554 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ ep_m_5564 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ ep_m_65 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ ep_f_014 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ ep_f_1524 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ ep_f_2534 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ ep_f_3544 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ ep_f_4554 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ ep_f_5564 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ ep_f_65 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ rel_m_014 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ rel_m_1524 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ rel_m_2534 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ rel_m_3544 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ rel_m_4554 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ rel_m_5564 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ rel_m_65 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ rel_f_014 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ rel_f_1524 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ rel_f_2534 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ rel_f_3544 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ rel_f_4554 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ rel_f_5564 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ rel_f_65 <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…country와 year은 분명한 변수이지만 나머지 56개 변수는 무엇인지 알 수 없다. 그런데 잘 살펴보면, 변수명에 어떤 패턴이 있다는 것을 알 수 있다. 모두 세 부분으로 나뉘어져 있는데, 첫 번째 부분은 진단법(sp, rel, ep)과 관련되어 있고, 두 번째 부분은 성(m, f)과 관련되어 있고, 세 번째 부분은 연령(014, 1524, 2534, 3544, 4554, 5564, 65)과 관련되어 있다. 56개 변수의 셀 값은 모두 케이스(환자수)를 의미한다. 이 지저분한 데이터를 pivot_longer() 함수를 이용해 정돈된 데이터로 만들어 본다.
who2 |>
pivot_longer(
cols = !c(country, year), # country와 year을 제외한 나머지 변수들을 바꾼다.
names_to = c("diagnosis", "gender", "age"), # 원래 데이터의 변수명들이 들어갈 새로운 변수명 지정
names_sep = "_", # "_"를 기준으로 원래의 변수명을 분할
values_to = "count" # 원래 데이터의 값들이 들어갈 새로운 변수명 지정
)# A tibble: 405,440 × 6
country year diagnosis gender age count
<chr> <dbl> <chr> <chr> <chr> <dbl>
1 Afghanistan 1980 sp m 014 NA
2 Afghanistan 1980 sp m 1524 NA
3 Afghanistan 1980 sp m 2534 NA
4 Afghanistan 1980 sp m 3544 NA
5 Afghanistan 1980 sp m 4554 NA
6 Afghanistan 1980 sp m 5564 NA
7 Afghanistan 1980 sp m 65 NA
8 Afghanistan 1980 sp f 014 NA
9 Afghanistan 1980 sp f 1524 NA
10 Afghanistan 1980 sp f 2534 NA
# ℹ 405,430 more rows정돈된 데이터를 만들기 위해 왜 데이터 ’늘이기’를 해야하는지 생각해 보라.
3.2 데이터 넓히기
실습을 위해 tidyverse 패키지에 포함되어 있는 cms_patient_experience 데이터를 사용한다. 이것은 미국의 Centers of Medicare and Meicaid Services가 제공한 데이터이다.
View(cms_patient_experience)이 데이터도 정돈된 데이터가 아니다. 자세히 살펴보면 다음과 같은 사실을 알 수 있다.
org_pac_id와org_nm변수는 의료조직의 식별자와 이름이다.의료조직별로 6개씩의 열을 차지하고 있는데, 6개의 열은
measure_cd와measure_title에 나타나 있는 것과 같은 6개의 서로 다른 조사 항목을 나타낸다.마지막의
prf_rate는 조사 항목별 점수이다.
pivot_wider() 함수를 이용하여, 행에는 개별 의료조직이, 열에는 개별 조사 항목이 나타나는 정돈된 데이터를 만들어 본다.
cms_patient_experience |>
pivot_wider(
names_from = measure_cd, # 원래 데이터의 measure_cd 값들을 변수로 변환
values_from = prf_rate # 원래 데이터의 prf_rate 값들을 변수의 값으로 변환
)# A tibble: 500 × 9
org_pac_id org_nm measure_title CAHPS_GRP_1 CAHPS_GRP_2 CAHPS_GRP_3
<chr> <chr> <chr> <dbl> <dbl> <dbl>
1 0446157747 USC CARE MEDICA… CAHPS for MI… 63 NA NA
2 0446157747 USC CARE MEDICA… CAHPS for MI… NA 87 NA
3 0446157747 USC CARE MEDICA… CAHPS for MI… NA NA 86
4 0446157747 USC CARE MEDICA… CAHPS for MI… NA NA NA
5 0446157747 USC CARE MEDICA… CAHPS for MI… NA NA NA
6 0446157747 USC CARE MEDICA… CAHPS for MI… NA NA NA
7 0446162697 ASSOCIATION OF … CAHPS for MI… 59 NA NA
8 0446162697 ASSOCIATION OF … CAHPS for MI… NA 85 NA
9 0446162697 ASSOCIATION OF … CAHPS for MI… NA NA 83
10 0446162697 ASSOCIATION OF … CAHPS for MI… NA NA NA
# ℹ 490 more rows
# ℹ 3 more variables: CAHPS_GRP_5 <dbl>, CAHPS_GRP_8 <dbl>, CAHPS_GRP_12 <dbl>데이터 늘이기를 수행했으나 여전히 하나의 의료 조직이 여러 행에 걸쳐 나타나고 있음을 확인할 수 있다. 이를 해결하기 위해 각 행을 고유하게 식별하는 변수를 선택한다. 이 데이터에서는 “org”로 시작하는 변수들이 이에 해당한다.
cms_patient_experience |>
pivot_wider(
id_cols = starts_with("org"), # 각 행을 고유하게 식별하는 변수 선택
names_from = measure_cd,
values_from = prf_rate
)# A tibble: 95 × 8
org_pac_id org_nm CAHPS_GRP_1 CAHPS_GRP_2 CAHPS_GRP_3 CAHPS_GRP_5 CAHPS_GRP_8
<chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
1 0446157747 USC C… 63 87 86 57 85
2 0446162697 ASSOC… 59 85 83 63 88
3 0547164295 BEAVE… 49 NA 75 44 73
4 0749333730 CAPE … 67 84 85 65 82
5 0840104360 ALLIA… 66 87 87 64 87
6 0840109864 REX H… 73 87 84 67 91
7 0840513552 SCL H… 58 83 76 58 78
8 0941545784 GRITM… 46 86 81 54 NA
9 1052612785 COMMU… 65 84 80 58 87
10 1254237779 OUR L… 61 NA NA 65 NA
# ℹ 85 more rows
# ℹ 1 more variable: CAHPS_GRP_12 <dbl>이제 어떤 의료조직이 어떤 항목에서 얼마의 점수를 받았는지를 일목요연하게 알아 볼 수 있다. 정돈된 데이터를 만들기 위해 이번에는 왜 데이터 ’넓히기’를 해야하는지 생각해 보라.
3.3 데이터 결합하기
3.3.1 조인(join)의 종류
여기서는 데이터 프레임을 결합하여 새로운 데이터 프레임을 생성하는 과정에 대해 살펴본다. tidyverse 패키지에 포함되어 있는 dplyr 패키지는 다양한 종류의 조인(join) 함수를 제공한다.
left_join(): 첫 번째 변수는 그대로 둔 상태에서 두 번째 변수를 결합함으로써 두 번째 변수의 열을 가져옴inner_join(): 두 번째 변수는 그대로 둔 상태에서 첫 번째 변수를 결합함으로써 첫 번째 변수의 열을 가져옴right_join(): 두 변수 모두에 존재하는 열을 취함full_join(): 최소한 한 변수에 존재하는 열을 모두 취함semi_join(): 첫 번째 변수의 행 중 두 번째 변수에 대응하는 행이 있는 것만 취함anti_join(): 첫 번째 변수의 행 중 두 번째 변수에 대응하는 행이 없는 것만 취함
이들 중 left_join()이 가장 많이 사용되기 때문에 그것에 집중한다.
3.3.2 left_join() 함수의 활용
실습을 위해 nycflights13 패키지의 데이터를 사용한다. 이 패키지에는 다섯 개의 데이터 프레임이 포함되어 있다. 지난 번에는 첫 번째 데이터만 사용했다.
flights: 2013년 NYC를 출발한 모든 항공기weather: 공항별 시간별 기상 상황planes: 항공기별 건조 정보airports: 공항명과 위치airlines: 항공사
그리고 이 6개의 데이터 프레임은 Figure 1 처럼 공통키(common key)를 통해 서로 연결되어 있다.
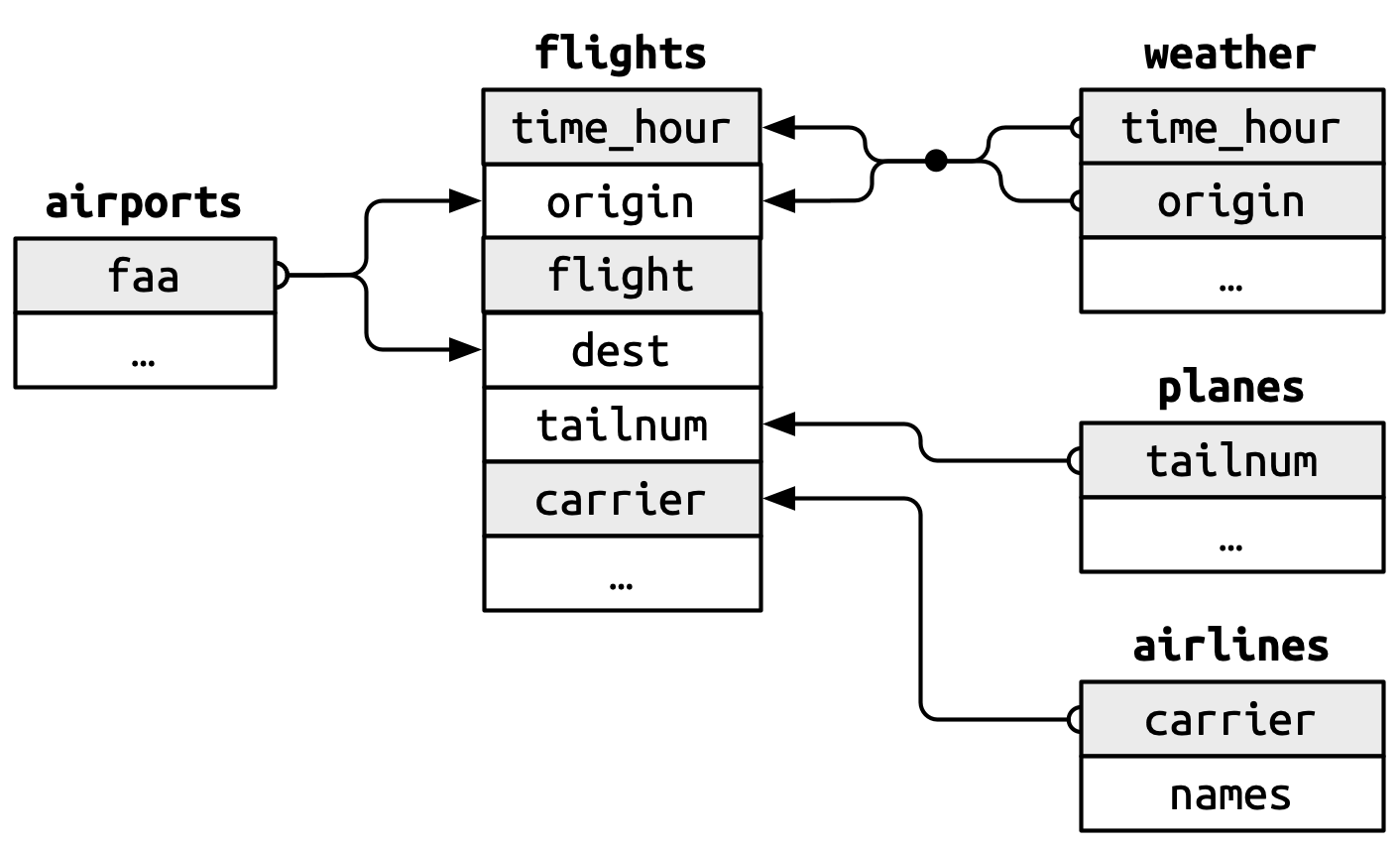
nycflights13 데이터(https://github.com/tidyverse/nycflights13)
flights 데이터의 변수가 너무 많기 때문에 조인을 위한 공통키를 중심으로 변수를 줄인다.
flights2 <- flights |>
select(year, time_hour, origin, dest, tailnum, carrier)
flights2# A tibble: 336,776 × 6
year time_hour origin dest tailnum carrier
<int> <dttm> <chr> <chr> <chr> <chr>
1 2013 2013-01-01 05:00:00 EWR IAH N14228 UA
2 2013 2013-01-01 05:00:00 LGA IAH N24211 UA
3 2013 2013-01-01 05:00:00 JFK MIA N619AA AA
4 2013 2013-01-01 05:00:00 JFK BQN N804JB B6
5 2013 2013-01-01 06:00:00 LGA ATL N668DN DL
6 2013 2013-01-01 05:00:00 EWR ORD N39463 UA
7 2013 2013-01-01 06:00:00 EWR FLL N516JB B6
8 2013 2013-01-01 06:00:00 LGA IAD N829AS EV
9 2013 2013-01-01 06:00:00 JFK MCO N593JB B6
10 2013 2013-01-01 06:00:00 LGA ORD N3ALAA AA
# ℹ 336,766 more rowsflights2 데이터를 중심으로 나머지 4개의 데이터와 조인한다.
airlines# A tibble: 16 × 2
carrier name
<chr> <chr>
1 9E Endeavor Air Inc.
2 AA American Airlines Inc.
3 AS Alaska Airlines Inc.
4 B6 JetBlue Airways
5 DL Delta Air Lines Inc.
6 EV ExpressJet Airlines Inc.
7 F9 Frontier Airlines Inc.
8 FL AirTran Airways Corporation
9 HA Hawaiian Airlines Inc.
10 MQ Envoy Air
11 OO SkyWest Airlines Inc.
12 UA United Air Lines Inc.
13 US US Airways Inc.
14 VX Virgin America
15 WN Southwest Airlines Co.
16 YV Mesa Airlines Inc. flights2 |>
left_join(airlines)# A tibble: 336,776 × 7
year time_hour origin dest tailnum carrier name
<int> <dttm> <chr> <chr> <chr> <chr> <chr>
1 2013 2013-01-01 05:00:00 EWR IAH N14228 UA United Air Lines Inc.
2 2013 2013-01-01 05:00:00 LGA IAH N24211 UA United Air Lines Inc.
3 2013 2013-01-01 05:00:00 JFK MIA N619AA AA American Airlines Inc.
4 2013 2013-01-01 05:00:00 JFK BQN N804JB B6 JetBlue Airways
5 2013 2013-01-01 06:00:00 LGA ATL N668DN DL Delta Air Lines Inc.
6 2013 2013-01-01 05:00:00 EWR ORD N39463 UA United Air Lines Inc.
7 2013 2013-01-01 06:00:00 EWR FLL N516JB B6 JetBlue Airways
8 2013 2013-01-01 06:00:00 LGA IAD N829AS EV ExpressJet Airlines I…
9 2013 2013-01-01 06:00:00 JFK MCO N593JB B6 JetBlue Airways
10 2013 2013-01-01 06:00:00 LGA ORD N3ALAA AA American Airlines Inc.
# ℹ 336,766 more rowsweather# A tibble: 26,115 × 15
origin year month day hour temp dewp humid wind_dir wind_speed
<chr> <int> <int> <int> <int> <dbl> <dbl> <dbl> <dbl> <dbl>
1 EWR 2013 1 1 1 39.0 26.1 59.4 270 10.4
2 EWR 2013 1 1 2 39.0 27.0 61.6 250 8.06
3 EWR 2013 1 1 3 39.0 28.0 64.4 240 11.5
4 EWR 2013 1 1 4 39.9 28.0 62.2 250 12.7
5 EWR 2013 1 1 5 39.0 28.0 64.4 260 12.7
6 EWR 2013 1 1 6 37.9 28.0 67.2 240 11.5
7 EWR 2013 1 1 7 39.0 28.0 64.4 240 15.0
8 EWR 2013 1 1 8 39.9 28.0 62.2 250 10.4
9 EWR 2013 1 1 9 39.9 28.0 62.2 260 15.0
10 EWR 2013 1 1 10 41 28.0 59.6 260 13.8
# ℹ 26,105 more rows
# ℹ 5 more variables: wind_gust <dbl>, precip <dbl>, pressure <dbl>,
# visib <dbl>, time_hour <dttm># A tibble: 336,776 × 8
year time_hour origin dest tailnum carrier temp wind_speed
<int> <dttm> <chr> <chr> <chr> <chr> <dbl> <dbl>
1 2013 2013-01-01 05:00:00 EWR IAH N14228 UA 39.0 12.7
2 2013 2013-01-01 05:00:00 LGA IAH N24211 UA 39.9 15.0
3 2013 2013-01-01 05:00:00 JFK MIA N619AA AA 39.0 15.0
4 2013 2013-01-01 05:00:00 JFK BQN N804JB B6 39.0 15.0
5 2013 2013-01-01 06:00:00 LGA ATL N668DN DL 39.9 16.1
6 2013 2013-01-01 05:00:00 EWR ORD N39463 UA 39.0 12.7
7 2013 2013-01-01 06:00:00 EWR FLL N516JB B6 37.9 11.5
8 2013 2013-01-01 06:00:00 LGA IAD N829AS EV 39.9 16.1
9 2013 2013-01-01 06:00:00 JFK MCO N593JB B6 37.9 13.8
10 2013 2013-01-01 06:00:00 LGA ORD N3ALAA AA 39.9 16.1
# ℹ 336,766 more rowsplanes# A tibble: 3,322 × 9
tailnum year type manufacturer model engines seats speed engine
<chr> <int> <chr> <chr> <chr> <int> <int> <int> <chr>
1 N10156 2004 Fixed wing multi… EMBRAER EMB-… 2 55 NA Turbo…
2 N102UW 1998 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
3 N103US 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
4 N104UW 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
5 N10575 2002 Fixed wing multi… EMBRAER EMB-… 2 55 NA Turbo…
6 N105UW 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
7 N107US 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
8 N108UW 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
9 N109UW 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
10 N110UW 1999 Fixed wing multi… AIRBUS INDU… A320… 2 182 NA Turbo…
# ℹ 3,312 more rows# A tibble: 336,776 × 9
year time_hour origin dest tailnum carrier type engines seats
<int> <dttm> <chr> <chr> <chr> <chr> <chr> <int> <int>
1 2013 2013-01-01 05:00:00 EWR IAH N14228 UA Fixed w… 2 149
2 2013 2013-01-01 05:00:00 LGA IAH N24211 UA Fixed w… 2 149
3 2013 2013-01-01 05:00:00 JFK MIA N619AA AA Fixed w… 2 178
4 2013 2013-01-01 05:00:00 JFK BQN N804JB B6 Fixed w… 2 200
5 2013 2013-01-01 06:00:00 LGA ATL N668DN DL Fixed w… 2 178
6 2013 2013-01-01 05:00:00 EWR ORD N39463 UA Fixed w… 2 191
7 2013 2013-01-01 06:00:00 EWR FLL N516JB B6 Fixed w… 2 200
8 2013 2013-01-01 06:00:00 LGA IAD N829AS EV Fixed w… 2 55
9 2013 2013-01-01 06:00:00 JFK MCO N593JB B6 Fixed w… 2 200
10 2013 2013-01-01 06:00:00 LGA ORD N3ALAA AA <NA> NA NA
# ℹ 336,766 more rowsairports# A tibble: 1,458 × 8
faa name lat lon alt tz dst tzone
<chr> <chr> <dbl> <dbl> <dbl> <dbl> <chr> <chr>
1 04G Lansdowne Airport 41.1 -80.6 1044 -5 A America/…
2 06A Moton Field Municipal Airport 32.5 -85.7 264 -6 A America/…
3 06C Schaumburg Regional 42.0 -88.1 801 -6 A America/…
4 06N Randall Airport 41.4 -74.4 523 -5 A America/…
5 09J Jekyll Island Airport 31.1 -81.4 11 -5 A America/…
6 0A9 Elizabethton Municipal Airport 36.4 -82.2 1593 -5 A America/…
7 0G6 Williams County Airport 41.5 -84.5 730 -5 A America/…
8 0G7 Finger Lakes Regional Airport 42.9 -76.8 492 -5 A America/…
9 0P2 Shoestring Aviation Airfield 39.8 -76.6 1000 -5 U America/…
10 0S9 Jefferson County Intl 48.1 -123. 108 -8 A America/…
# ℹ 1,448 more rows# A tibble: 336,776 × 13
year time_hour origin dest tailnum carrier name lat lon
<int> <dttm> <chr> <chr> <chr> <chr> <chr> <dbl> <dbl>
1 2013 2013-01-01 05:00:00 EWR IAH N14228 UA Newark Li… 40.7 -74.2
2 2013 2013-01-01 05:00:00 LGA IAH N24211 UA La Guardia 40.8 -73.9
3 2013 2013-01-01 05:00:00 JFK MIA N619AA AA John F Ke… 40.6 -73.8
4 2013 2013-01-01 05:00:00 JFK BQN N804JB B6 John F Ke… 40.6 -73.8
5 2013 2013-01-01 06:00:00 LGA ATL N668DN DL La Guardia 40.8 -73.9
6 2013 2013-01-01 05:00:00 EWR ORD N39463 UA Newark Li… 40.7 -74.2
7 2013 2013-01-01 06:00:00 EWR FLL N516JB B6 Newark Li… 40.7 -74.2
8 2013 2013-01-01 06:00:00 LGA IAD N829AS EV La Guardia 40.8 -73.9
9 2013 2013-01-01 06:00:00 JFK MCO N593JB B6 John F Ke… 40.6 -73.8
10 2013 2013-01-01 06:00:00 LGA ORD N3ALAA AA La Guardia 40.8 -73.9
# ℹ 336,766 more rows
# ℹ 4 more variables: alt <dbl>, tz <dbl>, dst <chr>, tzone <chr>airports의 경우만 왜 join_by()라는 아규먼트가 필요한지 생각해 본다.
4 API를 활용한 데이터의 수집
KOSIS를 포함한 많은 대한민국의 데이터 포털은 개방 API 서비스를 제공하고 있다. KOSIS는 공유서비스 홈페이지(https://kosis.kr/openapi/)를 통해 Open API를 통한 데이터 수집을 권장하고 있다.
앞에서 설명한 것처럼, API용 패키지를 직접 사용할 수도 있지만, 래퍼 패키지가 존재하기만 한다면 그것을 활용하는 것이 훨씬 손쉬운 옵션일 수 있다. 놀랍게도 한국의 주석훈(Seokhoon Joo)이라는 분이 그러한 기능을 하는 kosis(https://cran.r-project.org/web/packages/kosis/index.html)라는 패키지를 이미 개발해 두었고, 그것을 활용하고자 한다.
실습 주제는 2022년 센서스 인구 기준으로 전국의 17개 시도별 ’지방소멸위험지수’를 계산하고 그래프의 형태로 표현하는 것이다.
4.1 KOSIS에서 API KEY 받기
먼저 API를 활용하기 위해 기관으로부터 KEY를 발급받아야 한다. 이를 위해 통계청에 회원가입을 한 후, KEY를 요청해야 한다. 과정은 아래와 같다.
KOSIS 공유서비스 웹페이지(https://kosis.kr/openapi/) 접속
-
상단의 [활용신청] 탭 클릭
- 통계청의 ONE-ID로 통합로그인(없으면 회원가입 필수)
-
활용신청하여 사용자 인증키 획득
- 사용자 인증키는 마이페이지에서 언제든 확인 가능
4.2 패키지 설치 및 인증키 등록
우선 kosis 패키지를 오른쪽 하단 윈도우의 Packages 탭을 활용하여 인스톨한다. 이후에 아래와 같이 kosis와 tidyverse 패키지를 불러온다.
library(kosis)다음으로, kosis 패키지의 kosis.setKey() 함수를 이용하여 인증키를 등록한다. Your Key Here 자리에 부여받은 인증키를 붙여 넣는다.
kosis.setKey(apiKey = "Your Key Here")4.3 데이터 추출
이제 통계청 홈페이지에 접속해서 데이터를 불러와본다. 과정은 아래와 같다.
KOSIS에 접속 후 로그인
-
데이터에 접근 후 URL 생성
[국내통계]-[주제별 통계]-[인구]-[인구총조사]-[인구부문]-[총조사인구(2015년 이후)]-[전수부문 (등록센서스, 2015년 이후)]-[전수기본표]-[연령 및 성별 인구]
항목: ‘총인구(명)’, ‘총인구_남자(명)’, ’총인구_여자(명)’만 선택(더 많은 항목을 선택하면 데이터가 너무 커 에러가 발생)
행정구역별(읍면동): ‘1 레벨’과 ’2 레벨’ 선택(’1 레벨’은 시도 수준, ’2 레벨’은 시군구 수준)
조회기간: ‘기간설정’ 버튼을 누른 후, 기간설정이 2023~2023년인지 확인한다.
응답필드: 하나씩 눌러 모두 선택한 후, ‘URL생성’ 탭을 클릭한다. 그리고 나서 ‘URL 복사’ 탭을 클릭한다. URL 속에 api key가 포함되어 있음을 확인한
생성한 URL로부터 데이터 획득
your_url <- "Your URL"
data_api <- getStatDataFromURL(url = your_url)getStatDataFromURL 함수의 아규먼트에 위에서 생성한 URL을 입력하면, 다운로드 과정 없이 곧바로 데이터를 획득할 수 있다.
data_api |>
head(n = 10) ORG_ID TBL_ID TBL_NM C1 C1_NM C1_OBJ_NM C2
1 101 DT_1IN1503 연령 및 성별 인구 – 읍면동 00 전국 행정구역별(읍면동) 000
2 101 DT_1IN1503 연령 및 성별 인구 – 읍면동 00 전국 행정구역별(읍면동) 000
3 101 DT_1IN1503 연령 및 성별 인구 – 읍면동 00 전국 행정구역별(읍면동) 000
4 101 DT_1IN1503 연령 및 성별 인구 – 읍면동 00 전국 행정구역별(읍면동) 005
5 101 DT_1IN1503 연령 및 성별 인구 – 읍면동 00 전국 행정구역별(읍면동) 005
6 101 DT_1IN1503 연령 및 성별 인구 – 읍면동 00 전국 행정구역별(읍면동) 005
7 101 DT_1IN1503 연령 및 성별 인구 – 읍면동 00 전국 행정구역별(읍면동) 010
8 101 DT_1IN1503 연령 및 성별 인구 – 읍면동 00 전국 행정구역별(읍면동) 010
9 101 DT_1IN1503 연령 및 성별 인구 – 읍면동 00 전국 행정구역별(읍면동) 010
10 101 DT_1IN1503 연령 및 성별 인구 – 읍면동 00 전국 행정구역별(읍면동) 015
C2_NM C2_OBJ_NM ITM_ID ITM_NM ITM_NM_ENG PRD_SE PRD_DE
1 합계 연령별 T00 총인구(명) Population A 2023
2 합계 연령별 T01 총인구_남자(명) Population_Male A 2023
3 합계 연령별 T02 총인구_여자(명) Population_Female A 2023
4 0~4세 연령별 T00 총인구(명) Population A 2023
5 0~4세 연령별 T01 총인구_남자(명) Population_Male A 2023
6 0~4세 연령별 T02 총인구_여자(명) Population_Female A 2023
7 5~9세 연령별 T00 총인구(명) Population A 2023
8 5~9세 연령별 T01 총인구_남자(명) Population_Male A 2023
9 5~9세 연령별 T02 총인구_여자(명) Population_Female A 2023
10 10~14세 연령별 T00 총인구(명) Population A 2023
DT
1 51774521
2 25903852
3 25870669
4 1361737
5 697702
6 664035
7 1980026
8 1014945
9 965081
10 22776634.4 데이터 정리 및 변형
아래와 같이 데이터를 정리 및 변형한다. 최종적으로 지역별 지역소멸위험지수를 산출한다.
data <- data_api |>
select(C1, C1_NM, C2, C2_NM, ITM_ID, ITM_NM, DT) |>
mutate(
across(c(C1, DT), as.numeric),
ITM_ID = case_match(
ITM_ID, "T00" ~ "T",
"T01" ~ "M",
"T02" ~ "F"),
) |>
unite("gender_age", ITM_ID, C2_NM, sep = "_") |>
pivot_wider(
id_cols = c(C1, C1_NM),
names_from = gender_age,
values_from = DT
) |>
mutate(
index = (`F_20~24세` + `F_25~29세` + `F_30~34세` + `F_35~39세`) / `T_65세이상`
) |>
select(
C1, C1_NM, index
)시도 데이터와 시군구 데이터를 분리하여 저장한다.
4.5 그래프 작성
인구소멸위험지수 연구에서 주로 사용되는 5개의 위험도 클래스의 구분법을 적용하고, 위험도 클래스별로 특정한 색상을 적용하고, 그래프의 범례에 5개의 클래스가 모두 나타나게 하려다보니 코드가 조금 복잡해졌다.
data_sido <- data_sido |>
mutate(
index_class = case_when(
index < 0.2 ~ "1",
index >= 0.2 & index < 0.5 ~ "2",
index >= 0.5 & index < 1.0 ~ "3",
index >= 1.0 & index < 1.5 ~ "4",
index >= 1.5 ~ "5"
),
index_class = factor(index_class, levels = as.character(1:5))
)
class_color <- c("1" = "#d7191c", "2" = "#fdae61",
"3" = "#ffffbf", "4" = "#a6d96a",
"5" = "#1a9641")
data_sido |>
ggplot(aes(x = index, y = fct_reorder(C1_NM, index))) +
geom_col(aes(fill = index_class), show.legend = TRUE) +
geom_text(aes(label = format(round(index, digits = 3),
nsmall = 3)), hjust = -0.1) +
scale_x_continuous(limits = c(0, 1.5)) +
scale_fill_manual(name = "Classes",
labels = c("< 0.2", "0.2 ~ 0.5", "0.5 ~ 1.0",
"1.0 ~ 1.5", ">= 1.5"),
values = class_color, drop = FALSE) +
labs(title = "인구소멸위험지수, 2022년",
x = "인구소멸위험지수",
y = "")
이렇게 KOSIS 홈페이지에서 URL을 직접 지정하지 않고도 데이터를 불러오는 방법이 있다. getStatData 함수로, 기관명과 데이터 코드를 아규먼트에 입력하면 해당 데이터를 불러올 수 있다. 가령 방금 실습에서 사용한 데이터는 통계청의 2015년 인구총조사 전수부문의 연령 및 성별인구에 해당한다. 이때 통계청의 기관 코드는 101, 해당 데이터의 코드는 DT_1IN503이다.
아래의 코드는 여기에 몇 개의 아규먼트를 더 추가하여 서울특별시 종로구의 2015년부터 2022년까지의 데이터를 불러오고, 이를 바탕으로 인구소멸지수를 계산하여 그 추이를 시각화 한 것이다.
aoi_code <- "11010" # 서울특별시 종로구 코드
aoi <- getStatData(orgId = 101, tblId = "DT_1IN1503", prdSe = "Y",
startPrdDe = "2015", endPrdDe = "2022",
objL1 = aoi_code, objL2 = "ALL") |>
filter(nchar(C2) == 3)
aoi <- aoi |>
select(C1, C1_NM, C2, C2_NM, ITM_ID, ITM_NM, DT, PRD_DE) |>
filter(ITM_ID == "T00" | ITM_ID == "T01" | ITM_ID == "T02") |>
mutate(
across(c(C1, DT), as.numeric),
ITM_ID = case_match(
ITM_ID, "T00" ~ "T",
"T01" ~ "M",
"T02" ~ "F"),
) |>
unite("gender_age", ITM_ID, C2_NM, sep = "_") |>
pivot_wider(
id_cols = c(C1, C1_NM, PRD_DE),
names_from = gender_age,
values_from = DT
) |>
mutate(
index = (`F_20~24세` + `F_25~29세` + `F_30~34세` + `F_35~39세`) / `T_65세이상`
) |>
select(
C1, C1_NM, index, PRD_DE
)
region <- aoi$C1_NM[1]aoi |>
ggplot(aes(x=PRD_DE, y=index)) +
geom_point() +
geom_line(group = 1, linewidth = 0.5) +
ggtitle(paste0(region, " 인구소멸위험지수 추이")) +
xlab(label = "연도") +
ylab(label = "인구소멸위험지수") +
theme(plot.title = element_text(size = 18, hjust=0.5))
aoi_code에 내가 원하는 지역의 코드를 넣으면 마찬가지로 해당 관심지역의 인구소멸위험지수 추이를 관측할 수 있다. 예컨대 인구가 빠르게 증가하는 경기 김포시는 “31230”, 화성시는 “31240”이고, 소멸지수가 가장 높은 경북 상주시는 “37080”, 경북 문경시는 “37090”이다. 제공한 코드에서 한번 aoi_code 부분만 변경해보자.
한편, 이렇게 URL 없이 데이터를 불러오는 경우 KOSIS에서 직접 조정하는 것에 비해 덜 번거롭지만 제한사항도 많다. 가령 복수의 지역을 불러오는 것이 반복문을 사용하지 않고서는 불가능하고, 불필요한 데이터를 빼고 가져오기도 어렵다. 그러나 startPrdDe와 endPrdDe 아규먼트를 이용해 데이터를 시계열로 수집하고자 하는 측면에서는 유용하다.
그러므로 수집하고자 하는 데이터를 잘 파악해서 API를 활용해보자.
4.6 cf) KOSIS API를 활용한 함수 작성
마지막으로, API를 활용한 함수를 소개한다. API를 신청할 때 보았듯, 이는 웹/앱 애플리케이션을 제작하기 위한 용도로 주로 사용된다.
이와 관련된 매우 간단한 예시로, 학생에게 인구소멸지수가 궁금한 지역을 검색해보도록 하는 활동을 구상한다고 가정해보자. 학생이 매번 코드를 작성하며 확인하기란 사실상 불가능하다. 그런데 위에서 사용한 코드와 API를 활용하면 함수를 어렵지 않게 생성할 수 있다.
예컨대 교사가 아래와 같이 exInd() 함수를 한번 작성해두면, 학생은 단 한 줄의 코드만 입력해도 금방 지역의 인구소멸지수의 추이를 탐색해볼 수 있을 것이다.
# 함수 생성: 교사 작성 부분
exInd <- function(){
# Library
library(tidyverse)
library(kosis)
library(DT)
library(openxlsx)
# Table for Searching Region Code
region_table <- read.xlsx("https://github.com/Sechang-Kim/gis-lab/raw/download/korea-sigungu-code(2022).xlsx")
print(datatable(region_table))
# Input Arguments
aoi_code <- readline('지역 코드를 입력하세요: ')
start <- as.numeric(readline('시작 연도를 입력하세요: '))
end <- as.numeric(readline('종료 연도를 입력하세요: '))
# Data Request
aoi <- getStatData(orgId = 101, tblId = "DT_1IN1503", prdSe = "Y",
startPrdDe = start, endPrdDe = end,
objL1 = aoi_code, objL2 = "ALL") |>
filter(nchar(C2) == 3) # Delete 1-age interval(Only 5-age interval)
# Data Cleansing
aoi <- aoi |>
select(C1, C1_NM, C2, C2_NM, ITM_ID, ITM_NM, DT, PRD_DE) |>
filter(ITM_ID == "T00" | ITM_ID == "T01" | ITM_ID == "T02") |>
mutate(
across(c(C1, DT), as.numeric),
ITM_ID = case_match(
ITM_ID, "T00" ~ "T",
"T01" ~ "M",
"T02" ~ "F"),
) |>
unite("gender_age", ITM_ID, C2_NM, sep = "_") |>
pivot_wider(
id_cols = c(C1, C1_NM, PRD_DE),
names_from = gender_age,
values_from = DT
) |>
mutate(
index = (`F_20~24세` + `F_25~29세` + `F_30~34세` + `F_35~39세`) / `T_65세이상`
) |>
select(
C1, C1_NM, index, PRD_DE
)
## Visualization
region <- aoi$C1_NM[1] # For Auto-Plot Title
vis <- aoi |>
ggplot(aes(x=PRD_DE, y=index)) +
geom_point() +
geom_line(group = 1, linewidth = 0.5) +
ggtitle(paste0(region, " 인구소멸위험지수 추이")) +
xlab(label = "연도") +
ylab(label = "인구소멸위험지수") +
theme(plot.title = element_text(size = 18, hjust=0.5))
return(vis)
}# 함수 실행: 학생 작성 부분
exInd()