




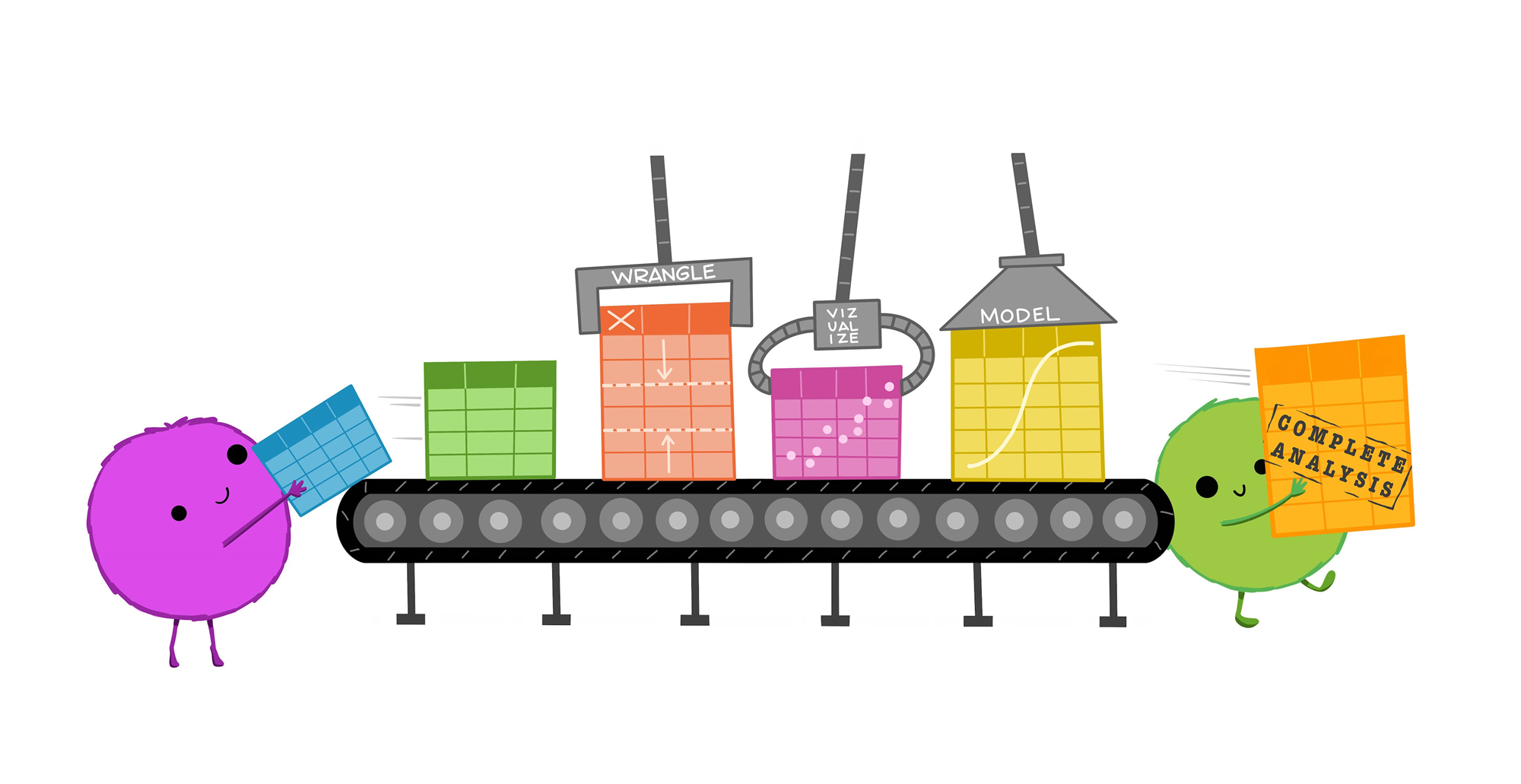
ingredients <- tibble(우유, 계란, 밀가루)
mix_result <- mix(ingredients, 강도, 혼합시간, ...)
bake_result <- bake(mix_result, 온도, 굽기시간, ...)
decorate_result <- decorate(bake_result, 장식1, 장식2, ...)
slice_result <- slice(decorate_result, 절단도구, 등분수, ...)
오픈소스(R) 프로그래밍 1
데이터 불러오기ㆍ정돈하기ㆍ변형하기
데이터 불러오기ㆍ정돈하기ㆍ변형하기
이상일(서울대학교 지리교육과 교수)
2025-12-31
R 개관
R의 탄생: R의 아버지들(1993년)
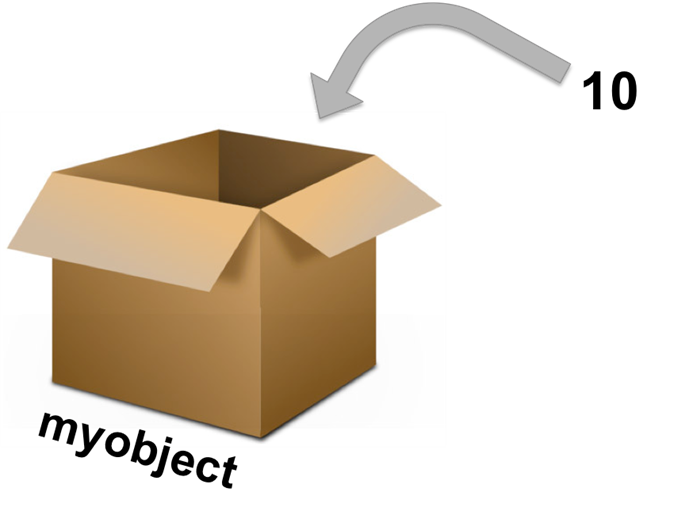
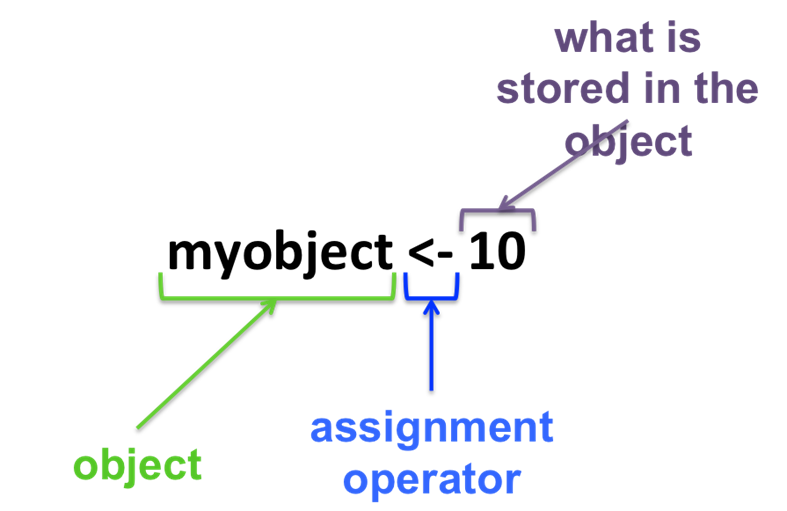
Base R: 할당 연산자
Base R: 주요 산술 함수
| 분류 | 함수 |
|---|---|
| 절대값/부호 |
abs(), sign()
|
| 제곱근/지수 |
sqrt(), exp()
|
| 로그 |
log(), log10(), log2()
|
| 삼각함수 |
sin(), cos(), tan(), asin()
|
| 반올림 |
round(), floor(), ceiling(), trunc()
|
| 요약 |
sum(), mean(), median(), var(), sd(), min(), max(), range(), summary()
|
IDE: RStudio(2011년)
IDE(integrated development environment, 통합개발환경)


IDE: RStudio(2011년)

데이터사이언스와 R: posit(2022년)

데이터사이언스와 R: 혁신가

Hadley Wickham
Chief Scientist at Posit
데이터사이언스와 R: 타이디버스
“정돈된 데이터(tidy data) 처리와 분석을 위한 하나의 우주적 생태계”
-
데이터사이언스를 일관성 있게 수행하기 위한 패키지들의 패키지
데이터사이언스와 R: 타이디버스
타이디 디자인 원리(Tidy Design Principles)
-
인간중심성 Human-centeredness
- For an end-user programmer
-
일관성 Consistency
- The smallest possible set of key ideas, used as comprehensively as possible
-
조합성 Composability
- Many simple pieces, composed for a larger task using operators such as |> and +
-
포용성 Inclusiveness
- Towards a diverse, open, and friendly community
데이터사이언스와 R: 파이프 연산자

데이터사이언스와 R: 파이프 연산자
slice_result <- slice(
decorate(
bake(
mix(
tibble(
우유, 계란, 밀가루
), 강도, 혼합시간, ...
), 온도, 굽기시간, ...
), 장식1, 장식2, ...
), 절단도구, 등분수, ...
) slice_result <- tibble(우유, 계란, 밀가루) |>
mix(강도, 혼합시간, ...) |>
bake(온도, 굽기시간, ...) |>
decorate(장식1, 장식2, ...) |>
slice(절단도구, 등분수, ...)데이터사이언스와 R: 파이프 연산자

Ctrl + Shift + M
No error, no gain!

데이터 불러오기
데이터사이언스 프로세스
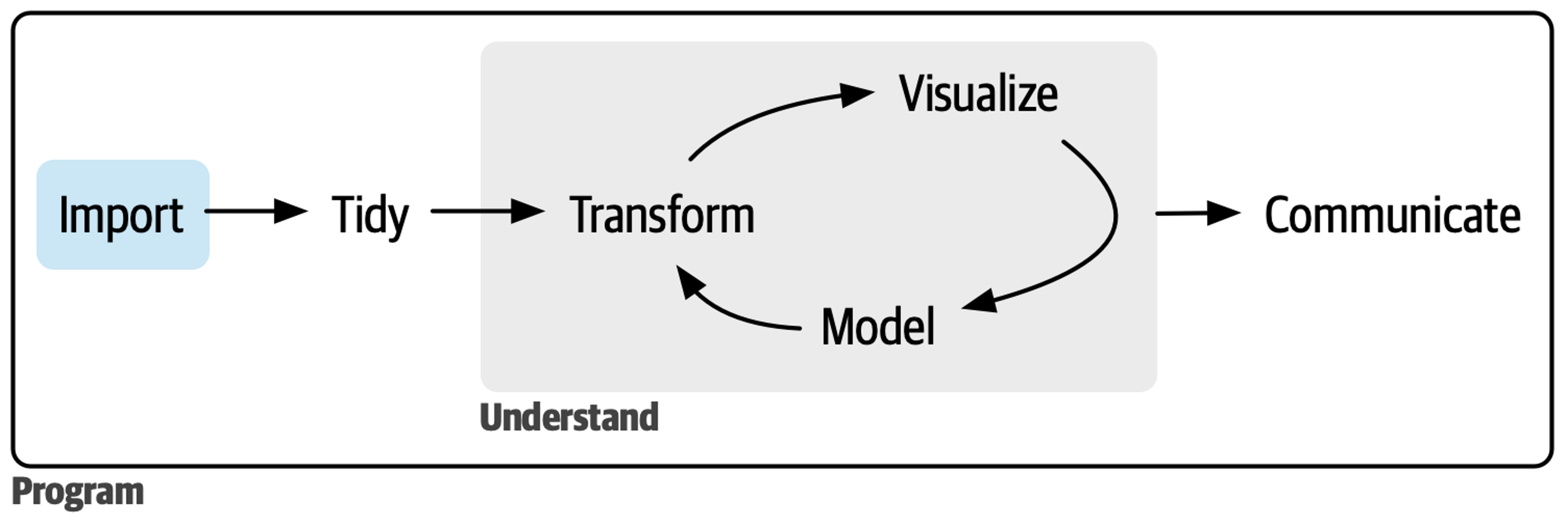
https://r4ds.hadley.nz/import.html
- 데이터 불러오기(importing): 데이터를 ‘가져와’ R 객체로 만들기
데이터사이언스 프로세스: 타이디버스
tibble 패키지

tibble vs. data.frame
df_1 a b c d e
1 TRUE 58 3.19 이상일 남자
2 FALSE 26 2.09 김우형 남자
3 FALSE 22 2.03 박서우 여자df_2# A tibble: 3 × 5
a b c d e
<lgl> <int> <dbl> <chr> <chr>
1 TRUE 58 3.19 이상일 남자
2 FALSE 26 2.09 김우형 남자
3 FALSE 22 2.03 박서우 여자 readr 패키지

readr 패키지: 주요 불러오기 함수
| 함수명 | 포맷 |
|---|---|
read_csv() |
콤마분리(comma-separated values, CSV) 형식 |
read_csv2() |
세미콜론분리(semicolon-separated) 형식 |
read_tsv() |
탭구분(tab-limited) 형식 |
read_delim() |
여타의 구분 형식 |
read_fwf() |
고정폭(fixed-width) 형식 |
read_table() |
공백구분 형식 |
read_log() |
아파치 형식(Apache-style)의 로그 파일 |
readr 패키지: 주요 파싱(parsing) 함수
| 컬럼 유형 | 새로운 벡터 | 기존 벡터 |
|---|---|---|
논리형 lgl
|
col_logical() |
parse_logical() |
정수형 int
|
col_integer() |
parse_integer() |
실수형 dbl
|
col_double() |
parse_double() |
문자형 chr
|
col_character() |
parse_character() |
범주형 fct
|
col_factor() |
parse_factor() |
read_csv() 함수의 활용
# A tibble: 6 × 5
`Student ID` `Full Name` favourite.food mealPlan AGE
<dbl> <chr> <chr> <chr> <chr>
1 1 Sunil Huffmann Strawberry yoghurt Lunch only 4
2 2 Barclay Lynn French fries Lunch only 5
3 3 Jayendra Lyne N/A Breakfast and lunch 7
4 4 Leon Rossini Anchovies Lunch only <NA>
5 5 Chidiegwu Dunkel Pizza Breakfast and lunch five
6 6 Güvenç Attila Ice cream Lunch only 6 library(tidyverse)
read_csv(
file = "https://pos.it/r4ds-students-csv",
skip = 1,
col_names = c("student_id", "full_name", "favorite_food", "meal_plan", "age"),
col_types = cols(
meal_plan = col_factor(),
age = col_number()
),
na = c("N/A")
)# A tibble: 6 × 5
student_id full_name favorite_food meal_plan age
<dbl> <chr> <chr> <fct> <dbl>
1 1 Sunil Huffmann Strawberry yoghurt Lunch only 4
2 2 Barclay Lynn French fries Lunch only 5
3 3 Jayendra Lyne <NA> Breakfast and lunch 7
4 4 Leon Rossini Anchovies Lunch only NA
5 5 Chidiegwu Dunkel Pizza Breakfast and lunch NA
6 6 Güvenç Attila Ice cream Lunch only 6관련 패키지



readxl 패키지
-
read_xls(), read_xlsx(), read_excel()path: 파일 경로와 파일명sheet: 특정 시트의 선택range: 특정 범위의 셀 선택skip: 불러들이지 않을 최소 행 번호col_names: 컬럼 이름 지정col_types: 컬럼 데이터 유형 지정(“skip”, “guess”, “text”, “logical”, “numeric”, etc.)na: 결측치 규정
데이터 정돈하기
데이터사이언스 프로세스
https://r4ds.hadley.nz/import.html
- 데이터 정돈하기(tidying): 불러온 데이터를 ‘정돈된(tidy)’ 데이터로 만들기
데이터사이언스 프로세스: 타이디버스
tidyr 패키지

’정돈된 데이터’의 정의
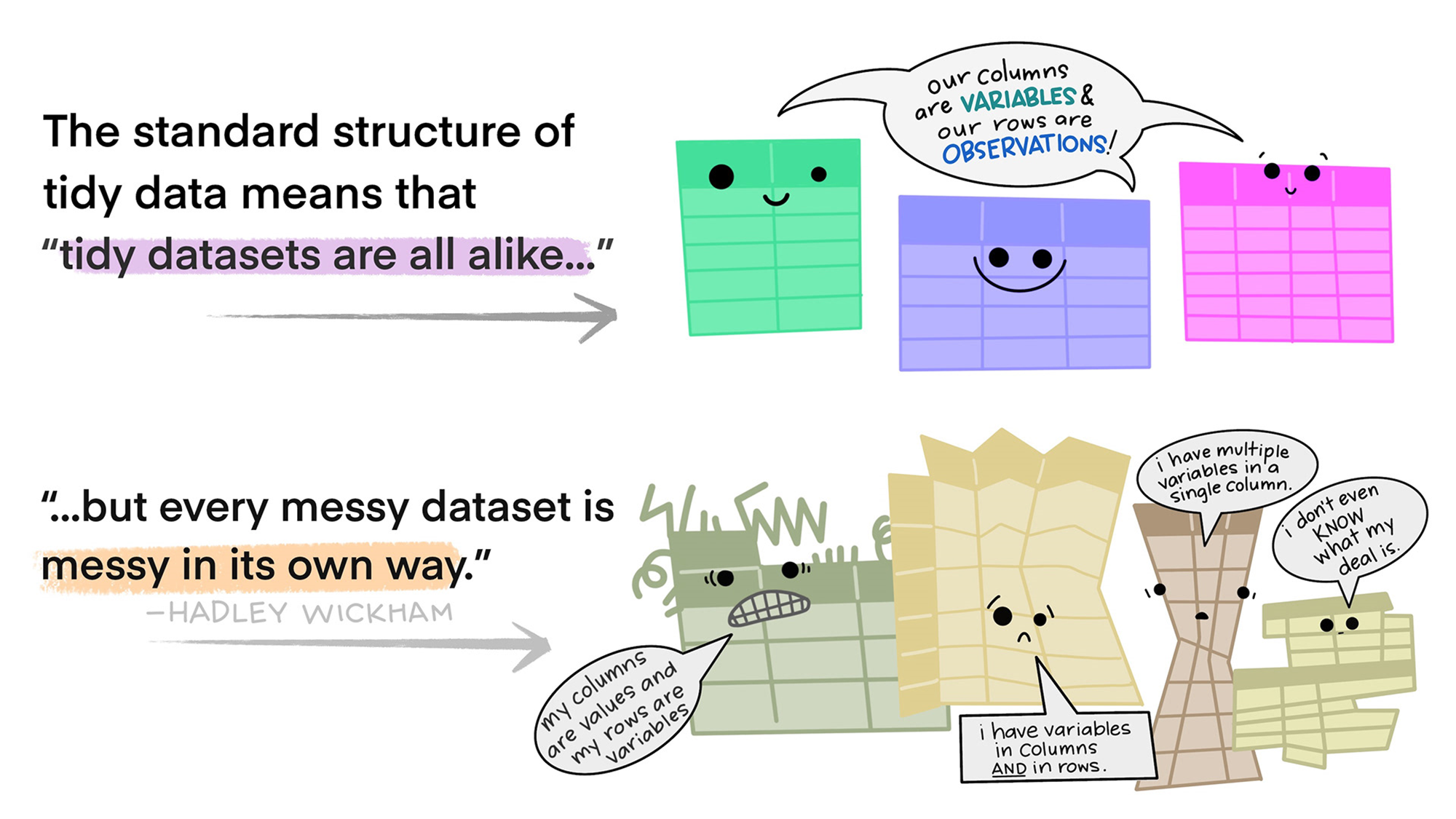
’정돈된 데이터’의 정의

’정돈된 데이터’의 정의
개별 변수(variable)는 열(column) 하나를 차지한다. 즉, 개별 열에는 하나의 변수가 위치한다.
개별 관측개체(observation)는 하나의 행(row)을 차지한다. 즉, 개별 행에는 하나의 관측개체가 위치한다.
개별 값(value)은 하나의 셀(cell)을 차지한다. 즉, 개별 셀에는 하나의 값이 위치한다.
’정돈된 데이터’의 예시
table4a# A tibble: 3 × 3
country `1999` `2000`
<chr> <dbl> <dbl>
1 Afghanistan 745 2666
2 Brazil 37737 80488
3 China 212258 213766table2# A tibble: 12 × 4
country year type count
<chr> <dbl> <chr> <dbl>
1 Afghanistan 1999 cases 745
2 Afghanistan 1999 population 19987071
3 Afghanistan 2000 cases 2666
4 Afghanistan 2000 population 20595360
5 Brazil 1999 cases 37737
6 Brazil 1999 population 172006362
7 Brazil 2000 cases 80488
8 Brazil 2000 population 174504898
9 China 1999 cases 212258
10 China 1999 population 1272915272
11 China 2000 cases 213766
12 China 2000 population 1280428583table3# A tibble: 6 × 3
country year rate
<chr> <dbl> <chr>
1 Afghanistan 1999 745/19987071
2 Afghanistan 2000 2666/20595360
3 Brazil 1999 37737/172006362
4 Brazil 2000 80488/174504898
5 China 1999 212258/1272915272
6 China 2000 213766/1280428583’정돈된 데이터’의 이점
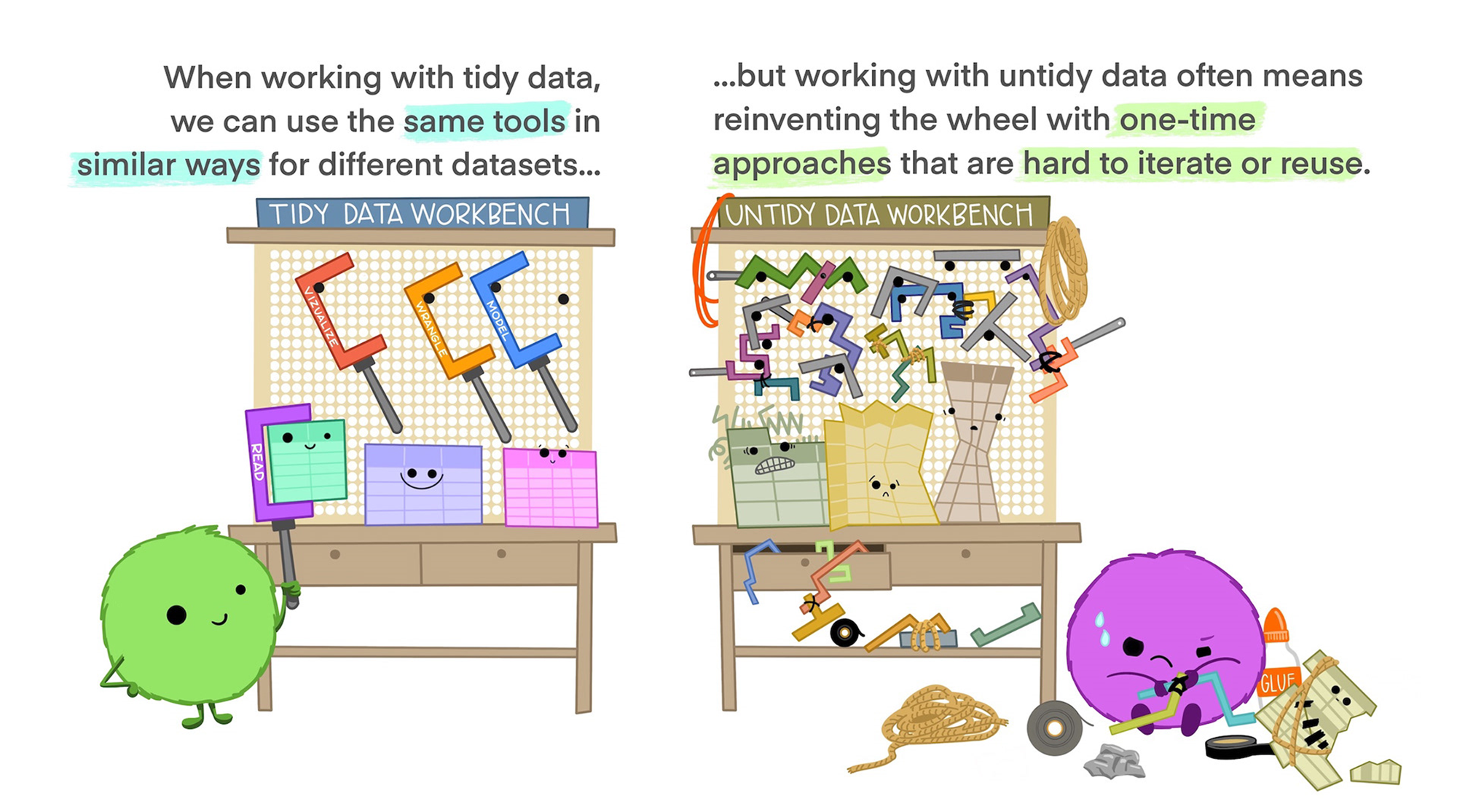
’정돈된 데이터’의 이점
’정돈된 데이터’의 이점

데이터 정돈하기의 핵심 기능
-
데이터 구조 변형
- 핵심 기능으로 데이터 늘이기와 데이터 넓히기가 포함
-
컬럼의 결합 및 분할
- 두 개 이상의 컬럼을 하나의 컬럼으로 결합하거나 하나의 컬럼을 두 개 이상의 컬럼으로 분할
-
결측치 처리
- 결측치가 포함된 행을 다양한 방식으로 처리
데이터 구조 변형
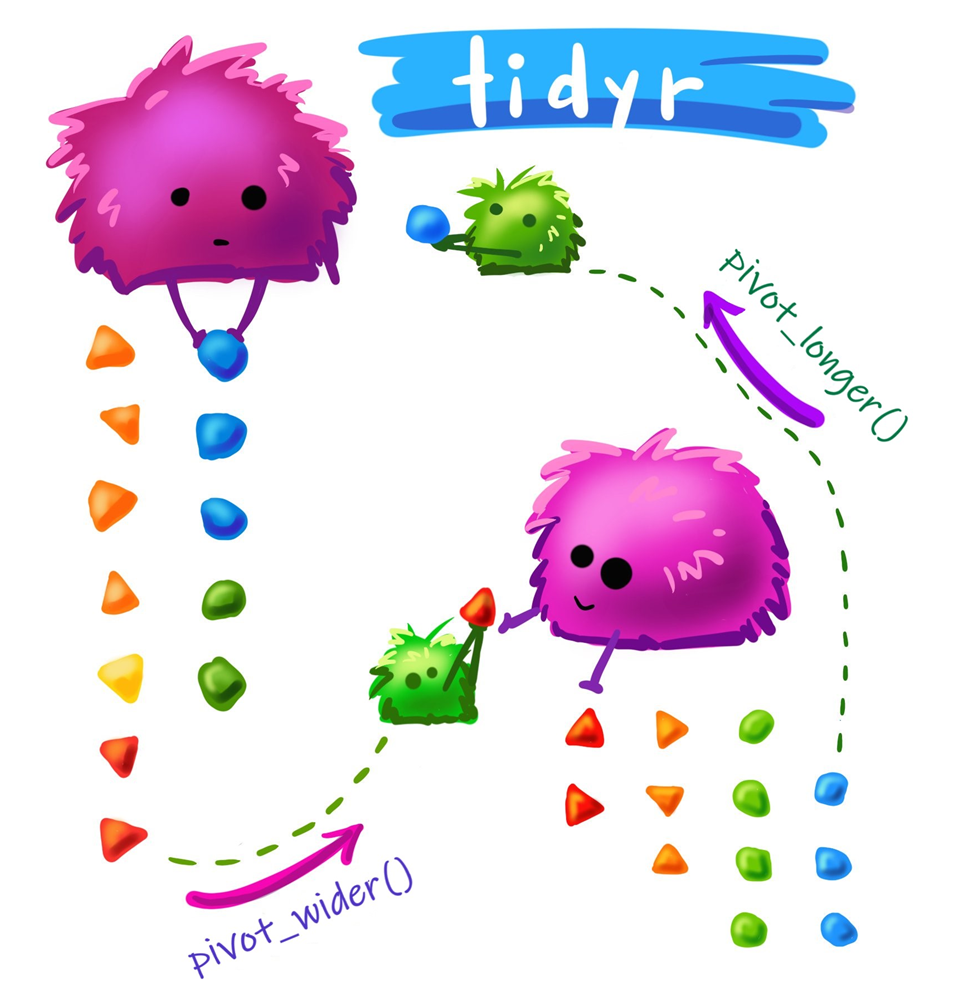
와이드 폼(wide form) vs. 롱 폼(long form)

데이터 늘이기: pivot_longer()
table4a# A tibble: 3 × 3
country `1999` `2000`
<chr> <dbl> <dbl>
1 Afghanistan 745 2666
2 Brazil 37737 80488
3 China 212258 213766table4a |>
pivot_longer(
cols = c(`1999`, `2000`),
names_to = "year",
values_to = "cases"
)# A tibble: 6 × 3
country year cases
<chr> <chr> <dbl>
1 Afghanistan 1999 745
2 Afghanistan 2000 2666
3 Brazil 1999 37737
4 Brazil 2000 80488
5 China 1999 212258
6 China 2000 213766데이터 늘이기: pivot_longer()

데이터 넓히기: pivot_wider()
table2# A tibble: 12 × 4
country year type count
<chr> <dbl> <chr> <dbl>
1 Afghanistan 1999 cases 745
2 Afghanistan 1999 population 19987071
3 Afghanistan 2000 cases 2666
4 Afghanistan 2000 population 20595360
5 Brazil 1999 cases 37737
6 Brazil 1999 population 172006362
7 Brazil 2000 cases 80488
8 Brazil 2000 population 174504898
9 China 1999 cases 212258
10 China 1999 population 1272915272
11 China 2000 cases 213766
12 China 2000 population 1280428583table2 |>
pivot_wider(
id_cols = c(country, year),
names_from = type,
values_from = count
)# A tibble: 6 × 4
country year cases population
<chr> <dbl> <dbl> <dbl>
1 Afghanistan 1999 745 19987071
2 Afghanistan 2000 2666 20595360
3 Brazil 1999 37737 172006362
4 Brazil 2000 80488 174504898
5 China 1999 212258 1272915272
6 China 2000 213766 1280428583데이터 넓히기: pivot_wider()

컬럼의 결합 및 분할
table3# A tibble: 6 × 3
country year rate
<chr> <dbl> <chr>
1 Afghanistan 1999 745/19987071
2 Afghanistan 2000 2666/20595360
3 Brazil 1999 37737/172006362
4 Brazil 2000 80488/174504898
5 China 1999 212258/1272915272
6 China 2000 213766/1280428583table3 |> separate_wider_delim(
rate, delim = "/", names = c("cases", "population")
) # A tibble: 6 × 4
country year cases population
<chr> <dbl> <chr> <chr>
1 Afghanistan 1999 745 19987071
2 Afghanistan 2000 2666 20595360
3 Brazil 1999 37737 172006362
4 Brazil 2000 80488 174504898
5 China 1999 212258 1272915272
6 China 2000 213766 1280428583데이터 변형하기
데이터사이언스 프로세스
https://r4ds.hadley.nz/transform.html
- 데이터 변형하기(transform): 정돈된 데이터에 구조적ㆍ의미적 변동을 가해 다음 단계(시각화 및 모델링)에 적합한 상태로 만드는 과정
데이터사이언스 프로세스: 타이디버스
dplyr 패키지

dplyr 패키지: 기본 원리
함수의 이름은 기본적으로 동사이다.
첫 번째 아규먼트는 항상 데이터 프레임이다.
그 다음 아규먼트(들)는 데이터 변형에 결부되는 변수(들)를 지정한다 .
산출물은 항상 데이터 프레임이다.
dplyr 패키지: 기능 분류
단일 테이블 조작: 데이터 변형하기의 핵심 부분으로, 한 데이터 프레임의 데이터 구조를 조작
다중 테이블 결합: 두 개 이상의 데이터 프레임을 결합
단일 테이블 조작 함수의 유형
행(rows) 함수: 행에 적용되는 함수, 즉 행의 변화를 야기하는 함수
열(columns) 함수: 열에 적용되는 함수, 즉 열의 변화를 야기하는 함수
그룹(groups) 함수: 그룹에 적용되는 함수
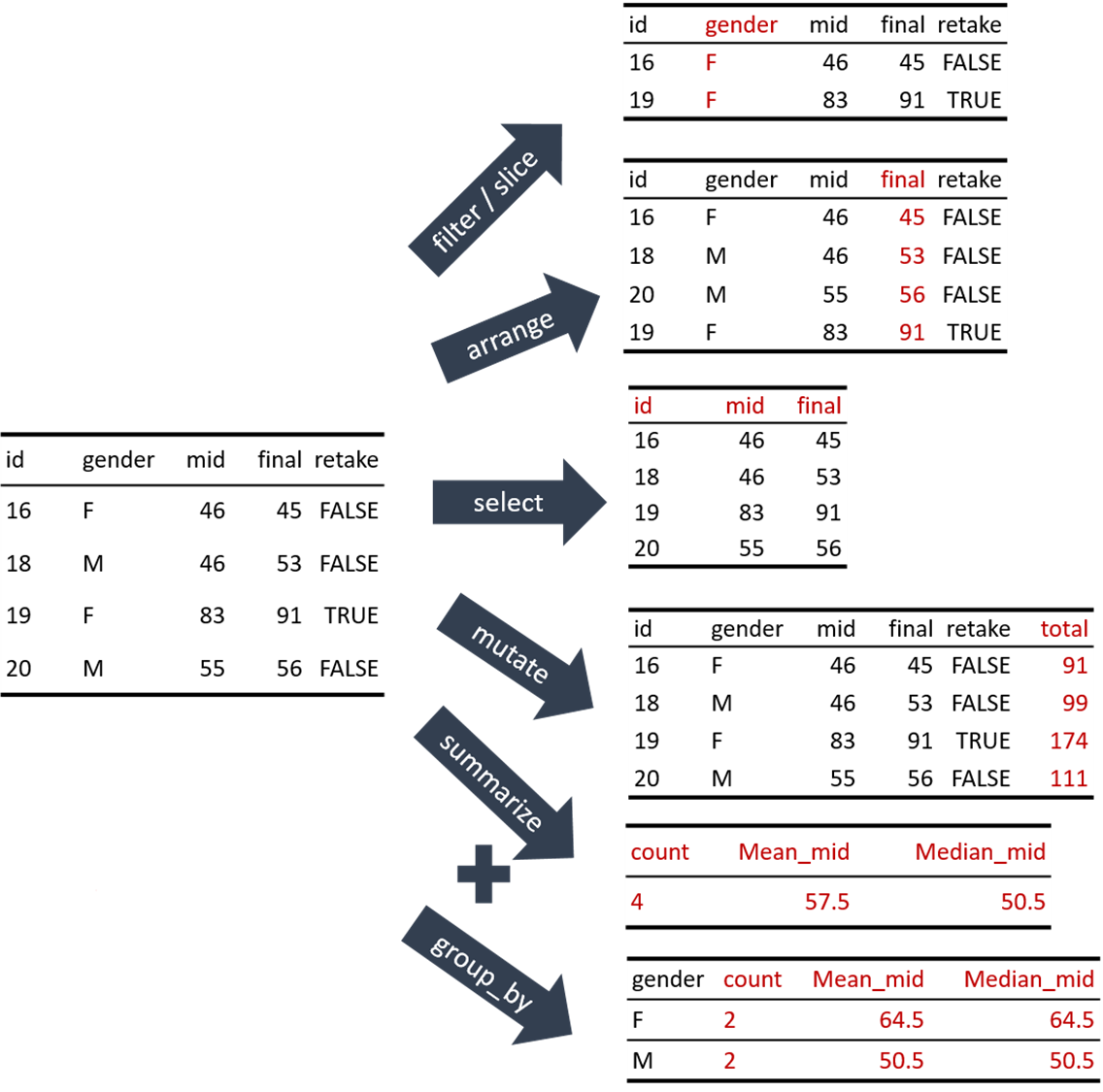
https://kilhwan.github.io/rprogramming/ch-dataTransformation.html
행 함수: 네 개의 주요 함수
filter(): 특정 변수(들)에 의거한 조건을 만족하는 행(들)을 추출arrange(): 특정 변수(들)에 의거해 행(들)의 순서를 변경distinct(): 특정 변수(들)에 의거해 (중복을 제거한) 고유한 행(들)을 추출-
slice():filter()함수처럼 특정 행(들)을 추출특정 변수와 관계 없이, 행의 위치에 의거해 특정 행(들)을 추출
특정 변수에 따른, 행의 위치에 의거해 행(들)을 추출
행 함수 1: filter()
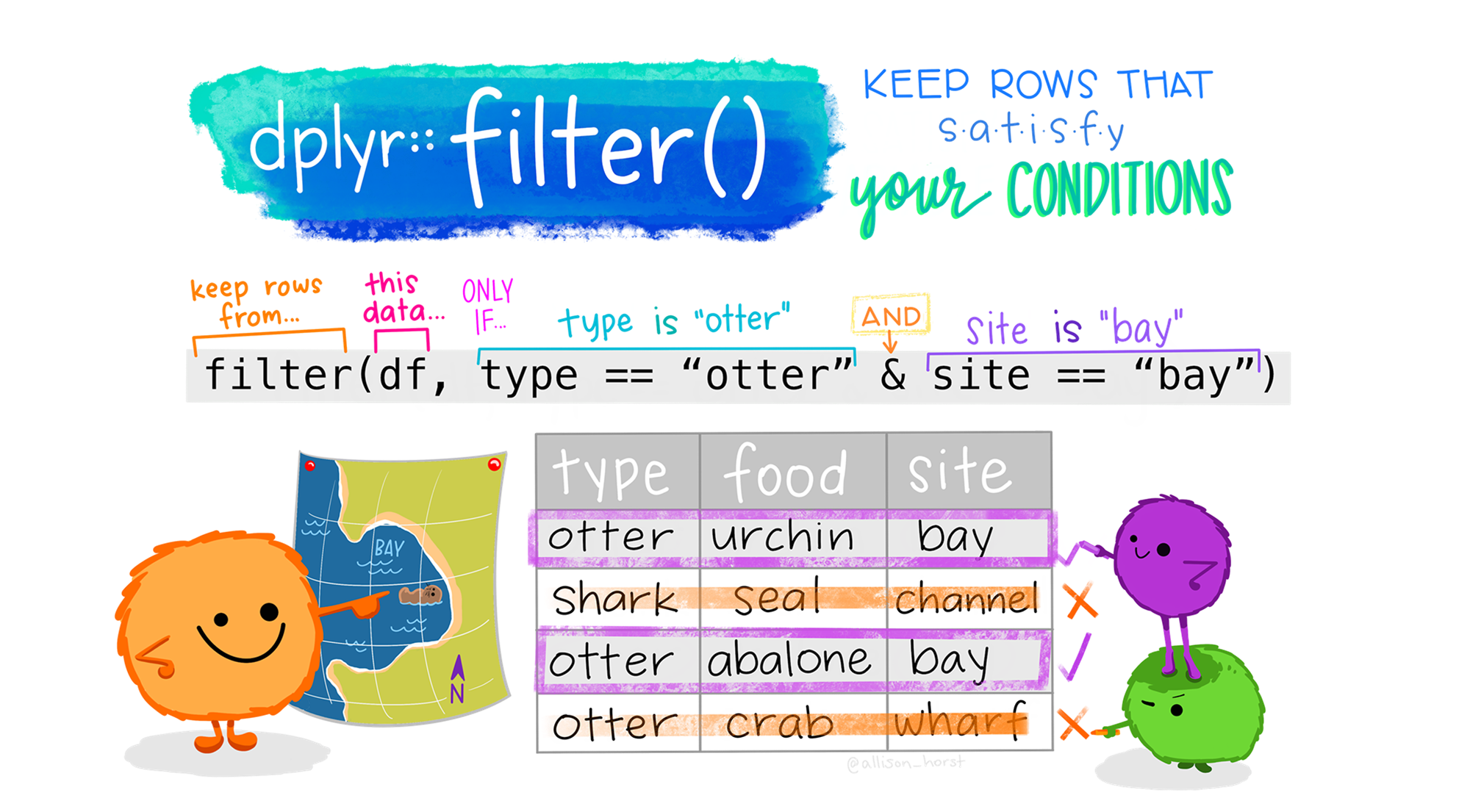
행 함수 1: filter()

행 함수 1: filter()
# A tibble: 6 × 4
country year cases population
<chr> <dbl> <dbl> <dbl>
1 Afghanistan 1999 745 19987071
2 Afghanistan 2000 2666 20595360
3 Brazil 1999 37737 172006362
4 Brazil 2000 80488 174504898
5 China 1999 212258 1272915272
6 China 2000 213766 1280428583filter(table1, year == 2000)# A tibble: 3 × 4
country year cases population
<chr> <dbl> <dbl> <dbl>
1 Afghanistan 2000 2666 20595360
2 Brazil 2000 80488 174504898
3 China 2000 213766 1280428583table1 |>
filter(
year == 2000 & population > 50000000
)# A tibble: 2 × 4
country year cases population
<chr> <dbl> <dbl> <dbl>
1 Brazil 2000 80488 174504898
2 China 2000 213766 1280428583행 함수 2: arrange()

행 함수 2: arrange()
# A tibble: 6 × 4
country year cases population
<chr> <dbl> <dbl> <dbl>
1 Afghanistan 1999 745 19987071
2 Afghanistan 2000 2666 20595360
3 Brazil 1999 37737 172006362
4 Brazil 2000 80488 174504898
5 China 1999 212258 1272915272
6 China 2000 213766 1280428583arrange(table1, cases)# A tibble: 6 × 4
country year cases population
<chr> <dbl> <dbl> <dbl>
1 Afghanistan 1999 745 19987071
2 Afghanistan 2000 2666 20595360
3 Brazil 1999 37737 172006362
4 Brazil 2000 80488 174504898
5 China 1999 212258 1272915272
6 China 2000 213766 1280428583행 함수 3: distinct()

행 함수 3: distinct()
# A tibble: 6 × 4
country year cases population
<chr> <dbl> <dbl> <dbl>
1 Afghanistan 1999 745 19987071
2 Afghanistan 2000 2666 20595360
3 Brazil 1999 37737 172006362
4 Brazil 2000 80488 174504898
5 China 1999 212258 1272915272
6 China 2000 213766 1280428583distinct(table1, country)# A tibble: 3 × 1
country
<chr>
1 Afghanistan
2 Brazil
3 China table1 |>
distinct(
country, .keep_all = TRUE
)# A tibble: 3 × 4
country year cases population
<chr> <dbl> <dbl> <dbl>
1 Afghanistan 1999 745 19987071
2 Brazil 1999 37737 172006362
3 China 1999 212258 1272915272행 함수 4: slice()

행 함수 4: slice()
# A tibble: 6 × 4
country year cases population
<chr> <dbl> <dbl> <dbl>
1 Afghanistan 1999 745 19987071
2 Afghanistan 2000 2666 20595360
3 Brazil 1999 37737 172006362
4 Brazil 2000 80488 174504898
5 China 1999 212258 1272915272
6 China 2000 213766 1280428583slice(table1, 2:3)# A tibble: 2 × 4
country year cases population
<chr> <dbl> <dbl> <dbl>
1 Afghanistan 2000 2666 20595360
2 Brazil 1999 37737 172006362table1 |>
slice_head(n = 2)# A tibble: 2 × 4
country year cases population
<chr> <dbl> <dbl> <dbl>
1 Afghanistan 1999 745 19987071
2 Afghanistan 2000 2666 20595360table1 |>
slice_tail(prop = 1/3)# A tibble: 2 × 4
country year cases population
<chr> <dbl> <dbl> <dbl>
1 China 1999 212258 1272915272
2 China 2000 213766 1280428583table1 |>
slice_max(cases, n = 2)# A tibble: 2 × 4
country year cases population
<chr> <dbl> <dbl> <dbl>
1 China 2000 213766 1280428583
2 China 1999 212258 1272915272table1 |>
slice_min(cases, prop = 1/3)# A tibble: 2 × 4
country year cases population
<chr> <dbl> <dbl> <dbl>
1 Afghanistan 1999 745 19987071
2 Afghanistan 2000 2666 20595360table1 |>
slice_sample(n = 2, replace = TRUE)# A tibble: 2 × 4
country year cases population
<chr> <dbl> <dbl> <dbl>
1 Brazil 2000 80488 174504898
2 Afghanistan 1999 745 19987071열 함수: 네 개의 주요 함수
select(): 변수(들) 중 일부를 추출mutate(): 변수(들)를 변형해 새로운 변수를 생성rename(): 변수(들)의 이름을 변경relocate(): 변수(들)의 위치(순서)를 변경
열 함수 1: select()

열 함수 1: select()
# A tibble: 6 × 4
country year cases population
<chr> <dbl> <dbl> <dbl>
1 Afghanistan 1999 745 19987071
2 Afghanistan 2000 2666 20595360
3 Brazil 1999 37737 172006362
4 Brazil 2000 80488 174504898
5 China 1999 212258 1272915272
6 China 2000 213766 1280428583select(table1, country, year)# A tibble: 6 × 2
country year
<chr> <dbl>
1 Afghanistan 1999
2 Afghanistan 2000
3 Brazil 1999
4 Brazil 2000
5 China 1999
6 China 2000table1 |>
select(-cases, -population)# A tibble: 6 × 2
country year
<chr> <dbl>
1 Afghanistan 1999
2 Afghanistan 2000
3 Brazil 1999
4 Brazil 2000
5 China 1999
6 China 2000열 함수 2: mutate()

열 함수 2: mutate()

열 함수 2: mutate()
# A tibble: 6 × 4
country year cases population
<chr> <dbl> <dbl> <dbl>
1 Afghanistan 1999 745 19987071
2 Afghanistan 2000 2666 20595360
3 Brazil 1999 37737 172006362
4 Brazil 2000 80488 174504898
5 China 1999 212258 1272915272
6 China 2000 213766 1280428583mutate(table1, rate = cases / population)# A tibble: 6 × 5
country year cases population rate
<chr> <dbl> <dbl> <dbl> <dbl>
1 Afghanistan 1999 745 19987071 0.0000373
2 Afghanistan 2000 2666 20595360 0.000129
3 Brazil 1999 37737 172006362 0.000219
4 Brazil 2000 80488 174504898 0.000461
5 China 1999 212258 1272915272 0.000167
6 China 2000 213766 1280428583 0.000167 # A tibble: 6 × 6
country year cases population rate continent
<chr> <dbl> <dbl> <dbl> <dbl> <chr>
1 Afghanistan 1999 745 19987071 0.0000373 Asia
2 Afghanistan 2000 2666 20595360 0.000129 Asia
3 Brazil 1999 37737 172006362 0.000219 Americas
4 Brazil 2000 80488 174504898 0.000461 Americas
5 China 1999 212258 1272915272 0.000167 Asia
6 China 2000 213766 1280428583 0.000167 Asia 열 함수 3: rename()
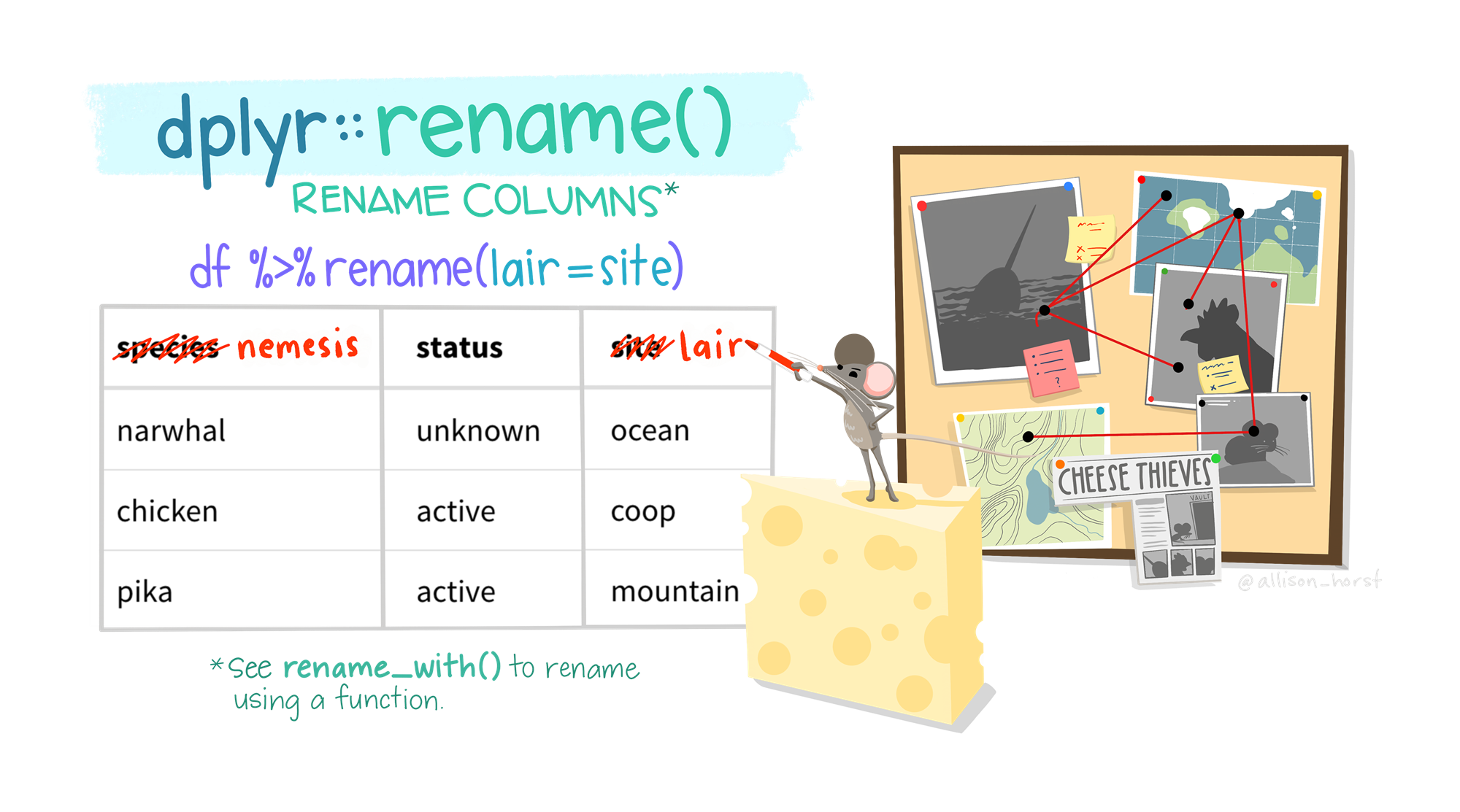
열 함수 3: rename()

열 함수 3: rename()
# A tibble: 6 × 6
country year cases population rate continent
<chr> <dbl> <dbl> <dbl> <dbl> <chr>
1 Afghanistan 1999 745 19987071 0.0000373 Asia
2 Afghanistan 2000 2666 20595360 0.000129 Asia
3 Brazil 1999 37737 172006362 0.000219 Americas
4 Brazil 2000 80488 174504898 0.000461 Americas
5 China 1999 212258 1272915272 0.000167 Asia
6 China 2000 213766 1280428583 0.000167 Asia rename(table1_new, cont = continent)# A tibble: 6 × 6
country year cases population rate cont
<chr> <dbl> <dbl> <dbl> <dbl> <chr>
1 Afghanistan 1999 745 19987071 0.0000373 Asia
2 Afghanistan 2000 2666 20595360 0.000129 Asia
3 Brazil 1999 37737 172006362 0.000219 Americas
4 Brazil 2000 80488 174504898 0.000461 Americas
5 China 1999 212258 1272915272 0.000167 Asia
6 China 2000 213766 1280428583 0.000167 Asia table1_new |>
rename(
cont = continent,
pop = population
)# A tibble: 6 × 6
country year cases pop rate cont
<chr> <dbl> <dbl> <dbl> <dbl> <chr>
1 Afghanistan 1999 745 19987071 0.0000373 Asia
2 Afghanistan 2000 2666 20595360 0.000129 Asia
3 Brazil 1999 37737 172006362 0.000219 Americas
4 Brazil 2000 80488 174504898 0.000461 Americas
5 China 1999 212258 1272915272 0.000167 Asia
6 China 2000 213766 1280428583 0.000167 Asia 열 함수 4: relocate()

열 함수 4: relocate()

열 함수 4: relocate()
# A tibble: 6 × 6
country year cases population rate continent
<chr> <dbl> <dbl> <dbl> <dbl> <chr>
1 Afghanistan 1999 745 19987071 0.0000373 Asia
2 Afghanistan 2000 2666 20595360 0.000129 Asia
3 Brazil 1999 37737 172006362 0.000219 Americas
4 Brazil 2000 80488 174504898 0.000461 Americas
5 China 1999 212258 1272915272 0.000167 Asia
6 China 2000 213766 1280428583 0.000167 Asia relocate(table1_new, year, continent)# A tibble: 6 × 6
year continent country cases population rate
<dbl> <chr> <chr> <dbl> <dbl> <dbl>
1 1999 Asia Afghanistan 745 19987071 0.0000373
2 2000 Asia Afghanistan 2666 20595360 0.000129
3 1999 Americas Brazil 37737 172006362 0.000219
4 2000 Americas Brazil 80488 174504898 0.000461
5 1999 Asia China 212258 1272915272 0.000167
6 2000 Asia China 213766 1280428583 0.000167 table1_new |>
relocate(
rate,
.before = year
)# A tibble: 6 × 6
country rate year cases population continent
<chr> <dbl> <dbl> <dbl> <dbl> <chr>
1 Afghanistan 0.0000373 1999 745 19987071 Asia
2 Afghanistan 0.000129 2000 2666 20595360 Asia
3 Brazil 0.000219 1999 37737 172006362 Americas
4 Brazil 0.000461 2000 80488 174504898 Americas
5 China 0.000167 1999 212258 1272915272 Asia
6 China 0.000167 2000 213766 1280428583 Asia 그룹 함수: 네 개의 주요 함수
group_by(): 변수(들)에 의거해 전체 행(들)을 그룹으로 분할summarize(): 그룹별로 변수(들)의 요약 통계량을 산출하여 새로운 변수(들)로 저장count(): 그룹별로 해당 관측개체의 빈도수를 계산across(): 그룹별로 여러 변수에 걸쳐 동일한 통계량을 산출하고 새로운 변수들로 저장
그룹 함수 1: group_by()

그룹 함수 1: group_by()
# A tibble: 6 × 6
country year cases population rate continent
<chr> <dbl> <dbl> <dbl> <dbl> <chr>
1 Afghanistan 1999 745 19987071 0.0000373 Asia
2 Afghanistan 2000 2666 20595360 0.000129 Asia
3 Brazil 1999 37737 172006362 0.000219 Americas
4 Brazil 2000 80488 174504898 0.000461 Americas
5 China 1999 212258 1272915272 0.000167 Asia
6 China 2000 213766 1280428583 0.000167 Asia group_by(table1_new, continent)# A tibble: 6 × 6
# Groups: continent [2]
country year cases population rate continent
<chr> <dbl> <dbl> <dbl> <dbl> <chr>
1 Afghanistan 1999 745 19987071 0.0000373 Asia
2 Afghanistan 2000 2666 20595360 0.000129 Asia
3 Brazil 1999 37737 172006362 0.000219 Americas
4 Brazil 2000 80488 174504898 0.000461 Americas
5 China 1999 212258 1272915272 0.000167 Asia
6 China 2000 213766 1280428583 0.000167 Asia table1_new |>
group_by(continent, year)# A tibble: 6 × 6
# Groups: continent, year [4]
country year cases population rate continent
<chr> <dbl> <dbl> <dbl> <dbl> <chr>
1 Afghanistan 1999 745 19987071 0.0000373 Asia
2 Afghanistan 2000 2666 20595360 0.000129 Asia
3 Brazil 1999 37737 172006362 0.000219 Americas
4 Brazil 2000 80488 174504898 0.000461 Americas
5 China 1999 212258 1272915272 0.000167 Asia
6 China 2000 213766 1280428583 0.000167 Asia 그룹 함수 2: summarize()

그룹 함수 2: summarize()
# A tibble: 6 × 6
country year cases population rate continent
<chr> <dbl> <dbl> <dbl> <dbl> <chr>
1 Afghanistan 1999 745 19987071 0.0000373 Asia
2 Afghanistan 2000 2666 20595360 0.000129 Asia
3 Brazil 1999 37737 172006362 0.000219 Americas
4 Brazil 2000 80488 174504898 0.000461 Americas
5 China 1999 212258 1272915272 0.000167 Asia
6 China 2000 213766 1280428583 0.000167 Asia 그룹 함수 1 + 2: group_by() + summarize()
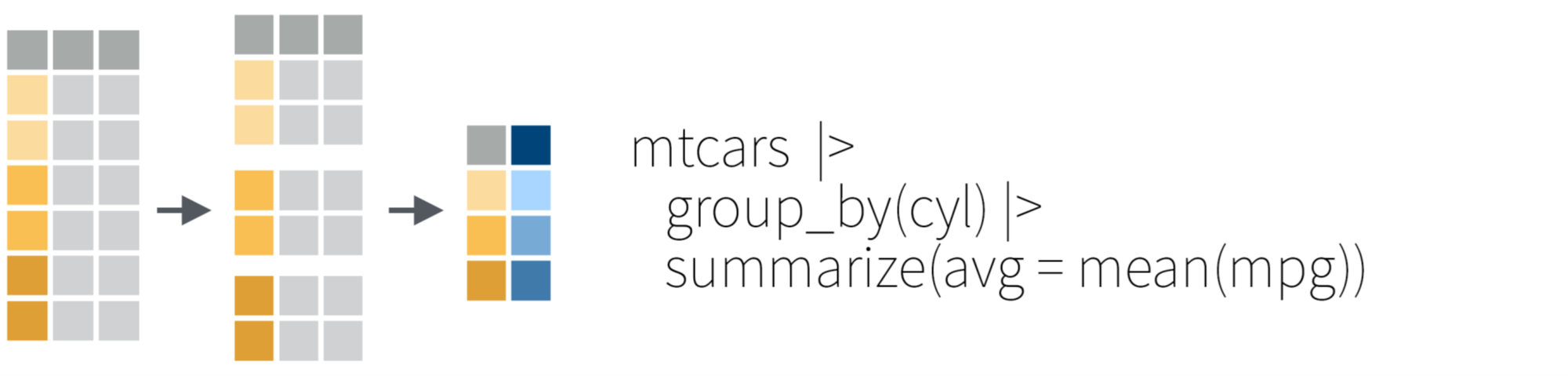
그룹 함수 1 + 2: group_by() + summarize()
# A tibble: 6 × 6
country year cases population rate continent
<chr> <dbl> <dbl> <dbl> <dbl> <chr>
1 Afghanistan 1999 745 19987071 0.0000373 Asia
2 Afghanistan 2000 2666 20595360 0.000129 Asia
3 Brazil 1999 37737 172006362 0.000219 Americas
4 Brazil 2000 80488 174504898 0.000461 Americas
5 China 1999 212258 1272915272 0.000167 Asia
6 China 2000 213766 1280428583 0.000167 Asia # A tibble: 4 × 4
# Groups: continent [2]
continent year sum_cases mean_rate
<chr> <dbl> <dbl> <dbl>
1 Americas 1999 37737 0.000219
2 Americas 2000 80488 0.000461
3 Asia 1999 213003 0.000102
4 Asia 2000 216432 0.000148# A tibble: 4 × 5
continent year sum_cases sum_pop rate
<chr> <dbl> <dbl> <dbl> <dbl>
1 Americas 1999 37737 172006362 0.000219
2 Americas 2000 80488 174504898 0.000461
3 Asia 1999 213003 1292902343 0.000165
4 Asia 2000 216432 1301023943 0.000166그룹 함수 3: count()

그룹 함수 3: count()
# A tibble: 6 × 6
country year cases population rate continent
<chr> <dbl> <dbl> <dbl> <dbl> <chr>
1 Afghanistan 1999 745 19987071 0.0000373 Asia
2 Afghanistan 2000 2666 20595360 0.000129 Asia
3 Brazil 1999 37737 172006362 0.000219 Americas
4 Brazil 2000 80488 174504898 0.000461 Americas
5 China 1999 212258 1272915272 0.000167 Asia
6 China 2000 213766 1280428583 0.000167 Asia count(table1_new, year, continent)# A tibble: 4 × 3
year continent n
<dbl> <chr> <int>
1 1999 Americas 1
2 1999 Asia 2
3 2000 Americas 1
4 2000 Asia 2table1_new |>
count(year, continent, wt = cases)# A tibble: 4 × 3
year continent n
<dbl> <chr> <dbl>
1 1999 Americas 37737
2 1999 Asia 213003
3 2000 Americas 80488
4 2000 Asia 216432그룹 함수 4: across()

그룹 함수 4: across()
# A tibble: 6 × 6
country year cases population rate continent
<chr> <dbl> <dbl> <dbl> <dbl> <chr>
1 Afghanistan 1999 745 19987071 0.0000373 Asia
2 Afghanistan 2000 2666 20595360 0.000129 Asia
3 Brazil 1999 37737 172006362 0.000219 Americas
4 Brazil 2000 80488 174504898 0.000461 Americas
5 China 1999 212258 1272915272 0.000167 Asia
6 China 2000 213766 1280428583 0.000167 Asia 다중 테이블 결합: 종류
테이블 조인(join): 두 개 데이터 프레임을 공통키(common key)를 이용해 결합함으로써 하나의 데이터 프레임을 생성
테이블 병합(merge): 두 데이터 프레임을 결합해 새로운 단일한 프레임을 생성한다는 의미에서는 테이블 조인과 동일하지만, 공통키가 없으며, 행과 열 중 하나는 반드시 동일해야 함.
테이블 조인: 키(key)
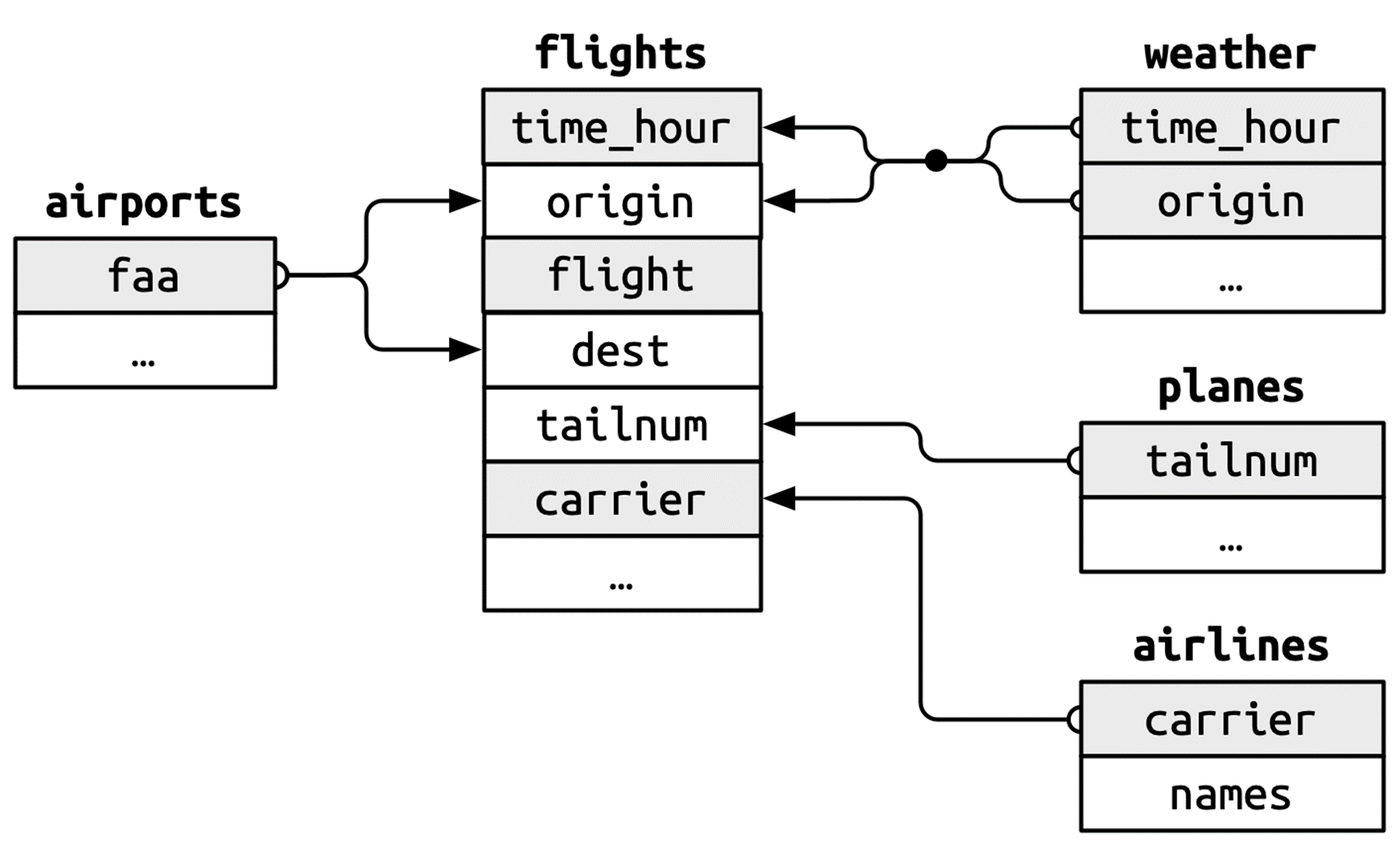
테이블 조인: 유형
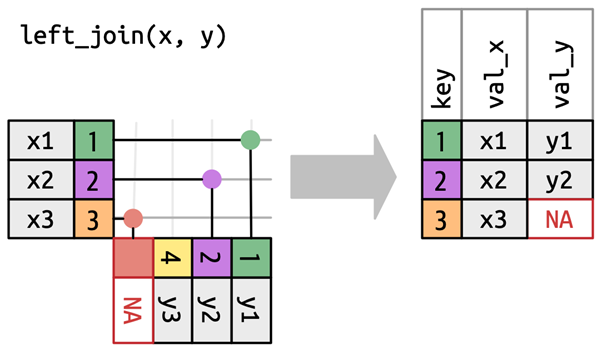
left_join(): 첫 번째 테이블은 그대로 둔 상태에서 두 번째 테이블을 결합함으로써 두 번째 테이블의 열을 가져옴right_join(): 두 번째 테이블은 그대로 둔 상태에서 첫 번째 테이블을 결합함으로써 첫 번째 테이블의 열을 가져옴inner_join(): 두 테이블 모두에 존재하는 열을 취함full_join(): 최소한 한 테이블에 존재하는 열을 모두 취함semi_join(): 첫 번째 테이블의 행 중 두 번째 테이블에 대응하는 행이 있는 것만 취함anti_join(): 첫 번째 테이블의 행 중 두 번째 테이블에 대응하는 행이 없는 것만 취함
테이블 조인: 유형
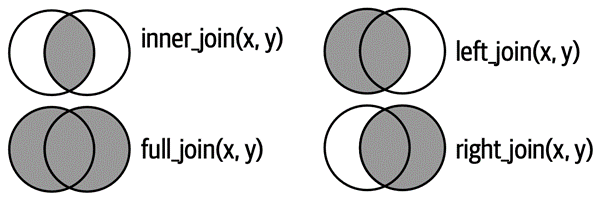
테이블 조인: 유형
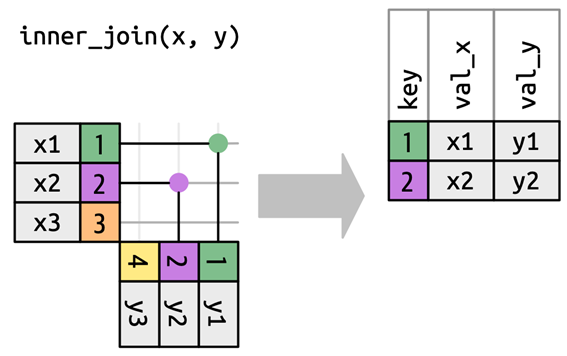
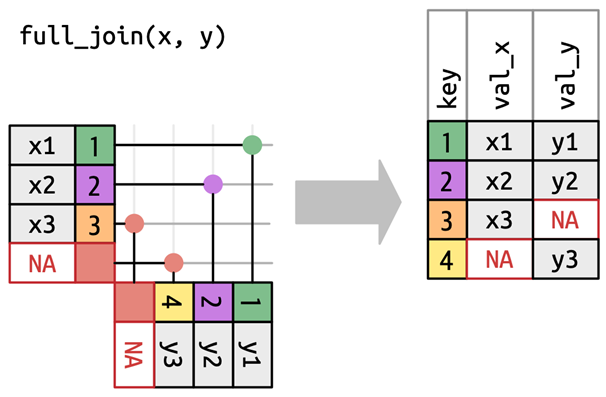
테이블 조인: 유형
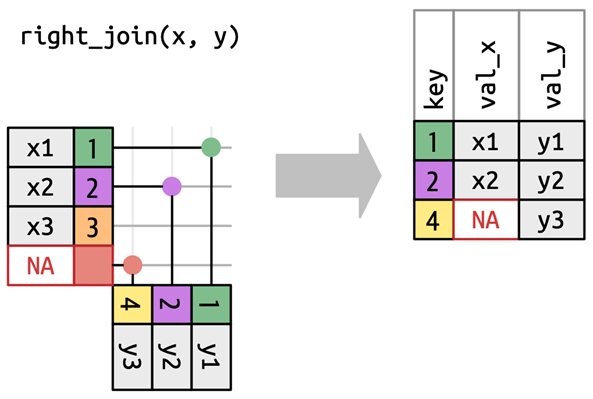
테이블 병합: 주요 함수
-
bind_row(): 컬럼이 동일한 두 테이블을 상하로 연결 -
bind_col(): 행이 동일한 두 테이블을 좌우로 연결
테이블 병합: 주요 함수
gapminder_merge_row <- bind_rows(
gap_1957, gap_1982, gap_2007
)
gapminder_merge_row# A tibble: 426 × 6
country continent year lifeExp pop gdpPercap
<fct> <fct> <int> <dbl> <int> <dbl>
1 Afghanistan Asia 1957 30.3 9240934 821.
2 Albania Europe 1957 59.3 1476505 1942.
3 Algeria Africa 1957 45.7 10270856 3014.
4 Angola Africa 1957 32.0 4561361 3828.
5 Argentina Americas 1957 64.4 19610538 6857.
6 Australia Oceania 1957 70.3 9712569 10950.
7 Austria Europe 1957 67.5 6965860 8843.
8 Bahrain Asia 1957 53.8 138655 11636.
9 Bangladesh Asia 1957 39.3 51365468 662.
10 Belgium Europe 1957 69.2 8989111 9715.
# ℹ 416 more rowsgapminder_merge_col <- bind_cols(gap_var1, gap_var2)
gapminder_merge_col# A tibble: 1,704 × 6
country continent year lifeExp pop gdpPercap
<fct> <fct> <int> <dbl> <int> <dbl>
1 Afghanistan Asia 1952 28.8 8425333 779.
2 Afghanistan Asia 1957 30.3 9240934 821.
3 Afghanistan Asia 1962 32.0 10267083 853.
4 Afghanistan Asia 1967 34.0 11537966 836.
5 Afghanistan Asia 1972 36.1 13079460 740.
6 Afghanistan Asia 1977 38.4 14880372 786.
7 Afghanistan Asia 1982 39.9 12881816 978.
8 Afghanistan Asia 1987 40.8 13867957 852.
9 Afghanistan Asia 1992 41.7 16317921 649.
10 Afghanistan Asia 1997 41.8 22227415 635.
# ℹ 1,694 more rows
https://sangillee.snu.ac.kr/