Day 2
데이터 수집 및 정련화
데이터 수집 및 정련화
2024-08-06
데이터사이언스 프로세스의 첫번째와 두번째 단계
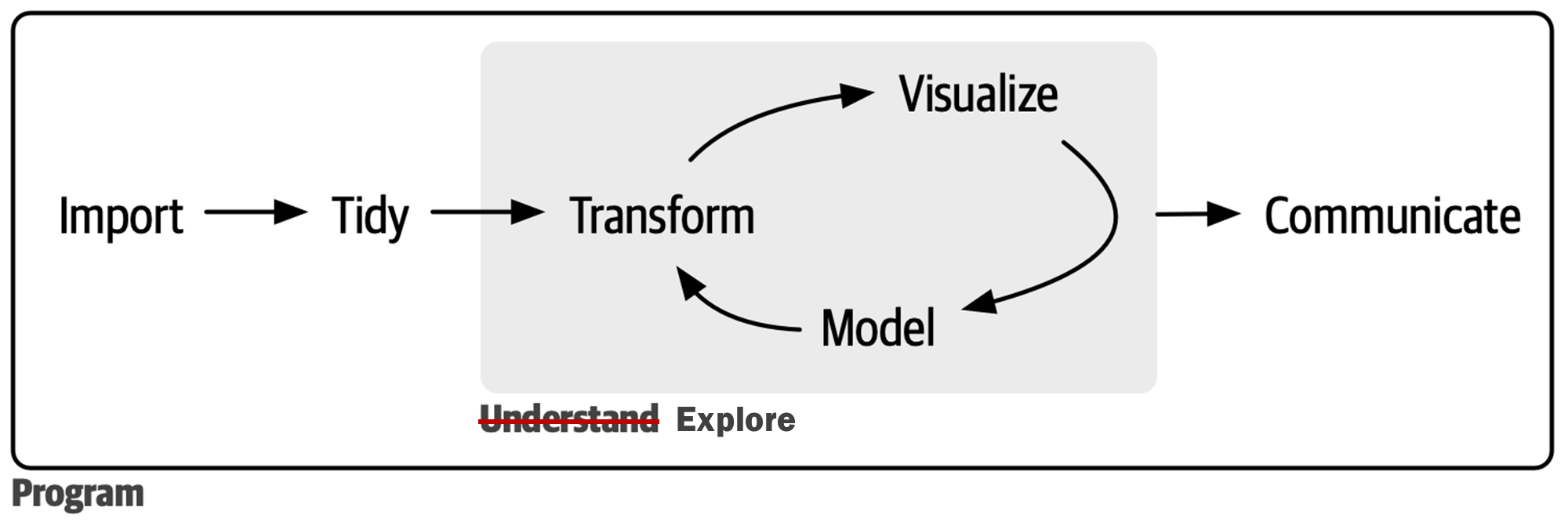
내용
-
데이터 수집하기
웹스크레이핑(webscraping)
오픈 API의 활용
데이터 불러오기
데이터 정돈하기
데이터 수집하기: 웹스크레이핑
정의
- 웹페이지로부터 데이터를 추출하는 것, 데이터 긁어 오기
- 데이터 크롤링(crawling)과 유사, 박박 기면서 수집하기
- 해킹(hacking)과의 경계가 모호
- 허가 없이 정보 시스템에 침투하여 데이터를 취득하는 행위
- 최근들어 점점 회피하는 추세
HTML의 정의
-
HyperText Markup Language, 하이퍼텍스터 마크업 언어
-
웹 브라우저를 통해 표출되는 사항(무엇이 어떻게)을 프로그래밍하는 마크업(markup) 언어 혹은 웹 다큐먼트를 작성하는 마크업 언어
- 마크업 언어: 다큐먼트의 구조와 포맷을 관장하는 텍스트-엔코딩 시스템
-
-
마크다운(markdown) 언어
사용자의 편이성이 강화된 마크업 언어
Quarto: 비주얼 에디터
HTML의 기초 1
-
웹페이지는 다양한 태그(tag)로 구성
- 각 태그는 시작 태그와 종료 태그로 구성되며, 둘 사이에 해당 콘텐츠가 위치
-
태그의 종류는 다양하며, 크게 세 가지로 구분
최상위인 html 태그
-
웹페이지의 전반적인 구조를 결정하는 블록(block) 태그
- 예: h1, section, p, ol 태그 등
-
블록 태그 내부의 특정 부분에만 적용되는 인라인(inline) 태그
- 예: b, i, a 태그 등
HTML의 기초 2
태그들은 복잡한 다단계 구조를 이룸
-
태그는 속성(attribute)를 가질 수 있음
특별히 중요한 속성: 클래스(class), 아이디(id)
p나 div 태그와 같은 블록 태그: height, width, margin, padding
img 태그: src, alt, width, height
a 태그: href
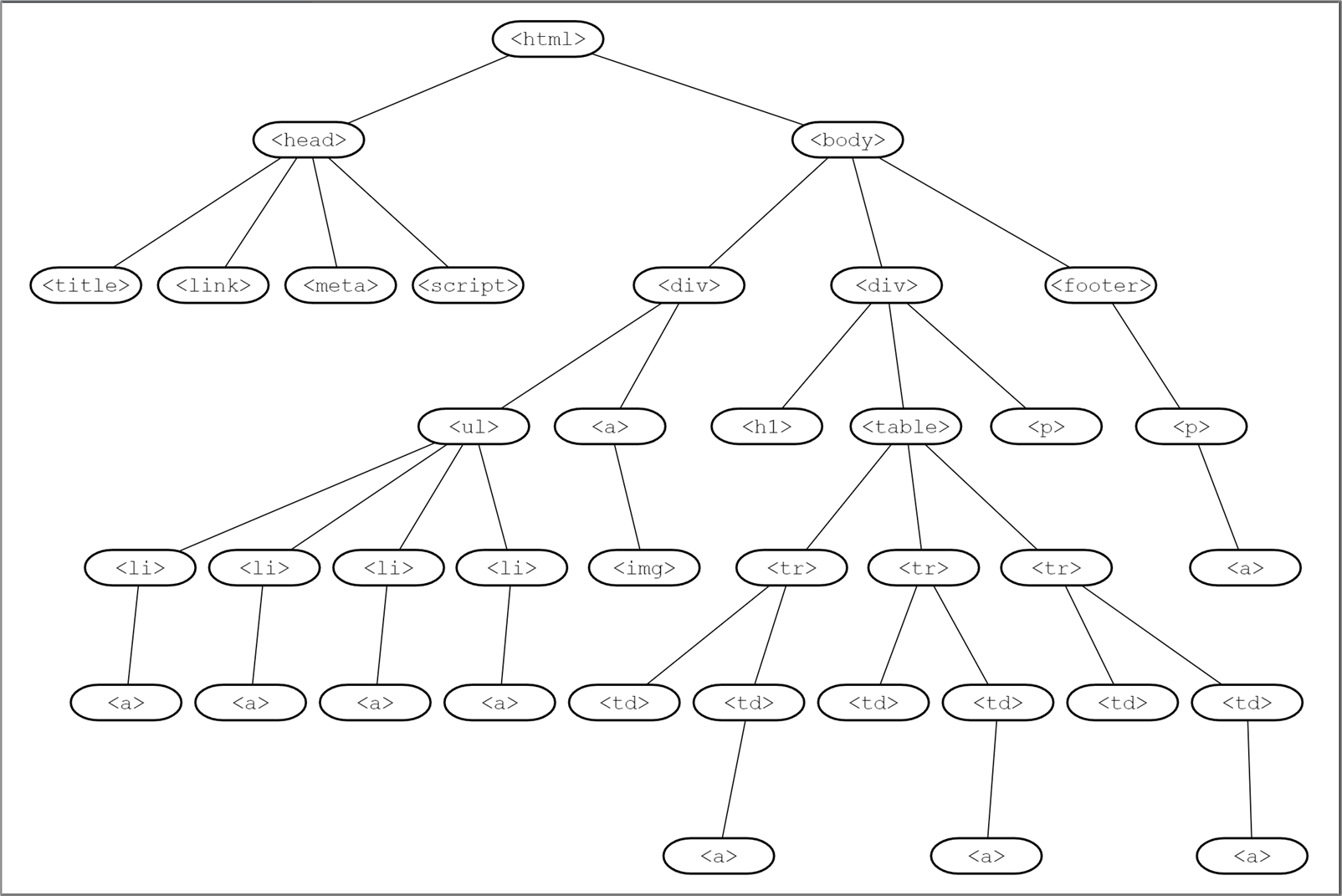
HTML 엘리먼트의 선택
-
HTML 엘리먼트
태그와 속성으로 구성된 HTML의 한 단위 혹은 특정 부분
웹스크레이핑의 타깃의 주소
HTML 엘리먼트의 선택: CSS 선택자(casading style sheet selector)
| 선택 대상 | CSS 선택자 | 결과 |
|---|---|---|
| 태그(tag) | tag1 | “tag1”이라는 이름의 모든 tag |
| 클래스(class) | .class1 | “class1”이라는 class 속성을 갖는 모든 요소 |
| 아이디(id) | #id1 | “id1”이라는 id 속성을 갖는 모든 요소 |
| tag와 class의 결합 | tag1.class1 | “tag1”이라는 tag의 “class1”이라는 class 속성을 갖는 모든 요소 |
| class1과 class2의 결합 | .class1.class2 | “class1”이라는 이름의 class 속성과 “class2”라는 이름의 class 속성을 동시에 갖는 모든 요소 |
HTML 엘리먼트의 선택
-
정확한 CSS 선택자의 확인
웹페이지에서 오른쪽 마우스 버튼을 눌러 “검사” 선택한 뒤, 탐색
브라우저 확장 프로그램의 활용: SelectGadget
rvest 패키지

단계
-
1단계: 웹페이지 읽기
- 웹스크레이핑의 대상이 되는 웹페이지의 URL 읽기
-
2단계: HTML 엘리먼트의 선택
- 필요한 정보를 포함하고 있는 엘리먼트의 특정
-
3단계: 하위 엘리먼트의 선택
- 필요한 정보를 포함하고 있는 하위 엘리먼트의 특정
-
4단계: 엘리먼트로부터 데이터를 추출
- 데이블 데이터, 텍스트 등을 추출
사례 1: 스타워즈
사례 1: 스타워즈
library(rvest)
library(tidyverse)
url <- "https://rvest.tidyverse.org/articles/starwars.html"
read_html(url) |>
html_elements("section") |>
html_element("h2") |>
html_text2()[1] "The Phantom Menace" "Attack of the Clones"
[3] "Revenge of the Sith" "A New Hope"
[5] "The Empire Strikes Back" "Return of the Jedi"
[7] "The Force Awakens" 사례 1: 스타워즈
section <- read_html(url) |>
html_elements("section")
tibble(
title = section |>
html_element("h2") |>
html_text2(),
released = section |>
html_element("p") |>
html_text2() |>
str_remove("Released: ") |>
parse_date(),
director = section |>
html_element(".director") |>
html_text2(),
intro = section |>
html_element(".crawl") |>
html_text2()
)section <- read_html(url) |>
html_elements("section")
tibble(
title = section |>
html_element("h2") |>
html_text2(),
released = section |>
html_element("p") |>
html_text2() |>
str_remove("Released: ") |>
parse_date(),
director = section |>
html_element(".director") |>
html_text2(),
intro = section |>
html_element(".crawl") |>
html_text2()
)# A tibble: 7 × 4
title released director intro
<chr> <date> <chr> <chr>
1 The Phantom Menace 1999-05-19 George Lucas "Turmoil has engulfed the…
2 Attack of the Clones 2002-05-16 George Lucas "There is unrest in the G…
3 Revenge of the Sith 2005-05-19 George Lucas "War! The Republic is cru…
4 A New Hope 1977-05-25 George Lucas "It is a period of civil …
5 The Empire Strikes Back 1980-05-17 Irvin Kershner "It is a dark time for th…
6 Return of the Jedi 1983-05-25 Richard Marquand "Luke Skywalker has retur…
7 The Force Awakens 2015-12-11 J. J. Abrams "Luke Skywalker has vanis…사례 2: 웹 상의 테이블
- 위키피디어: 전세계 국가 관련 항목
# A tibble: 240 × 7
`` Location Population `% ofworld` Date Source (official or …¹ Notes
<chr> <chr> <chr> <chr> <chr> <chr> <chr>
1 – World 8,119,000… 100% 1 Ju… UN projection[1][3] ""
2 1/2 [b] China 1,409,670… 17.3% 31 D… Official estimate[5] "[c]"
3 1/2 [b] India 1,404,910… 17.3% 1 Ju… Official projection[6] "[d]"
4 3 United Sta… 335,893,2… 4.1% 1 Ja… Official projection[7] "[e]"
5 4 Indonesia 282,477,5… 3.5% 31 J… National annual proje… ""
6 5 Pakistan 241,499,4… 3.0% 1 Ma… 2023 census result[9] "[f]"
7 6 Nigeria 223,800,0… 2.7% 1 Ju… Official projection[1… ""
8 7 Brazil 203,080,7… 2.5% 1 Au… 2022 census result[11] ""
9 8 Bangladesh 169,828,9… 2.1% 14 J… 2022 census result[12] ""
10 9 Russia 146,150,7… 1.8% 1 Ja… Official estimate[13] "[g]"
# ℹ 230 more rows
# ℹ abbreviated name: ¹`Source (official or fromthe United Nations)`my_table_new <- my_table |>
select(-1, -7) |>
rename(
location = "Location",
population = "Population",
pop_pct = "% ofworld",
date = "Date",
source = "Source (official or fromthe United Nations)"
) |>
mutate(
population = parse_number(population, ","),
population = as.numeric(population),
pop_pct = str_remove_all(pop_pct, "%"),
pop_pct = as.numeric(pop_pct),
date = dmy(date)
)# A tibble: 240 × 5
location population pop_pct date source
<chr> <dbl> <dbl> <date> <chr>
1 World 8119000000 100 2024-07-01 UN projection[1][3]
2 China 1409670000 17.3 2023-12-31 Official estimate[5]
3 India 1404910000 17.3 2024-07-01 Official projection[6]
4 United States 335893238 4.1 2024-01-01 Official projection[7]
5 Indonesia 282477584 3.5 NA National annual projection[8]
6 Pakistan 241499431 3 2023-03-01 2023 census result[9]
7 Nigeria 223800000 2.7 2023-07-01 Official projection[10]
8 Brazil 203080756 2.5 2022-08-01 2022 census result[11]
9 Bangladesh 169828911 2.1 2022-06-14 2022 census result[12]
10 Russia 146150789 1.8 2024-01-01 Official estimate[13]
# ℹ 230 more rows데이터 수집하기: API의 활용
정의
-
API(application programming interface)는 일종의 통신 규약(protocol)
복수의 프로그램들이 서로 상호작용하는 방법을 정의하는 일련의 규칙
한 애플리케이션이 다른 애플리케이션의 기능들을 불러 사용할 수 있게 해주는 통로
오픈 API: API 키(key)
-
데이터 API
- 데이터를 보유하고 있는 공적 기관이 데이터의 사용 권한을 사용자들에게 부여함으로써 데이터에 대한 접근성을 높여주는 일련의 방식
API 활용의 다양성
-
정형 수치 데이터의 수집
KOSIS의 API를 활용한 센서스 데이터 수집
공공데이터포털 API를 활용한 지역별 미세먼지 농도 데이터 수집
International Database(IDB)의 API를 활용한 세계 인구 데이터 수집
-
정형 텍스트 데이터 수집
- 공공데이터포털 API를 활용한 학위 논문 수집
-
비정형 텍스트 데이터 수집: 텍스트 마이닝(text mining)으로 연결
네이버 검색 API를 활용한 뉴스 데이터 수집
유튜브 API를 활용한 댓글 데이터 수집
API 활용의 다양성
Google Maps Platform (https://mapsplatform.google.com/)
-
7 종류의 API
Google Direction API
Google Distance API
Google Elevation API
Google Timezone API
Google Geocode API
Google Reverse Geocode API
Google Places API
R 래퍼(rapper) 패키지: googleway
NAVER 뉴스 데이터
NAVER Developer(https://developers.naver.com/)
-
기본 내용 숙지: Document > API 공통 가이드
-
비로그인 방식 오픈 API: ’검색’ 카테고리 > 뉴스 선택
요청 URL: https://openapi.naver.com/v1/search/news.json
파라미터: query, display, start, sort
-
-
오픈 API 신청: Application > 애플리케이션 등록
-
절차
애플리케이션 이름: 아무 이름이나 입력
사용 API: ‘검색’ 선택
비로그인 오픈 API 서비스 환경: ’WEB 설정’을 선택
웹 서비스 URL (최대 10개): ’http://localhost’를 입력
ClientID와 Client Secret 획득
-
httr2 패키지

‘지방소멸’ 뉴스 검색 데이터 수집
library(httr2)
search <- "지방소멸"
base_url <- "https://openapi.naver.com/v1/search/news.json"
result_naver <- request(base_url) |>
req_headers(
"X-Naver-Client-ID" = your_ClientID,
"X-Naver-Client-Secret" = your_Client_Secret
) |>
req_url_query(
query = search,
display = 100,
start = 1,
sort = "date"
) |>
req_perform() |>
resp_body_json()
naver_tb <- tibble(naver = result_naver$items)
naver_res <- naver_tb |>
unnest_wider(naver)
naver_res |> slice_head(n = 10)library(httr2)
search <- "지방소멸"
your_url <- "https://openapi.naver.com/v1/search/news.json"
result_naver <- request(your_url) |>
req_headers(
"X-Naver-Client-ID" = your_ClientID,
"X-Naver-Client-Secret" = your_Client_Secret
) |>
req_url_query(
query = search,
display = 100,
start = 1,
sort = "date"
) |>
req_perform() |>
resp_body_json()
naver_tb <- tibble(naver = result_naver$items)
naver_res <- naver_tb |>
unnest_wider(naver)
naver_res |> slice_head(n = 10)# A tibble: 10 × 5
title originallink link description pubDate
<chr> <chr> <chr> <chr> <chr>
1 이춘석 의원, 국정감사에서 尹정부 '말… http://www.… http… "이춘석 국… Sun, 2…
2 충남 아산, 충남 유일한 '청년인구' 증… https://www… http… "저출생·… Sun, 2…
3 산촌의 숲 활용 돌봄·치유·지역<b>소… http://www.… http… "이어 횡성… Sun, 2…
4 (대구경북특별시) (1) 통합 칼자루 쥔 … https://www… http… "안동 출신… Sun, 2…
5 서울대 ‘지역비례’ 선발 땐 부울경 대… http://www.… http… "심각하고 … Sun, 2…
6 박정현 의원 “지역사랑상품권법 개정안… https://cc.… http… "이어 박 … Sun, 2…
7 장수사과, 세계 무대에 빛나다 http://sjbn… http… "장수군과 … Sun, 2…
8 전주청소년센터·농협전주시지부, 아침… http://sjbn… http… "이날 양 … Sun, 2…
9 지역화폐 발행-고교 무상교육 '국비지원… http://sjbn… http… "이들은 공… Sun, 2…
10 "맛과 영양까지" 익산 돌봄교… http://sjbn… http… "'방학 중 … Sun, 2…텍스트 마이닝과 자연어처리
-
텍스트 마이닝
비정형 텍스트 데이터로부터 패턴 또는 관계를 추출하여 의미 있는 정보를 찾아내는 기법
기본 과정: 텍스트 전처리, 토큰화하기, 단어 빈도 분석하기
고급 분석: 비교 분석, 감정 분석, 의미망 분석, 토픽 모델링 등
-
자연어처리(NLP; natural language processing)
-
KoNLP(Korean Natural Language Processing)
-
KOSIS
-
KOSIS 공유서비스 홈페이지(https://kosis.kr/openapi/)
- 상세한 개발 가이드
-
래퍼 패키지
주석훈(Seokhoon Joo)
-
함수
getStatData()getStatDataFromURL()
API를 통한 생성형 AI와의 커뮤니케이션
-
OpenAI, Google Generative AI, Moonshot AI 등 다양한 생성형 AI와 API를 통한 상호작용 가능
- 래퍼 패키지: GenAI(https://genai.gd.edu.kg/)

데이터 불러오기
readr 패키지

readr 패키지: 주요 함수
| Names | Formats |
|---|---|
read_csv() |
콤마분리(comma-separated values, CSV) 형식 |
read_csv2() |
세미콜론분리(semicolon-separated) 형식 |
read_tsv() |
탭구분(tab-limited) 형식 |
read_delim() |
여타의 구분 형식 |
read_fwf() |
고정폭(fixed-width) 형식 |
read_table() |
공백구분 형식 |
read_log() |
아파치 형식(Apache-style)의 로그 파일 |
readr 패키지: read_csv()의 주요 아규먼트
컬럼명(변수명):
col_names-
컬럼의 데이터 유형:
col_types = cols()col_double()col_integer()col_character()col_logical()
관련 패키지



-
readxl패키지:read_xls(), read_xlsx(), read_excel()
웹데이터 불러오기: readr 패키지
# A tibble: 6 × 5
`Student ID` `Full Name` favourite.food mealPlan AGE
<dbl> <chr> <chr> <chr> <chr>
1 1 Sunil Huffmann Strawberry yoghurt Lunch only 4
2 2 Barclay Lynn French fries Lunch only 5
3 3 Jayendra Lyne N/A Breakfast and lunch 7
4 4 Leon Rossini Anchovies Lunch only <NA>
5 5 Chidiegwu Dunkel Pizza Breakfast and lunch five
6 6 Güvenç Attila Ice cream Lunch only 6 웹데이터 불러오기: openxlsx 패키지
Var1 Var2 Var3 Var4 Var5 Var6 Var7
1 TRUE 1 1.00 a 42042 3209324 This NA
2 TRUE NA NA b 42041 <NA> NA
3 TRUE 2 1.34 c 42040 <NA> NA
4 FALSE 2 NA <NA> NA <NA> NA
5 FALSE 3 1.56 e NA <NA> NA
6 FALSE 1 1.70 f 42037 <NA> NA
7 NA NA NA <NA> 42036 <NA> NA
8 FALSE 2 23.00 h 42035 <NA> NA
9 FALSE 3 67.30 i 42034 <NA> NA
10 NA 1 123.00 <NA> 42033 <NA> NA웹데이터 불러오기: googlesheet4 패키지
library(googlesheets4)
gs4_deauth()
read_sheet("https://docs.google.com/spreadsheets/d/1U6Cf_qEOhiR9AZqTqS3mbMF3zt2db48ZP5v3rkrAEJY/edit#gid=780868077")# A tibble: 624 × 6
country continent year lifeExp pop gdpPercap
<chr> <chr> <dbl> <dbl> <dbl> <dbl>
1 Algeria Africa 1952 43.1 9279525 2449.
2 Algeria Africa 1957 45.7 10270856 3014.
3 Algeria Africa 1962 48.3 11000948 2551.
4 Algeria Africa 1967 51.4 12760499 3247.
5 Algeria Africa 1972 54.5 14760787 4183.
6 Algeria Africa 1977 58.0 17152804 4910.
7 Algeria Africa 1982 61.4 20033753 5745.
8 Algeria Africa 1987 65.8 23254956 5681.
9 Algeria Africa 1992 67.7 26298373 5023.
10 Algeria Africa 1997 69.2 29072015 4797.
# ℹ 614 more rows데이터 정리하기
테이블 데이터: 데이터 프레임
| 변수 1 | 변수 2 | 변수 3 | … | 변수 K | |
|---|---|---|---|---|---|
| 관측개체 1 | |||||
| 관측개체 2 | |||||
| 관측개체 3 | |||||
| 관측개체 4 | |||||
| … | |||||
| 관측개체 n |
데이터 유형
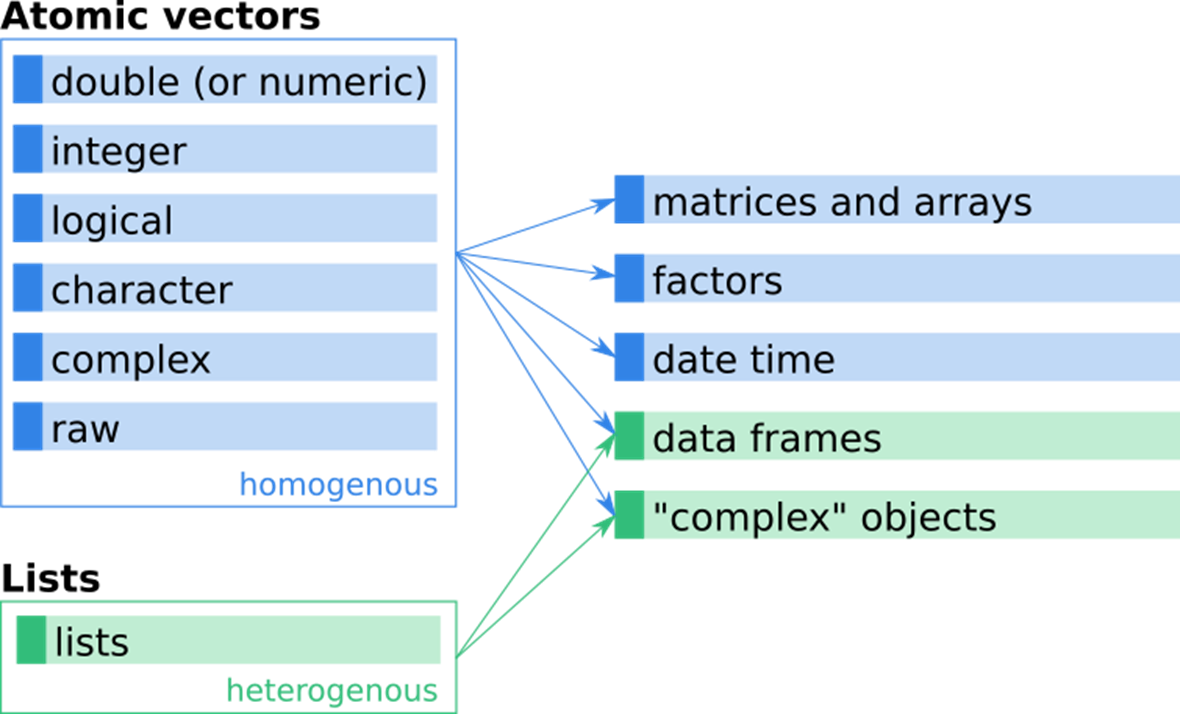
벡터와 데이터 프레임
tibble 패키지

data.frame 객체 vs. tibble 객체
data.frame 객체: Base R의 공식적 데이터 프레임 객체
tibble 객체:
tidyverse의 공식적 데이터 프레임 객체
tidyr package

타이디(tidy) 데이터의 개념
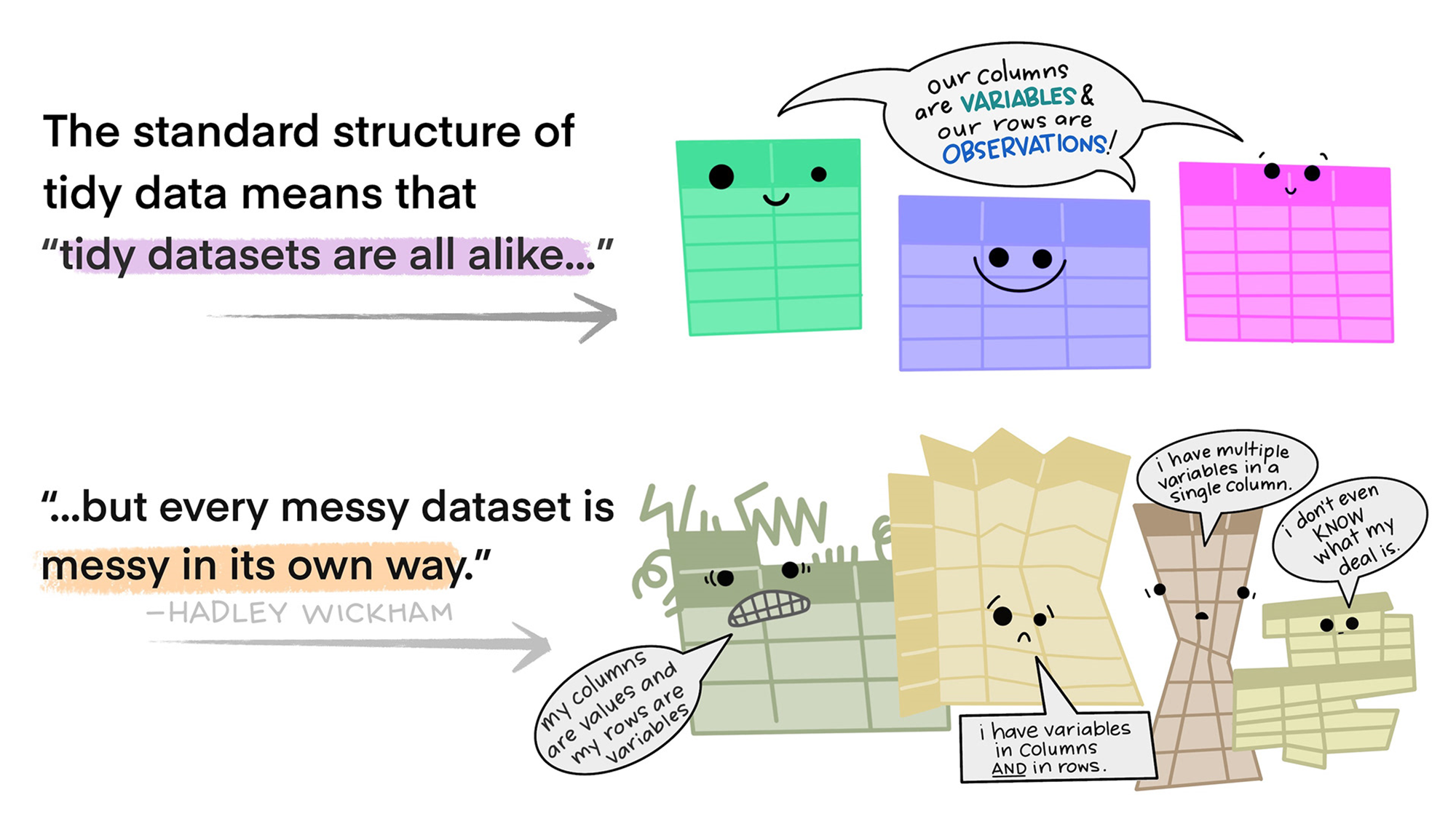
타이디(tidy) 데이터의 개념

타이디(tidy) 데이터의 개념
개별 변수(variable)는 열(column) 하나를 차지한다. 즉, 개별 열에는 하나의 변수가 위치한다.
개별 관측개체(observation)는 하나의 행(row)을 차지한다. 즉, 개별 행에는 하나의 관측개체가 위치한다.
개별 값(value)은 하나의 셀(cell)을 차지한다. 즉, 개별 셀에는 하나의 값이 위치한다.
예시: table1
예시: table2
# A tibble: 12 × 4
country year type count
<chr> <dbl> <chr> <dbl>
1 Afghanistan 1999 cases 745
2 Afghanistan 1999 population 19987071
3 Afghanistan 2000 cases 2666
4 Afghanistan 2000 population 20595360
5 Brazil 1999 cases 37737
6 Brazil 1999 population 172006362
7 Brazil 2000 cases 80488
8 Brazil 2000 population 174504898
9 China 1999 cases 212258
10 China 1999 population 1272915272
11 China 2000 cases 213766
12 China 2000 population 1280428583예시: table3
타이디(tidy) 데이터의 장점
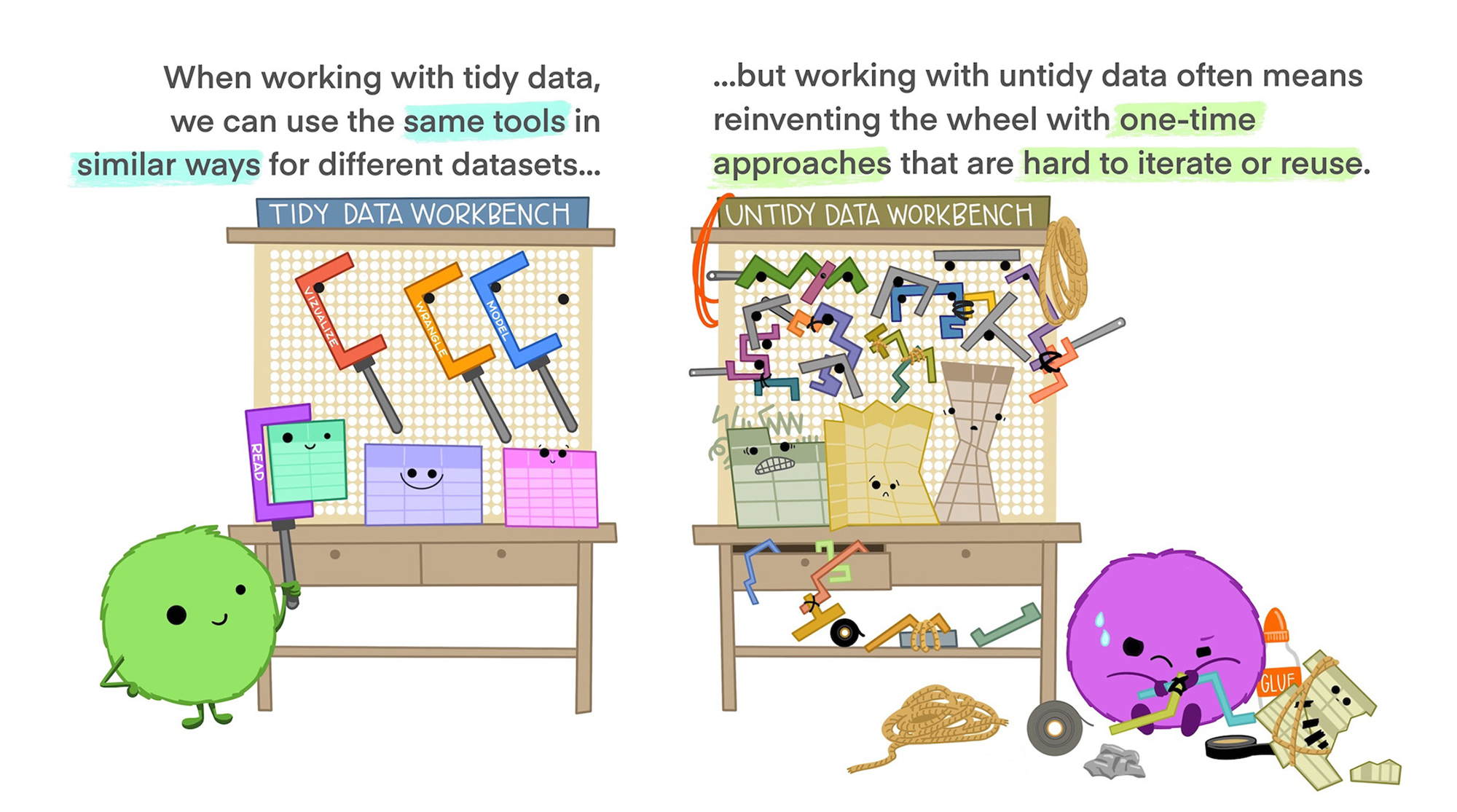
데이터의 구조를 바꾸는 핵심 기법
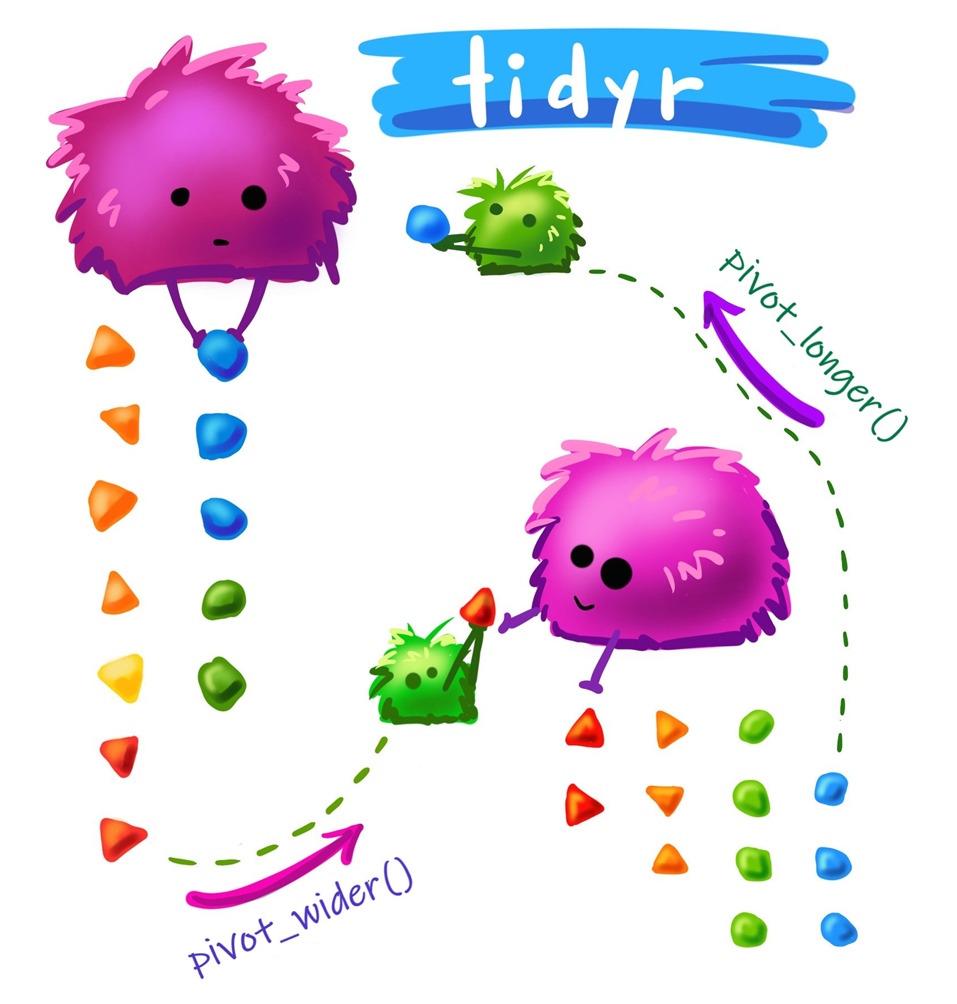
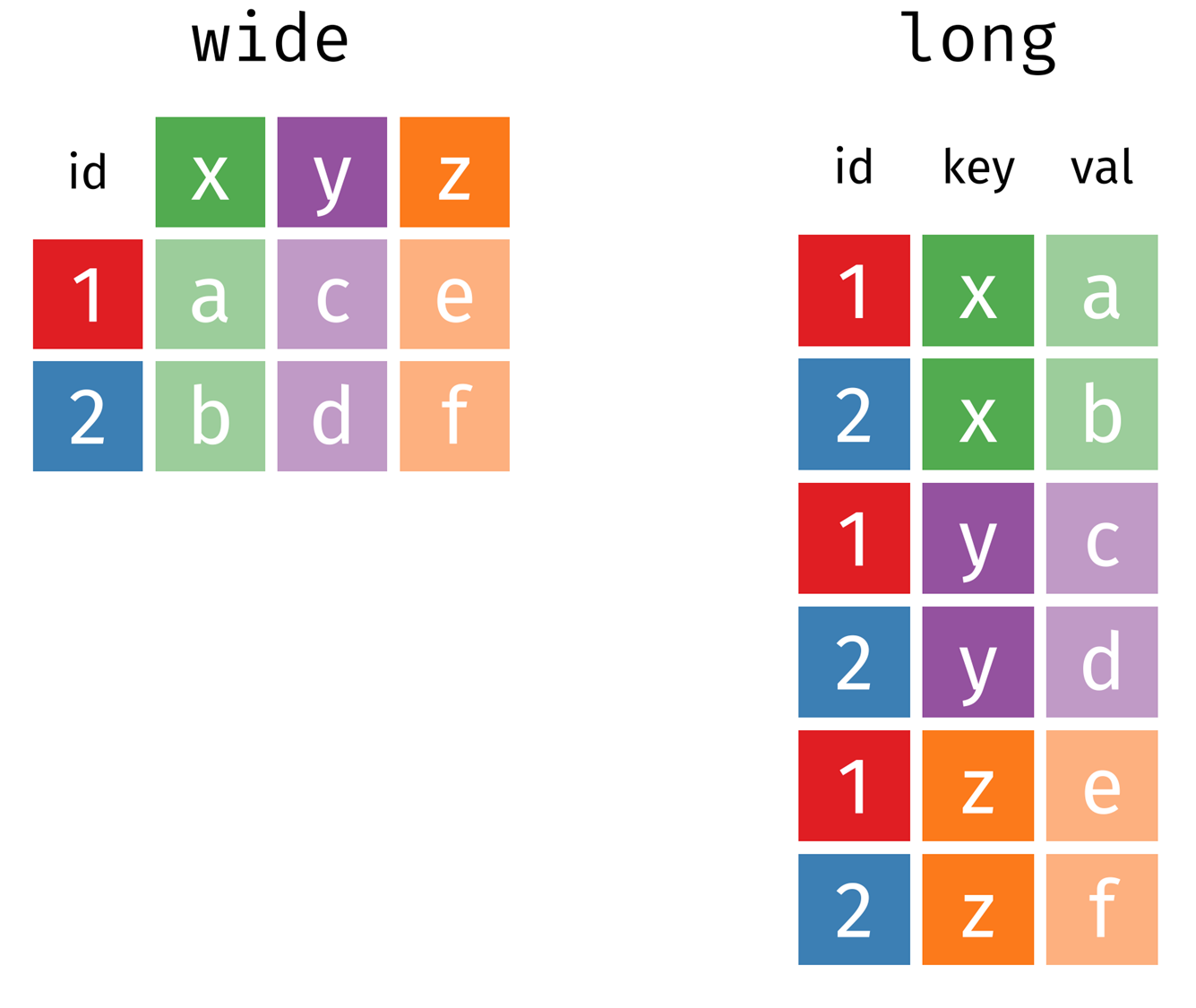
넓은 형식 wide form vs. 긴 형식 long form
데이터 늘이기 Lengthening data
데이터 늘이기 Lengthening data

데이터 넓히기 Widening data
# A tibble: 12 × 4
country year type count
<chr> <dbl> <chr> <dbl>
1 Afghanistan 1999 cases 745
2 Afghanistan 1999 population 19987071
3 Afghanistan 2000 cases 2666
4 Afghanistan 2000 population 20595360
5 Brazil 1999 cases 37737
6 Brazil 1999 population 172006362
7 Brazil 2000 cases 80488
8 Brazil 2000 population 174504898
9 China 1999 cases 212258
10 China 1999 population 1272915272
11 China 2000 cases 213766
12 China 2000 population 1280428583# A tibble: 6 × 4
country year cases population
<chr> <dbl> <dbl> <dbl>
1 Afghanistan 1999 745 19987071
2 Afghanistan 2000 2666 20595360
3 Brazil 1999 37737 172006362
4 Brazil 2000 80488 174504898
5 China 1999 212258 1272915272
6 China 2000 213766 1280428583데이터 넓히기 Widening data

데이터 늘이기 Lengthening data
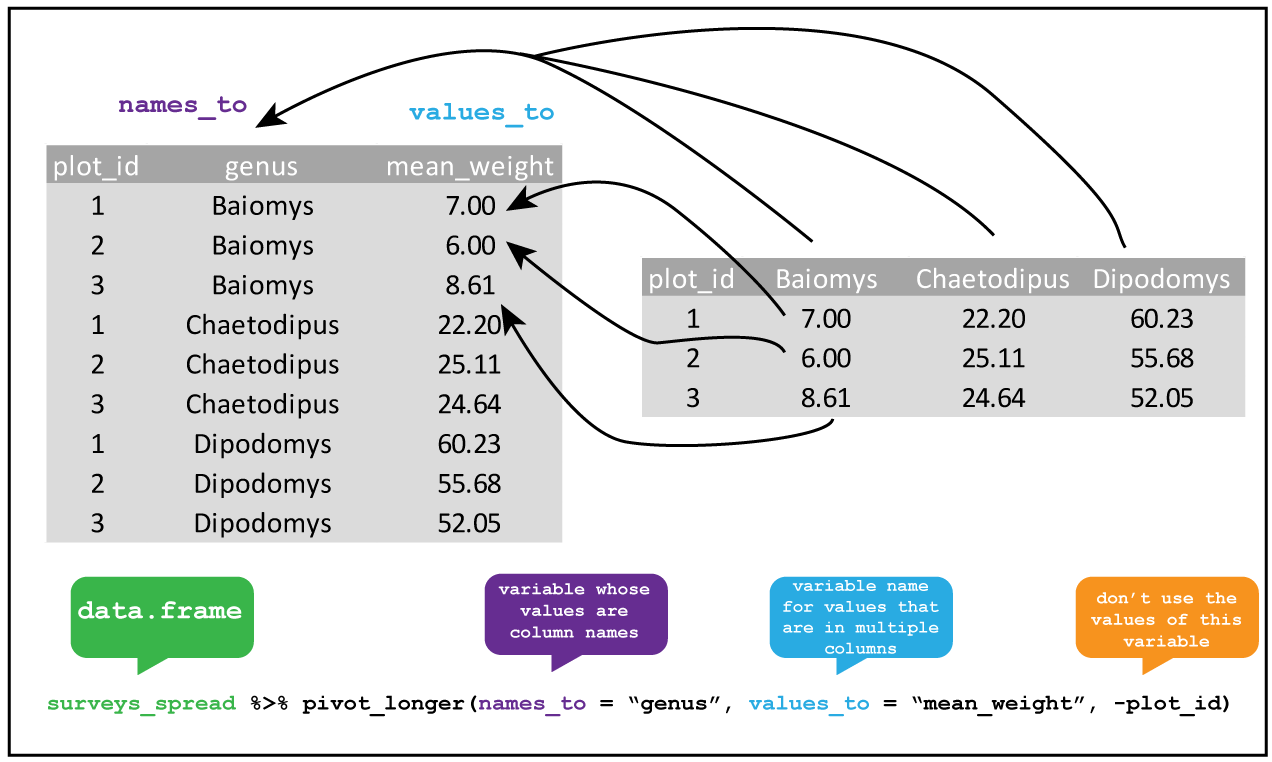
https://ab604.github.io/docs/coding-together-2019/data-wrangle-2.html
데이터 넓히기 Widening data

https://ab604.github.io/docs/coding-together-2019/data-wrangle-2.html
데이터 결합하기: dplyr 패키지

조인의 개념
-
두 개의 데이터 프레임을 공통키(common key)를 활용하여 하나의 데이터 프레임으로 결합(join)하는 과정
- 공통키: 두 개의 데이터 프레임에 공통적으로 포함되어 있는 식별자(identifier)
-
대응행(match row)과 비대응행(non-match row)
대응행: 동일한 공통키 값을 가진 두 데이터 프레임의 행
비대응행: 한 데이터 프레임에만 존재하는 공통키 값을 가진 행
-
조인의 결과
일반적으로 열(변수)이 늘어나므로 데이터는 넓어짐
행은 조인의 방식에 따라 변화가 없을 수도 있고, 짧아질수도 있고, 길어질 수도 있음
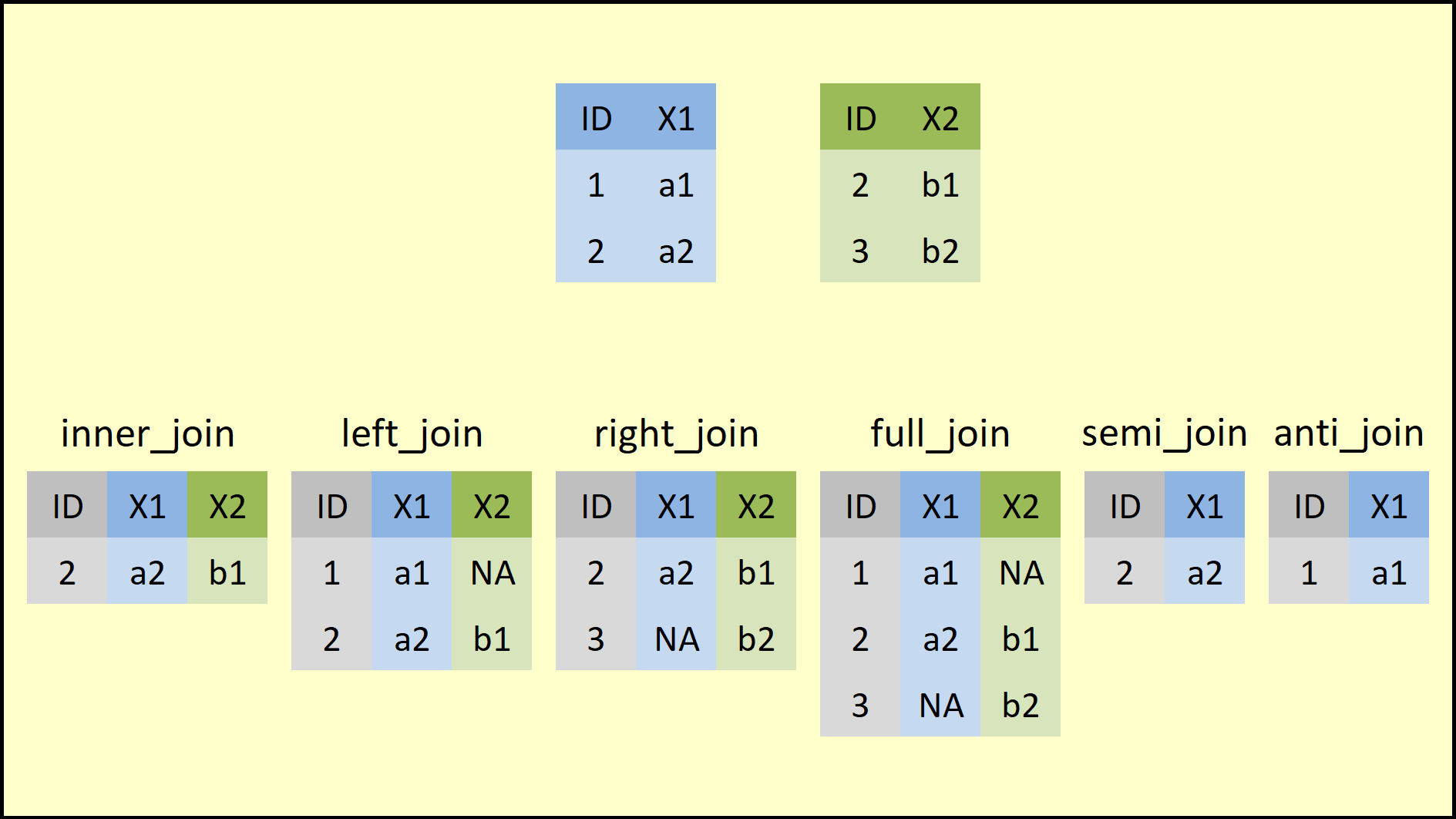
조인의 유형
inner_join(): 대응행만으로 결합
full_join(): 대응행과 비대응행 모두를 결합
left_join(): 첫 번째 변수는 그대로 둔 상태에서 두 번째 변수의 대응행만 결합
right_join(): 두 번째 변수는 그대로 둔 상태에서 첫 번째 변수의 대응행만 결합
semi_join(): 첫 번째 변수의 대응행만 취함(실질적으로는 조인이 아님)
anti_join(): 첫 번째 변수의 비대응행만 취함(실질적으로는 조인이 아님)
조인의 유형
![]()
사회과 예비교사를 위한 AIㆍ디지털 역량강화 워크숍